Управление событиями и инцидентами в рамках эксплуатации услуг. Основные понятия управления инцидентами
Процессы управления инцидентами и управления проблемами во многом похожи, но имеют и существенные различия. Опишем каждый из процессов по отдельности, а затем сравним их с различных точек зрения, обсудив способы реализации.
Управление инцидентами
Основная цель процесса управления инцидентами (incident management) - восстановление нормальной работоспособности системы в максимально короткие сроки и минимизация отрицательного влияния на бизнес, пользующийся службами, работоспособность которых оказалась нарушенной . Под «нормальным функционированием служб» понимается функционирование, соответствующее зафиксированному в соглашении об уровне обслуживания (service level agreement,SLA ).
К инцидентам не могут быть отнесены события, не касающиеся качества предоставляемых ИТ-услуг, а также те, которые, снижая это качество, не выходят за оговоренные в SLA рамки. Особое место занимают случаи, когда клиент не ощутил на себе наличия инцидента (скажем, если все необходимые меры были приняты в автоматическом режиме или обслуживающим персоналом еще до того, как качество реально снизилось). Примеры: автоматическое архивирование данных и освобождение рабочего диска при приближении к моменту его переполнения; переход на резервный сервер при сбоях основного и т.д. Тем не менее, такие случаи не могут быть исключены из списка инцидентов. Правильная организация требует отработки и таких инцидентов в соответствии с полной процедурой (т.е. с последующим отображением в отчетах и принятием необходимых мер по их предотвращению в будущем).
Всякому процессу управления инцидентами можно дать формальное краткое описание путем перечисления набора характеристик.
Входными данными для описания инцидентов служат:
- детальное описание инцидента, полученное от Service Desk, служб обеспечения оперативного функционирования сетей или серверов и т.д.;
- описание конфигураций и элементов, возможно связанных с инцидентом. Описания берутся из CMDB, базы данных единиц конфигурации, к которым относятся все элементы ИТ-инфраструктуры (оборудование, программное обеспечение, документация, предоставляемые службы и т.д.);
- информация (при ее наличии) из базы проблем и базы известных ошибок;
- описание способа разрешения.
Результат процесса управления инцидентами может быть следующим:
- запрос на временное внесение изменений для устранения инцидента, обновленная регистрационная запись инцидента, включающая способ разрешения и/или обхода;
- разрешенный (устраненный) и закрытый инцидент;
- сообщение для клиента;
- управленческая информация (отчет).
Возможные мероприятия по управлению инцидентами:
- определение и регистрация инцидента;
- классификация инцидента и начальная помощь;
- исследование и диагностика;
- разрешение инцидента и восстановление системы;
- закрытие инцидента;
- собственность, мониторинг, отслеживание и взаимодействие.
Роли и функции управления инцидентами:
- группы поддержки первой, второй и третьей линий, а также группы специалистов и внешние партнеры (роли); менеджер управления инцидентами (роль); менеджер Service Desk (функция).
Возможные метрики:
- общее число инцидентов;
- среднее время устранения или обхода инцидента по различным типам инцидентов;
- процент инцидентов, устраненных за время, не превышающее оговоренного в SLA;
- средняя стоимость устранения инцидента;
- процент инцидентов, закрытых без привлечения иных специалистов;
- число и процент инцидентов, устраненных удаленно (без визита к пользователю).
В целях обеспечения соблюдения временных рамок, выделенных для выполнения тех или иных действий, применяется функциональная и иерархическая эскалация. Под «эскалацией» понимается организационный механизм, помогающий контролировать время устранения инцидента; он должен использоваться при реализации всех мероприятий в процессе разрешения инцидента. Его суть состоит в необходимости либо обязательной передачи информации об инциденте более квалифицированным специалистам, либо информировании руководства о невозможности устранить инцидент в оговоренные сроки.
Передача инцидента от Service Desk на вторую линию поддержки (функциональная эскалация) требуется при невозможности устранить инцидент на первой линии. Автоматизированная функциональная эскалация возможна, но должна быть тщательно спланирована в соответствии с SLA.
Иерархическая эскалация оказывается необходимой при невозможности устранения инцидента либо за выделенное время, либо с необходимым качеством. Как правило, она осуществляется персоналом службы Service Desk в соответствии с их опытом и вручную. Автоматизированная иерархическая эскалация тоже используется и может строиться на основе учета временных интервалов. Целесообразно чтобы она осуществлялась до времени, установленного в SLA; при этом соответствующий руководитель получит возможность предпринять дополнительные действия.
Эффект от внедрения процесса управления инцидентами
Перечислим наиболее важные полезные качества, которые приобретаются в результате внедрения процесса управления инцидентами. Для бизнеса в целом это:
- снижение отрицательного воздействия на бизнес со стороны инцидентов, достигаемое повышением эффективности и сокращении времени при их устранении;
- проактивное (упреждающее) определение необходимости расширения и коррекции важных для бизнеса систем;
- доступность необходимой для бизнеса управленческой информации, соотнесенной с условиями SLA.
Ряд полезных качеств приобретает и работа ИТ-подразделения:
- усовершенствованный мониторинг, позволяющий измерить производительность в соответствии с SLA;
- улучшенная информация для управления качеством обслуживания;
- более оптимальная загрузка персонала и более эффективная его работа;
- исключение потерь и некорректного учета инцидентов и запросов;
- более точное ведение базы данных единиц конфигурации CMDB;
- лучшее удовлетворение потребностей клиентов.
Работа же без системы управления инцидентами может обернуться рядом неприятностей. Отсутствие лиц, ответственных за устранение и эскалацию инцидентов, приводит к путанице при устранении сбоев и снижает качество обслуживания. Специалисты службы поддержки отвлекаются от исполнения своих обязанностей, что снижает эффективность их труда. Пользователи для устранения инцидентов и проблем вынуждены общаться друг с другом, отвлекаясь от основных обязанностей. Всякий раз приходится заново анализировать инциденты - даже те, которые происходят регулярно и должны быть известны.
Управление проблемами
Основная цель процесса управления проблемами - минимизация неблагоприятного влияния на основную деятельность организации инцидентов и проблем, возникающих в результате ошибок в ИТ-инфраструктуре, а также предотвращение повторного возникновения инцидентов, связанных с этими ошибками. Для этого осуществляется поиск и выяснение причин инцидентов, и осуществляются действия, направленные на улучшение ситуации или устранение выявленных причин.
Процесс управления проблемами носит как реактивный, так и проактивный характер. Первый вариант касается разрешения проблем, связанных с возникшими инцидентами, второй направлен на выявление и устранение проблем, способных привести, но пока не приведших к возникновению инцидентов.
Контроль проблем и ошибок вместе с проактивным управлением проблемами составляют сферу ответственности процесса управления проблемами. На языке формальных определений, «проблема» - это неизвестная основная причина возникновения одного или нескольких инцидентов, а «известная ошибка» - успешно диагностированная проблема, для которой найден обходной путь или способ устранения.
Как и для процесса управления инцидентами, приведем группы основных характеристик процесса управления проблемами. Хотя некоторые из них и совпадают, указать их все имеет смысл, поскольку речь идет о разных процессах.
Входными данными для описания служат:
- детали инцидента, заимствованные из управления инцидентами;
- детальное описание конфигураций из CMDB;
- все известные обходные пути (из управления инцидентами).
Возможные мероприятия:
- контроль проблем и ошибок;
- проактивное предотвращение проблем;
- идентификация трендов;
- анализ накапливаемой информации и подготовка отчетов;
- подготовка управленческой информации.
Результаты могут быть следующими:
- описание новых известных ошибок;
- запросы на внесение изменений;
- обновленная регистрационная запись проблемы, включающая вариант решения проблемы и/или любой доступный обходной путь;
- для разрешенных проблем закрытая регистрационная запись проблемы;
- поиск аналогов инцидента среди известных ошибок и рассматриваемых проблем;
- управленческая информация.
Роли и функции: сотрудники, ответственные за обработку проблем (роли); менеджер управления проблемами (роль).
Возможные метрики:
- число инициированных запросов на внесение изменений, а также влияние этих запросов на надежность и доступность охваченных ими служб;
- время, затраченное на работы по исследованию и диагностике на каждое подразделение, с учетом деления на типы проблем;
- число и влияние возникших инцидентов до выявления причины проблемы или до регистрации известной ошибки;
- отношение объема усилий по немедленной помощи и поддержке к плановому;
- число проблем и ошибок, сгруппированных по различным признакам (статус, службы, влияние, категории, пользовательские группы);
- среднее и максимальное время, расходуемое на закрытие проблемы или согласование известной ошибки, рассчитываемое с момента регистрации проблемы, сгруппированное по кодам влияния и группам поддержки;
- ожидаемое время устранения открытых проблем;
- общее затраченное время на все закрытые проблемы.
Эффект от внедрения процесса управления проблемами
Перечислим наиболее важные полезные качества, которые приобретаются в результате внедрения процесса управления проблемами.
- Качество служб. Управление проблемами помогает поддерживать непрерывный цикл постоянного повышения качества ИТ-служб.
- Сокращение числа инцидентов. Процесс управления проблемами является инструментом для сокращения числа возникающих инцидентов, отрицательно влияющих на бизнес организации.
- Непрерывное решение. В результате работы процесса сокращается число и влияние на бизнес уже решенных проблем и известных ошибок.
- Усовершенствованное обучение. Процесс основывается на концепции использования накопленных знаний из прошлого и предоставляет возможности для анализа трендов и предотвращения сбоев, либо снижения их значимости и влияния на основной бизнес.
- Увеличение числа инцидентов, разрешаемых при первом обращении. Это достигается путем предоставления в распоряжение Service Desk рекомендаций по путям предотвращения и обхода возникающих инцидентов.
В свою очередь, отказ от реализации процесса сулит ряд неприятностей. Действующая исключительно «по факту» служба поддержки начинает действовать только тогда, когда услуга уже не доступна. Складывается инфраструктура, предполагающая применение пользователями ИТ-средств самостоятельно. Неэффективная, дорогая и слабо мотивированная служба поддержки многократно решает одни и те же проблемы, никак не учитывая предыдущий опыт.
Реализация и внедрение
Мы уже обращали внимание на основное отличие рассматриваемых процессов, учтенное в формировании ключевых метрик качества. Задачей управления инцидентами является устранение инцидентов в максимально короткие сроки. Управление же проблемами должно исключить возможность повторного возникновения инцидента по той же самой (а иногда - и по аналогичным) причинам.
В организационном плане это означает, что никто не может исполнять обязанности по обоим этим процессам одновременно, поскольку он был бы не в состоянии правильно расставить приоритеты. В качестве выхода из положения при традиционной ограниченности штата рекомендуется четко определить в инструкциях временные или иные рамки, позволяющие специалисту однозначно исполнять роль только в одном из процессов. Например, сотрудник службы эксплуатации сетей банка в критичное для работоспособности время прохождения основных платежей обязан при возникновении сбоев предпринять все меры по максимально быстрому устранению этих сбоев и восстановлению работоспособности систем, исполняя роль специалиста по управлению инцидентами. В относительно менее критичное время этому специалисту запрещается реагировать на возникающие инциденты и предписывается заниматься анализом накопленной информации о сбоях и поиском их причин и, тем самым исполнять мероприятия по управлению проблемами.
Допустимо (и рекомендуется) совмещение функций Service Desk и функций управления инцидентами. Однако важно помнить, что это разные процессы: первичное общение с пользователями не входит в функции процесса управления инцидентами. К тому же, пользователь может обратиться в службу поддержки не только в связи с возникшим инцидентом, но и по иной причине (потребность в информации, необходимость пополнения расходуемых материалов и т.д.). С другой стороны, при некоторых способах реализации (например, в случае построения службы поддержки на основе Web-технологий, когда пользователь самостоятельно вносит все необходимые данные в формы) необходимость выделенной службы Service Desk оказывается под вопросом. В то же время ни в коем случае нельзя отказываться от управления инцидентами - откуда бы ни поступило сообщение об их возникновении, кто-то обязательно должен отвечать за их устранение.
Понятно, что реализация управления проблемами при отсутствии управления инцидентами практически невозможна: основой и источником данных для рассмотрения проблемы является информация, накапливаемая в ходе анализа и обработки инцидентов. Порой оказывается допустимым внедрение только управления инцидентами. Обычно управление проблемами отсутствует у фирм-посредников - имея свою собственную диспетчерскую службу, такие компании организуют прием и регистрацию обращений клиентов, помогают им при наличии возможности устранить инцидент при помощи консультации, передают более сложные заявки субподрядчикам и контролируют их действия, реализуя тем самым управление инцидентами. В то же время, они не занимаются анализом проблем, поскольку не являются собственно эксплуатирующей организацией. Часто исключают управление проблемами и в случае, если нет возможности или желания этим заниматься. В отдельных случаях даже рекомендуется для анализа проблем привлекать внешних специалистов, поскольку для этого требуется очень высокая квалификация, а также дорогостоящее оборудование. Примером могут служить традиционные обращения в компании, специализирующиеся на построении и обслуживании телекоммуникаций, для определения реальной загрузки сетей передачи данных: соответствующее оборудование стоит дорого, а необходимость его использования возникает чрезвычайно редко.
В отношении средств автоматизации ITIL рекомендует, как минимум, наличие возможностей глубокой интеграции между инструментарием для управления проблемами и инцидентами. Действительно, при анализе проблем важно иметь возможность рассмотрения всех зарегистрированных инцидентов с различных точек зрения. В свою очередь, для более эффективного общения с пользователями при возникновении новых инцидентов, соответствующим специалистам необходим доступ к находящимся в рассмотрении или уже закрытым проблемам и известным ошибкам.
Это легко понять на примере следующей ситуации. Пользователь обращается в службу поддержки с сообщением о резком увеличении времени отклика от сервера. Оператор, просматривая список анализируемых проблем, находит запись о выполнении работ по анализу снижения производительности сервера, после чего сообщает пользователю, что его сообщение зарегистрировано и связано с рассматриваемой проблемой, а устранение ожидается через такое-то время, о чем пользователю будет сообщено дополнительно. При отсутствии возможности просмотра списка проблем, оператор не мог бы связать инцидент с конкретно анализируемой проблемой, в дальнейшем быстро отследить факт его устранения и сообщить об этом пользователю.
Производители инструментария стараются учитывать упомянутые рекомендации. Например, HP OpenView Service Desk 3.0 имеет модульную структуру. В виде отдельного модуля реализованы возможности регистрации и управления обращений пользователей, инцидентов и проблем, что вполне соответствует упомянутым рекомендациям: интеграция в данном случая является максимально полной. Пользователи системы, построенной на основе этого продукта, имеют возможность строить связи между регистрационными записями всех перечисленных типов, осуществлять поиск по контексту и с учетом этих связей, определять известные способы решения проявляющихся неисправностей. Разделение этих функций может снизить эффективность работы инструментального средства, а как следствие - и качество реализации процессов. В то же время, в основе всякого решения по управлению ИТ-инфраструктурой лежит учет имеющегося оборудования, приложений, документации и т.д. - всего того, что и составляет эту инфраструктуру. Такие возможности также доступны в рамках HP Service Desk 3.0. Кроме того, в виде отдельных модулей реализованы возможности, предназначенные для автоматизации управления изменениями и управления соглашениями SLA. Интеграция всех перечисленных модулей реализуется в максимально полном объеме, предоставляя возможность использовать рассматриваемый продукт в качестве основы для построения комплексной системы управления ИТ.
Продукт компании Remedy строится несколько сложнее, основой его является Remedy Action Request System, устанавливаемая на сервере. К системе в качестве прикладной части могут дополнительно приобретаться функциональные модули: Help Desk, Asset Management, Change Management и Service Level Agreement. Каждый из модулей может использоваться как самостоятельно (без других прикладных модулей), так и в составе комплексного решения. Вопросы автоматизации процессов управления проблемами и инцидентами, как и в случае решения от HP, реализуются в модуле Remedy Help Desk. При этом имеются некоторые отличия и реализуются отдельные собственные подходы к пониманию данных процессов, но основные пожелания и требования ITIL полностью учтены.
Для успешного внедрения процессов управления инцидентами и проблемами
необходимо выполнение, как минимум, следующих условий.
- Наличие актуальной и своевременно обновляемой базы CMDB. Если эта база недоступна, информация об имеющих отношение к инциденту единицах конфигурации будет добываться вручную, что существенно увеличит время обработки инцидента и повысит ее сложность.
- Доступность обновляемой базы знаний по ошибкам/проблемам и способам их разрешения, а также обхода. Наличие такой базы позволяет быстро разрешать многие проблемы. Желательно иметь возможность подключения к ней аналогичных баз, разработанных другими организациями и компаниями. Возникающие при этом вопросы совместимости могут привести к большим сложностям, поэтому рекомендуется использовать решения с открытой архитектурой, содержащие средства для импорта и экспорта данных. В последнее время все чаще в качестве стандартного способа доступа к информации используется Web-интерфейс, являющийся удобным и понятным, а также широко распространенным.
- С точки зрения потенциально конфликтной ситуации между управлением проблемами и управлением инцидентами (из-за их разных целей), необходимо организовать совместную работу и сотрудничество исполнителей обоих процессов. При этом нельзя забывать о том, что из тех же соображений один и тот же человек не может исполнять и те и другие обязанности одновременно: ему будет очень трудно найти баланс интересов.
- Организация эффективной автоматизированной системы регистрации инцидентов с возможностями детальной и качественной классификации, являющейся чрезвычайно важным элементом для организации функционирования как службы Service Desk, так и рассматриваемых процессов в чистом виде. Использование для этих целей бумажных технологий не рекомендуется.
Весьма удобно, если инструментальные средства, используемые для реализации рассматриваемых процессов, обладают следующими дополнительными возможностями:
- автоматической регистрацией инцидентов, происходящих в наиболее важных устройствах (серверы, сетевое оборудование и т.д.), для чего может потребоваться создание дополнительных интерфейсов;
- автоматической эскалацией инцидентов при нарушении временных графиков;
- гибкой маршрутизацией инцидентов, поскольку персонал служб поддержки может быть размещен в различных помещениях и зданиях;
- автоматическим поиском необходимых данных в базе CMDB;
- специальными решеними для облегчения классификации инцидентов;
- интеграцией с телефонными системами;
- наличием разнообразных диагностических модулей.
Проиллюстрируем перечисленные возможности на примере уже упоминавшегося Service Desk 3.0. Будучи представителем семейства продуктов HP OpenView, Service Desk содержит возможности получения сообщений от других продуктов данного семейства, в том числе от Network Node Manager, средства мониторинга и управления сетевыми устройствами, и VantagePoint Operations, средства мониторинга и управления серверами и приложениями. Данные продукты могут в автоматическом режиме, на основании собираемой информации о контролируемых объектах, генерировать запросы для Service Desk, которые автоматически передаются и анализируются операторами службы поддержки или обрабатываются в автоматическом режиме. При соответствующей настройке источниками аналогичных сообщений могут стать и иные диагностические средства. Продукт предусматривает возможности автоматического информирования путем отправки сообщений руководителей соответствующих уровней при нарушении сроков устранения инцидента. В нем реализованы расширенные возможности по поиску необходимой информации среди уже учтенных проблем, инцидентов и иных данных. В продукте представлены возможности интеграции с почтовыми, телефонными и пейджинговыми системами.
В виду актуальности и полезности перечисленных дополнительных возможностей, производители программных решений стараются включать их в свои продукты. Многое из сказанного о HP Service Desk относится и к продуктам других производителей, в том числе, Remedy, Tivoli, CA, Peregrin, FrontRange.
Тем, кто берется за работу по внедрению рассматриваемых процессов, надо быть готовым к разнообразным трудностям. Среди них:
- отсутствие поддержки со стороны руководства и персонала, что может вести к недостатку ресурсов для реализации;
- непонимание потребностей бизнеса, отсутствие согласованных уровней обслуживания, слабо определенные цели, возможности и ответственности различных служб;
- сопротивление изменениям и невозможность внесения изменений в сложившуюся практику работы;
- недостаток знаний для разрешения инцидентов, неправильная подготовка персонала, слабо формализованные правила взаимодействия пользователей со службами поддержки и различных служб между собой;
- слабая интеграция с другими процессами, некачественные средства автоматизации, невозможность связать регистрационные записи инцидентов и соответствующих им проблем существенно снижает возможности процесса, в том числе, возможности прогнозирования проблем.
***
Мы остановились на двух наиболее часто упоминаемых в связи с устранением возникающих неисправностей процессах управления элементами ИТ. Являясь довольно понятными на интуитивном уровне, данные процессы при этом сложны для реализации с точки зрения необходимости четкого соблюдения организационных мероприятий и процедур. Будучи во многом схожими, процессы управления инцидентами и управления проблемами обладают и существенными различиями, проистекающими из их основных целей. Максимальную важность при внедрении процессов приобретают используемые для этих целей средства автоматизации. К сожалению, первоисточники по ITIL доступны очень ограниченному кругу заинтересованных: стоят они весьма недешево, заказать их непросто, а получить - еще сложнее. Изложенные в статье требования и пожелания к инструментарию основываются на реальном опыте эксплуатации разнообразных средств и анализе путей решений возникавших при этом вопросов.
Литература
1. З. Алехин. ITIL - основа концепции управления ИТ-службами. «Открытые системы». 2001, № 3
2. З. Алехин. Service Desk - цели, возможности, реализации. «Открытые системы». 2001, № 5-6
3. CCTA. Best Practice for Service Support. London: The Stationery Office, 2000
Заурбек Алехин ([email protected]) - руководитель проекта компании i-Teco (Москва).
Что такое инцидент
Согласно принятому в ITIL определению под «инцидентом» понимается «любое событие, не являющееся элементом нормального функционирования службы и при этом оказывающее или способное оказать влияние на предоставление службы путем ее прерывания или снижения качества».
Приложения:
- служба недоступна;
- ошибка в приложении, не дающая клиенту нормально работать;
- исчерпано дисковое пространство.
Оборудование:
- сбой системы;
- внутренний сигнал тревоги;
- отказ принтера.
Заявки на обслуживание:
- поступление заявки на получение дополнительной информации, совета, документации;
- забытый пароль.
Большинство групп ИТ-специалистов имеет отношение к устранению тех или иных инцидентов. Служба Service Desk отвечает за мониторинг процесса устранения всех зарегистрированных инцидентов, поскольку является собственником всех таких инцидентов. Этот процесс в большей степени реактивный; для эффективного реагирования на инциденты должен быть определен формальный метод работы сотрудников, включающий использование необходимого программного обеспечения.
Те инциденты, которые не могут быть разрешены непосредственно службой Service Desk, должны быть переадресованы соответствующим специалистам. Способ разрешения инцидента или вариант его обхода должны быть установлены и доведены до пользователей как можно быстрее. Это вытекает из главной цели - минимизации отрицательного влияния на основную деятельность пользователей. После устранения причины инцидента и восстановления службы до оговоренного в SLA уровня инцидент закрывается.
В России сложилась интересная ситуация с расследованием инцидентов в сфере информационной безопасности. Большинство инцидентов замалчивается - если, конечно, дело не касается банковских счетов и финансовых транзакций. Администраторы и служба ИБ (если она есть) пытаются предпринять какие-то меры, затем все отчитываются перед руководством и об инциденте забывают. О полноценном расследовании речи, как правило, не идет, потому что либо безопасностью заниматься в компании просто некому, либо есть отдел, который разработал политику безопасности, внедрил современные технические средства, но этим и ограничивается. Ликвидация последствий сводится к смене чувствительной информации, такой как пароли и ключи, переустановке пары-тройки операционных систем (не всегда тех, которые необходимо).
Если следовать букве закона, когда обнаруживается инцидент информационной безопасности, нужно обращаться в государственные органы правопорядка. Но коммерческие структуры редко на это идут: мало того что приходится открыто признаться в собственном косяке, так еще и возникает множество вопросов - лицензионный ли софт, обеспечиваются ли меры, требуемые регуляторами… Потому у плохих ребят складывается ложное ощущение абсолютной безопасности, особенно если эти ребята занимаются взломом ради морального удовлетворения, а не ради коммерческой выгоды. Об одном таком случае я и расскажу в этой статье.
ТТХ
Компания N достаточно прогрессивна в своей сфере, поэтому внутреннее обеспечение службы ИТ на высоте: хорошие средства коммуникации, современное оборудование, приличные зарплаты. В свое время была создана служба безопасности, курирующая вопросы информационной, экономической и физической безопасности. Приглашенный подрядчик помог построить защищенную ИТ-инфраструктуру и ввести режим коммерческой тайны.
IT-инфраструктура представляет собой следующее:
- серверы располагаются в демилитаризованной зоне, доступ по сети в ДМЗ ограничивается межсетевыми экранами;
- повсеместно введена виртуализация серверов;
- присутствует сегментация сети с ограничением доступа между сегментами. Рабочие станции разнесены по VLAN’ам, с фильтрацией трафика между ними, в соответствии с внутренней иерархией;
- права доступа пользователям выделяются по принципу минимальных привилегий;
- централизовано софт обновляется только для продуктов Microsoft;
- ведется централизованный мониторинг серверов, правда, в основном с позиции доступности.
Инцидент
В начале года костяк топ-менеджмента компании N отправился на корпоративный выезд в далекие страны. Поездка предполагала не только развлечения, но и рабочие моменты, однако им не суждено было состояться: материал, который планировали презентовать и обсудить по-современному - с мобильного планшета, был утерян.
Прекрасное солнечное утро омрачилось: смартфоны и планшеты всех собравшихся в отеле на берегу океана (и не только их) оказались девственно чисты.
Данная информация была доведена до службы безопасности, которая разумно предположила, что тут не обошлось без внешнего вмешательства. Очевидно, что у всех сразу аккаунты iCloud взломать не могли, и служба безопасности заподозрила, что угроза исходит из корпоративной сети. Удаленно очистить мобильные устройства можно только через соответствующий сервис, например через корпоративный сервер Microsoft Exchange. Команда, позволяющая очистить устройство пользователя с адресом [email protected], выглядит следующим образом:
Clear-MobileDevice -Identity WM_TonySmith -NotificationEmailAddresses "[email protected]"
ИТ-службе поставили задачу проверить журналы сервера OWA: не было ли подозрительной активности в отношении аккаунтов пострадавших и компрометации пароля администратора сервера MS Exchange. Администраторы обнаружили зацепку - доступ к аккаунтам пострадавших в предшествующие инциденту дни неоднократно осуществлялся с нескольких нетипичных для них IP-адресов. Как я позже выяснил, засвеченные IP-адреса были выходными Tor-нодами.
Анализ логов OWA
Логи OWA хранятся по умолчанию в %SystemRoot%\System32\logfiles\w3svc1 . Структура логов - обычные текстовые файлы, изучать которые без вспомогательного инструмента, особенно при большом количестве пользователей, утомительно. На помощь придет Log Parser - очень ценный инструмент, который пригодится не только в подобной ситуации.
Для удобства преобразуем все имеющиеся логи в один файл формата CSV:
C:\Program Files\Log Parser 2.2>LogParser.exe -i:iisw3c "select * into d:\temp\alllog.log from %SystemRoot%\System32\logfiles\w3svc1\*" -o:csv
После чего составим список событий, отражающих доступ пользователей к OWA:
C:\Program Files\Log Parser 2.2>LogParser.exe -i:csv "select cs-username, date,time, c-ip, cs-uri-stem, cs(User-Agent) FROM d:\temp\alllog.log to d:\temp\access.csv" -o:csv
Выясняем, кто обращался к функциям OWA, отвечающим за удаление данных с устройства:
C:\Program Files\Log Parser 2.2>LogParser.exe -i:csv "select cs-username, date, time, c-ip, cs-uri-stem, cs-uri-query, cs(User-Agent) FROM d:\temp\alllog.log to d:\temp\access2.csv WHERE cs-uri-query LIKE "%wipe%"" -o:csv

Судя по системным логам, аккаунт администратора сервера OWA скомпрометирован не был. Целый день админы читали логи серверов, а служба безопасности тем временем беседовала со всеми админами по очереди, предполагая, что диверсант внутри компании. Однако это ни к чему не привело. Тогда они обратились по старому знакомству ко мне.
Поставили они такие задачи:
- установить источник угрозы - внутренний или внешний;
- выяснить сценарий атаки;
- определить последствия - скомпрометированные аккаунты и системы;
- определить дальнейшие действия для ликвидации угрозы.
Оказавшись на месте, я опросил ИТ-персонал. По итогам составил схему сети, определил расположение серверов и сервисов, собрал информацию об используемых операционных системах, настройке межсетевых экранов, парольной политике, политике обновления софта, персональных зонах ответственности администраторов.
Перепроверил результаты анализа логов администраторами. С помощью ntfswalk проанализировал MFT на наличие удаленных в последнее время файлов. Сервер OWA был чист и нетронут.
Так как скомпрометированы были пароли нескольких сотрудников сразу, я решил, что начать надо с того места, где хранятся пароли. Любой хакер, попадая в корпоративную сеть, сперва спешит полакомиться хешиками. Вопрос этот избитый, и детали получения хешей, думаю, знают все. Такой сценарий надо отработать первым - как наиболее вероятный. В данном случае доменная авторизация была настроена почти на всех устройствах, за исключением сетевого оборудования и Linux-серверов. Исходя из этого, я решил обследовать контроллеры домена.
Первым делом настроил отдельный сервер, на который стали зеркалировать трафик с потенциально скомпрометированных узлов и трафик, циркулирующий через шлюзы, в интернет. Подобные данные могут пригодиться в дальнейшем для выявления несанкционированного доступа.
Я получил актуальные копии виртуальных машин и начал с ними разбираться. Подключив виртуальные жесткие диски к своей системе, запустил процесс восстановления данных - есть вероятность обнаружить удаленные логи файлов, которые использовал злоумышленник. Для этого можно взять любой удобный софт для восстановления данных, результат будет примерно одинаков. Я предпочитаю R-Studio.

Так как у меня в исследовании были только образы виртуальных машин, процедура несколько упрощалась - не нужно тратить время на снятие образов жесткого диска и оперативной памяти. Файлы жестких дисков виртуальных машин можно либо конвертировать в raw , либо монтировать как есть, с помощью соответствующих утилит. Образ RAM и файл сохраненного состояния можно сконвертировать в «сырой» образ. Не стоит забывать и про файлы подкачки - в них тоже порой находится много интересного. Volatility версии 2.3 умеет все это разбирать и конвертировать в случае необходимости.
Отличия работы с физической системой от виртуальной в том, что образ памяти заполучить сложнее - это связано с риском повредить текущее состояние и потерять данные, которые могут оказаться существенными. Также при исследовании физической системы необходимо применять дополнительные инструменты и методики для определения скрытых областей (например, Host Protected Area - HPA и Device Configuration Overlay - DCO).
Обследовать Windows-машины в моем случае я решил по следующему сценарию:
Помимо этого, можно извлечь содержимое процесса в файл для дальнейшего исследования.
След найден
В оперативной памяти одного из контроллеров домена обнаружились явные признаки компрометации:
- процесс svchost.exe запущен из C:\Windows\WOW64 , а не из System32 , как ему полагается;
- исходящие сетевые соединения, на IP-адрес частного хостинга в Штатах;
- неизвестный процесс запущен с PPID , не отображающимся в списке процессов.
Процесс был идентифицирован с помощью утилиты vol.exe .
Vol.exe pslist -f image.vmem --profile=Win2008R2SP1x64 >pslist Offset(V) Name PID PPID 0xfffffa801996cb30 spintlx64.exe 2820 1388 ....
Но PID 1388 больше нигде не значился, что всегда очень подозрительно. В первую очередь необходимо было извлечь тело этого процесса и проверить хотя бы антивирусом.
vol.exe dumpfiles -r spintlx64 -f image.vmem —profile=Win2008R2SP1x64 -D ./
При проверке на VirusTotal показатель выявления был 34/50. При поверхностном анализе обнаружилось, что дата компиляции и сборки бинарника 1992-06-19 22:22:17 , а найденный при офлайн-анализе образа диска файл имел типичные для малвари изменения в атрибутах. Дата создания, изменения, последнего обращения были одинаковы и гораздо старше остальных системных файлов. Файл имел небольшой вес, создавал логи в зашифрованном виде и отправлял их по сети посредством HTTPS. С виду - типичный кейлоггер. Интересно, теперь предстоит разобраться, откуда и когда он попал в систему.
После восстановления данных все лог-файлы были загружены в Event Log Explorer для дальнейшего анализа. Штатные средства в такой ситуации не подходят: они не так поворотливы при поиске, а размеры логов очень большие (>30 Гб).
Отсортировав события по сетевому адресу источника, я получил несколько записей логов, показывающих, что осуществлялся сетевой вход (тип 3) одного из администраторов с сервера Zabbix . По событию входа была определена дата установки кейлоггера. Ее подтвердило время появления первых файлов, создаваемых кейлоггером, - они удалялись, но их получилось восстановить вместе с атрибутами. Больше ничего подозрительного ни в логах, ни в памяти, ни в реестре обнаружено не было. Дополнительно я проанализировал домашние каталоги пользователей сервера, но это не принесло новых результатов.
Завершив работу с контроллером домена, я переключил внимание на сервер Zabbix - именно с него осуществлялся доступ к контроллеру домена по сети.
Обследование Linux-системы концептуально не отличается от обследования Windows-системы. Ищем все то же самое: историю действий, производимых с системой. Если копнуть глубже, то исследовать можно все, от аппаратного уровня до истории запуска Microsoft Paint или набранных текстов. Но к счастью, обычно такой задачи не стоит. Зачастую задача достаточно конкретна и нет необходимости тратить время на то, что не принесет результата.
В данном случае предстояло обследовать Linux-систему на предмет несанкционированного доступа. О сервере предварительно было известно следующее: установлен Suse Linux , Apache + PHP + MySQL + Zabbix с сопутствующим программным обеспечением - всем знакомым LAMP . Выяснилось, что сотрудник, ответственный за сервер, с ОС Linux общается на «вы». Установил и обслуживал сервер его предшественник, который давно ушел из компании.
Для виртуального образа диска сервера был запущен поиск удаленных файлов. Стоит заметить, что, когда имеешь дело с образами, всегда лучше работать с копией, а полученный оригинал хранить отдельно. Естественно, желательно протестировать работоспособность любого программного обеспечения до того, как приступать к исследованию. Приходилось сталкиваться с тем, что образы памяти, созданные разными способами, выдавали при исследовании разный результат. Хотя не стоит исключать вариант, что в систему исследователя закрался вирус, - может быть и такое.
Изучать образ содержимого оперативной памяти системы Linux можно тем же комплектом Volatility, желательно последнего стабильного релиза, хотя после версии 2.0 он вполне справляется. Существует некоторая разница в сравнении с анализом образов RAM семейства Windows - в Volatility нет и в принципе не может быть шаблонов структуры памяти для каждого ядра. Поэтому шаблон придется создать. Для этого необходимо:
- запустить копию исследуемой системы;
- скопировать туда директорию volatility/tools/linux ;
- собрать проект, получив в результате файл module.dwarf , и скопировать его вместе с актуальным /boot/System.map того ядра, на котором работала система при снятии образа RAM, обратно на систему исследователя;
- упаковать оба файла, например в Linux.zip , и поместить архив в volatility/plugins/overlays/linux/ .
Теперь при запуске Volatility с ключом --info созданный тобой профайл будет виден в списке и с ним уже можно начать работу над образом. Без этого ничего не получится, потому что Volatility необходимо знать структуры данных ядра (module.dwarf) и иметь имена переменных, функций и их адреса в памяти (System.map).
Вернемся к исследованию. У меня было подозрение, что система, на которой установлен Zabbix, был скомпрометирована. Осталось понять, как и кто это сделал. Лишних ключей для SSH, посторонних учетных записей в системе не обнаружилось. Я предположил, что в системе есть backdoor , а возможно, и руткит. Для установки подобного рода софта зачастую требуются максимальные привилегии. Это очевидно, достаточно вспомнить основные принципы работы более-менее передовых руткитов в Linux-системах:
В первую очередь необходимо было проверить самые простые вещи, а именно историю выполненных команд: vol -f image.vmem -profile=Linux,x86 linux_bash
История команд была совсем небольшой, и первое, что бросилось в глаза, - это insmod rt.ko . Кстати, в файле истории на диске, конечно, ничего подобного не было, более того, восстановить какие-либо данные из файла истории также не удалось - содержимое уже было перезаписано быстро генерирующимися логами. Так что без образа памяти эти данные были бы неизвестны. Далее предстояло найти упомянутый в истории команд модуль ядра. Модуль был обнаружен на диске в директории PHP-скриптов интерфейса Zabbix.
Последующий анализ этого файла показал, что он прячет сам себя, маскирует при необходимости файлы, предоставляет привилегии root по команде. Управление ведется через файловую систему /proc/rt . С сетью не взаимодействует.
Просмотр сетевых соединений в образе памяти показал, что веб-сервер с Zabbix доступен из интернета. Конечно, я об этом не спрашивал, но подразумевал, что систему мониторинга в сеть никто не выставляет. Позже я выяснил у администраторов, что они так следят за системой, когда находятся вне офиса (несмотря на наличие VPN-аккаунта у каждого). Удобно, ничего не скажешь.
Я обратил внимание на Zabbix и пожалел, что не присмотрелся к нему раньше, - версия была подозрительно старая - 1.8.4 . Поиск по exploit-db.com показал, что в данной версии в скрипте popup.php присутствует SQL-инъекция, позволяющая получить хеши пользователей (CVE: 2011-4674). Проверка уязвимости показала ее полную работоспособность.
Схема подключения злоумышленника стала очевидна: через веб-шелл запускался back connect , предоставляющий интерактивный шелл, после чего привилегии повышались с помощью руткита. При такой схеме злоумышленник использовал этот хост как промежуточный для передачи зловреда на контроллер домена, а также для передачи базы ntds.dit и SYSTEM . Для эффективного поиска с помощью утилиты md5deep была создана база MD5-хешей всех файлов, восстановленных с образа сервера, после чего среди них произведен поиск хеша кейлоггера. Как результат - искомый файл был найден (правда, не с тем именем), а рядом лежал psexec и другие сопутствующие утилиты, которые были удалены.
Теперь можно было точно сказать, как произошел инцидент: злоумышленник, воспользовавшись уязвимостью Zabbix, получил и подобрал хеш пароля администратора Zabbix. С помощью скриптов Zabbix был загружен и запущен вспомогательный инструмент, в частности ncat для создания обратного соединения, с помощью которого был загружен и запущен локальный эксплойт, - версия ядра была полуторагодовалой давности.
Кстати говоря, Zabbix хранит скрипты в БД, и их следы были обнаружены в файле ibdata1.
После повышения привилегий злоумышленник использовал данную систему и подобранные пароли, которые у одного из админов оказались одинаковыми как в домене, так и в Linux-системе, для проникновения на контроллер домена. Получив доступ к контроллеру домена с правами администратора домена, злоумышленник завладел базой данных хешей паролей пользователей. Так как правила генерации паролей пользователями были весьма простые, а пароли не менялись по несколько лет, они были подобраны без особого труда. Обладая учетными данными большинства пользователей, злоумышленник мог читать их почту.
Ради эксперимента я попробовал сбрутить хеши пользователей домена. Легко и непринужденно за пару часов были вскрыты 90% паролей.
По всей видимости, когда злоумышленнику надоело просто читать почту, он решил ее удалить - тем самым развлечься, или отомстить, или выполнить заказ конкурентов? Его мотивация мне неизвестна.
В итоге система Zabbix была переведена в изолированный сегмент, сетевой трафик поставлен на запись, настроена IDS. Я ждал подключений хулигана, но это уже совсем другая история…
Как защитить свой iDevice
Любой iDevice общается с корпоративным сервером Exchange при помощи протокола ActiveSync. С позиции пользователя - защититься по умолчанию никак нельзя. Политика сервера Exchange подразумевает, что если устройство подключено к корпоративной сети, то администратор должен иметь возможность когда угодно управлять этим устройством для прекращения доступа к конфиденциальной информации. Помимо этого, пользователь, в случае утери или кражи, может зайти в OWA через любой браузер и запустить процесс удаленной очистки.
Если в организации имеется понимающий администратор Exchange - обратиться к нему и попросить убрать права на выполнение данной операции, а еще лучше - убрать доступ к пункту «Мобильные устройства» из веб-интерфейса OWA.
Вердикт
Настало время подвести итоги. К сложившейся ситуации привели ошибки администрирования сети и систем:
- слабая парольная политика - не установлена сложность пароля, не установлен срок действия пароля;
- отсутствует патч-менеджмент - кроме продуктов Microsoft, завязанных на WSUS, системы и софт не обновляется;
- не везде установлено антивирусное ПО - например, на контроллере домена антивирус, скорее всего, помог бы предупредить кражу хешей пользователей;
- отсутствует единая политика по доступу в интернет, доступ разграничивается без внятных правил;
- сеть не сегментирована;
- не осуществляется лог-менеджмент;
- лень.
5.3.1 Обработка Инцидента.
Большинство ИТ-подразделений и специализированных групп в той или иной степени вовлечены в обработку Инцидентов. Служба Service Desk отвечает за мониторинг процесса разрешения всех зарегистрированных Инцидентов и фактически является владельцем всех Инцидентов. Этот процесс в большей части работает по принципу реагирования. Для того чтобы продуктивно и эффективно реагировать, требуются формальные методы работы, которые могут поддерживаться программными средствами.
Инциденты, которые Служба Service Desk сразу не может разрешить, могут быть переданы для обработки одной из специализированных групп. Разрешение или Обходное решение должно быть представлено в максимально короткие сроки для того, чтобы восстановить обслуживание Пользователей с минимальным влиянием на их работу. После устранения причины Инцидента и восстановления согласованной услуги Инцидент закрывается.
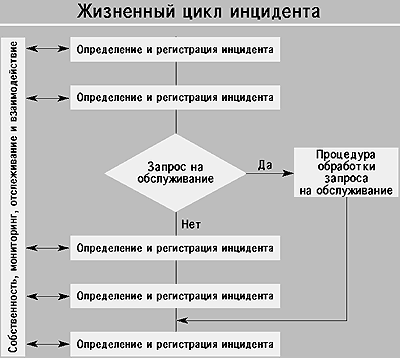
На Рисунке 5.2 показаны процессы, происходящие в течение жизненного цикла Инцидента. В Приложении 5Д эти процессы представлены с другой точки зрения.
Рисунок 5.2 - Жизненный цикл Инцидента.
Статус Инцидента отражает его текущее положение в жизненном цикле, иногда называемое «позицией в диаграмме последовательности выполняемых действий». Каждый сотрудник должен знать все возможные статусы и их значения. Несколько примеров категорий статусов:.
■ новый;.
■ принят;.
■ определены сроки;.
■ назначен/передан специалисту;.
■ в работе (Work In Progress, WIP);.
■ ожидание;.
■ разрешен;.
■ закрыт.
В течение жизненного цикла Инцидента важно, чтобы запись о нем поддерживалась в актуальном состоянии. Это позволит любому сотруднику группы обслуживания предоставлять Заказчику самые свежие данные о ходе обработки запроса. Некоторые примеры действий по обновлению записей:.
■ обновить исторические сведения;.
■ изменить статус (например, со статуса «новый» на статус «в работе» или «ожидание»);.
■ изменить влияние на бизнес и приоритет;.
■ ввести потраченное время и затраты;.
■ отследить статус эскалации.
Описание, первоначально заявленное Заказчиком, может измениться по ходу жизненного цикла Инцидента. Тем не менее, важно оставить описание исходных симптомов как для анализа, так и для того, чтобы можно было ссылаться на жалобу, используя формулировки, содержащиеся в первоначальном запросе. Например, Заказчик мог заявить, что не работает принтер, а было определено, что неполадка была вызвана сбоем в сети. При ответе Заказчику сначала лучше объяснить, что Инцидент с принтером разрешен, вместо того чтобы говорить о разрешении проблем с сетью.
Проверенная история Инцидента необходима при анализе хода его обработки, особенно это важно при разрешении вопросов, связанных с нарушением SLA. В ходе жизненного цикла Инцидента следует регистрировать следующие обновления записи о нем:.
■ имя человека, сделавшего изменение в записи;.
■ дата и время изменения;.
■ что именно этот человек изменил (например, приоритет, статус, историю);.
■ почему было внесено изменение;.
■ потраченное время.
Если внешним поставщикам запрещено обновлять записи Службы Service Desk (что и рекомендуется), тогда необходимо определить процедуру обновления записей за поставщика. Это гарантирует надлежащий учет использованных ресурсов. Тем не менее, если программное обеспечение допускает возможность выделить класс Инцидентов, устраняемых внешними поставщиками, и проводить предварительную проверку введенной информации, то в некоторых организациях может оказаться весьма удобным разрешить внешним поставщикам обновлять информацию напрямую. В случае принятия такого решения вам необходимо определить, какую информацию вы не готовы предоставить поставщику и насколько подробно вы должны быть информированы о действиях поставщика.
Такая же ситуация может возникнуть, когда Служба Service Desk обновляет запрос вместо специалиста службы технической поддержки, находящегося вне офиса. Иногда может понадобиться обновить учетную запись Инцидента постфактум, например, если специалисты работают в вечернее время, а Служба Service Desk должна обновлять записи вместо них на следующее утро.
5.3.2 Первая, вторая и третья линии поддержки.
Часто подразделения и (специализированные) группы поддержки, не входящие в состав Службы Service Desk, называются группами поддержки второй или третьей линии. Они обладают более специализированными навыками, дополнительным временем или другими ресурсами для разрешения Инцидентов. Исходя из этого, Служба Service Desk называется первой линией поддержки. На Рисунке 5.3 показано, как эта терминология связана с действиями в процессе Управления инцидентами, о которых говорилось в предыдущих параграфах.
Заметьте, что третья и/или N-я линия поддержки могут со временем включать внешних поставщиков, которые могут иметь прямой доступ к средствам регистрации Инцидентов (в зависимости от правил безопасности и технических вопросов).

Рисунок 5.3 ~ Первая, вторая и третья линии поддержки.
5.3.3 Сравнение функциональной и иерархической эскалации.
«Эскалация» - механизм, способствующий своевременному разрешению Инцидента. Он может сработать на любом этапе процесса разрешения.
Передача Инцидента от групп поддержки первой линии к группам поддержки второй линии или дальше называется «функциональной эскалацией» и происходит по причине недостатка знаний или квалификации. Предпочтительно, чтобы функциональная эскалация происходила в случаях, когда истекает согласованное время, отведенное на разрешение Инцидента. Автоматическая функциональная эскалация, которая вызывается по истечении определенного периода времени, должна быть тщательно спланирована и не должна превышать согласованное (в SLA) время разрешения.
«Иерархическая эскалация» может произойти в любой момент процесса разрешения, если существует вероятность того, что разрешение Инцидента не удастся завершить вовремя или оно окажется неудовлетворительным. В случае, если не хватает знаний или квалификации, иерархическая эскалация обычно производится вручную (Службой Service Desk или другим персоналом поддержки). Возможность проведения автоматической иерархической эскалации может рассматриваться после некоторого критичного периода времени, когда становится очевидным, что своевременно разрешить Инцидент не удастся. Предпочтительно, чтобы эскалация происходила задолго до истечения времени, отведенного (в SLA) на разрешение. Это позволит линейному руководству, имеющему соответствующие полномочия, принять меры по исправлению ситуации, например нанять специалистов внешнего поставщика.
5.3.4 Приоритет.
Приоритет Инцидента первоначально определяется его влиянием на бизнес и срочностью, с которой необходимо обеспечить разрешение или Обходное решение. Целевые показатели для разрешения Инцидентов или обработки запросов обычно включаются в SLA. На практике целевые показатели разрешения Инцидентов часто связаны с категориями. Примеры категорий и приоритетов, а также систем их кодирования, можно найти в Приложениях 5А и 5Б соответственно.
Службе Service Desk отводится важная роль в процессе Управления инцидентами:.
■ обо всех Инцидентах сообщается в Службу Service Desk, и ее сотрудники регистрируют Инциденты; в случаях, когда Инциденты генерируются автоматически, процесс все равно должен включать регистрацию через Службу Service Desk;.
■ основная масса Инцидентов (возможно, до 85% при высоком уровне навыков персонала) будет разрешена Службой Service Desk;.
■ Служба Service Desk - «независимое» подразделение, которое наблюдает за ходом разрешения всех зарегистрированных Инцидентов.
Ниже приведен перечень основных действий, которые выполняются Службой Service Desk после получения уведомления об Инциденте:.
■ запись основных сведений - включая время и полученные подробности о симптомах;.
■ если сделан запрос на обслуживание, заявка обрабатывается в соответствии со стандартными процедурами в данной организации;.
■ для дополнения записи об Инциденте на основе CMDB происходит выбор Учетных элементов (УЭ), являющихся, по сообщению, причиной Инцидента;.
■ установка соответствующего приоритета и передача Пользователю уникального номера Инцидента, автоматически генерируемого системой (чтобы сообщать его при дальнейших обращениях в службу);.
■ оценка Инцидента и, по возможности, предоставление рекомендаций по его разрешению: часто это возможно для стандартных Инцидентов или, когда его причиной является известная Проблема/ошибка;.
■ закрытие записи об Инциденте после его успешного разрешения: добавление сведений о действиях, связанных с разрешением, и установка соответствующего кода категории;.
■ передача Инцидента группе поддержки второй линии (т.е. специализированной группе) после неудачной попытки разрешения или при выяснении того, что необходим более высокий уровень поддержки.
5.3.5 Связи между Инцидентами, Проблемами, Известными ошибками и Запросами на Изменение (RFC).
Инциденты, возникшие в результате отказов или ошибок в ИТ-инфраструктуре, приводят к реальным или потенциальным отклонениям от запланированной работы ИТ-услуг.
Причина Инцидентов может быть очевидна, и тогда для устранения этой причины не потребуется дальнейшее расследование. В результате будет проведен ремонт, определено Обходное решение или оформлен RFC, который исправит ошибку. В некоторых случаях устранить сам Инцидент - т.е. его влияние на Заказчика можно довольно быстро. Возможно, просто требуется перезагрузка компьютера или повторная инициализация канала связи без выявления причины, лежащей в основе Инцидента.
В случаях, когда исходная причина Инцидента неизвестна, возможно, следует оформить запись о Проблеме. Таким образом, Проблема на самом деле является показателем неизвестной ошибки в инфраструктуре. Обычно запись о Проблеме оформляется только тогда, когда необходимость ее расследования оправдана серьезностью проблемы.
Влияние такой Проблемы часто будет оцениваться на основе влияния (как реального, так и потенциального) на бизнес-услуги, а также на основе числа заявленных похожих Инцидентов, которые, возможно, имеют одну и ту же исходную причину. Создание учетной записи Проблемы может быть уместно даже тогда, когда последствия Инцидента были устранены. Следовательно, запись о Проблеме может рассматриваться независимо от связанных с ней записей об Инцидентах, и как запись о Проблеме, так и расследование ее причины может продолжаться даже после того, как первоначальный Инцидент был успешно закрыт.
Успешная обработка записи о Проблеме приведет к идентификации корневой ошибки; эта запись может стать записью Известной ошибки после того, как разработано Обходное решение и/или RFC. Эта логическая цепочка, от первоначального уведомления до разрешения исходной проблемы, показана на Рисунке 5.4.
Рисунок 5.4 - Связи между Инцидентами, Проблемами, Известными ошибками и Запросами на Изменение (RFC).
Таким образом, мы имеем следующие определения:.
■ Проблема: неизвестная исходная причина одного и более Инцидентов.
■ Известная ошибка: Проблема, которая успешно диагностирована и для которой известно Обходное решение.
■ RFC: Запрос на Изменение любого компонента ИТ-инфраструктуры или любого аспекта ИТ-услуг.
Проблема может привести к множеству Инцидентов; также возможно, что Проблема не будет диагностирована до тех пор, пока не случится несколько Инцидентов в какой-нибудь период времени. Обработка Проблем значительно отличается от обработки Инцидентов и, следовательно, описана процессом Управления проблемами.
Во время процесса разрешения Инцидент проверяется на наличие связей в базе данных Проблем и Известных ошибок. Его также следует проверить на наличие связей в базе данных Инцидентов, чтобы определить, существуют ли похожие незакрытые Инциденты, и были ли разрешены предыдущие похожие Инциденты. Если уже доступно Обходное решение или разрешение, Инцидент может быть сразу же разрешен. В противном случае, процесс Управления инцидентами несет ответственность за разрешение или поиск Обходного решения с минимальным прерыванием бизнес-процесса.
Когда процесс Управления инцидентами находит Обходное решение, оно будет проанализировано командой Управления проблемами, которая потом обновит соответствующую запись о Проблеме (см. Рисунок 5.5). Необходимо отметить, что соответствующая запись о Проблеме может в этот момент еще не существовать например, Обходное решение может состоять в том, чтобы отослать отчет по факсу из-за сбоя в канале связи, но записи о Проблеме по поводу этого сбоя в канале связи может еще не быть; в этом случае команда Управления проблемами должна ее создать. Итак, в процесс входят действия, когда Служба Service Desk связывает Инциденты, которые являются результатом зарегистрированной Проблемы.

Рисунок 5.5 - Обработка Обходных решений и разрешений инцидента.
Также возможно, что группа Управления проблемами во время расследования Проблемы, связанной с Инцидентом, найдет Обходное решение или разрешение самой Проблемы и/или некоторых связанных с ней Инцидентов. В этом случае группа Управления проблемами должна сообщить об этом процессу Управления инцидентами для того, чтобы изменить статус открытых Инцидентов на «Известная ошибка» или «Закрыт».
Когда во время регистрации Инцидента предполагается, что этот Инцидент должен рассматриваться как Проблема, тогда он должен быть сразу же направлен на рассмотрение в процесс Управления проблемами, где, при необходимости, оформляется новая запись о Проблеме. Процесс Управления инцидентами будет, как всегда, нести ответственность за продолжение работы по разрешению Инцидента для минимизации его влияния на бизнес-процессы.
Метод критических инцидентов.
Выявление критического инцидента - это метод, предназначенный для иден-
тификации процесса, подпроцесса или проблемной области, которые стоит со-
вершенствовать. Метод разработан Лолором в 1985 году . Это вполне откры-
тый и короткий путь получения информации о проблемах организации. Как предварительное условие, предполагается, что все участники абсолютно свободны
в изложении своих взглядов. Любая цензура или сокрытие информации из бояз-
ни, что она окажется слишком честной, решительно отвергается.
Метод включает три этапа:
1). Выбираются участники проведения анализа. Если цель заключается в при-
нятии решения о совершенствовании всего процесса целиком, то естественно
включить представителей различных областей в организации. Если же це-
лью является более точное определение направленности действий в рамках
уже определенного бизнес-процесса, то лучше выбрать людей, вовлеченных в
этот процесс.
2). Затем участникам обсуждения предлагается ответить на вопросы типа:
С каким инцидентом на прошлой неделе было труднее всего справиться?
Какой эпизод создал наибольшие проблемы для удовлетворения потреб-
ностей потребителя?
Какой инцидент обошелся дороже всего с точки зрения привлечения
дополнительных ресурсов или прямых расходов?
На этом этапе использования метода важно выделить так называемые кри-
тические инциденты, которые тем или иным способом создают проблемы
для отдельных сотрудников, для всей организации и для других заинтересо-
ванных сторон. Период, к которому относится вопрос, может варьироваться
от нескольких дней до нескольких месяцев. Не рекомендуется, однако, вы-
бирать слишком долгий период, так как в этом случае может оказаться зат-
руднительным выделить самый актуальный критический инцидент, потому
что для большого периода времени таких инцидентов могло быть много.
3). Собранные ответы сортируются и определяется, какой из различных инци-
дентов упоминался чаще других. Для выделения критического инцидента
удобно использовать графическое представление полученных результатов. Тот
инцидент, который встретился чаще других, и будет критическим. Он - яв-
ный кандидат на профилактику. Однако бороться нужно не столько с самим
инцидентом и его симптомом, сколько с причинами, его породившими.
Пример.
Большая корпорация, имевшая в штате 15 телефонисток, приступила
к проекту улучшения телефонного обслуживания потребителей при от-
ветах на звонки. Было решено воспользоваться методом выявления кри-
тического инцидента.
Всем телефонисткам было предложено описать те инциденты, имев-
шие место за последний месяц, которые поставили их в крайне за-труднительное положение. Результаты опроса были рассортированы по частоте
повторения инцидентов. Они представлены на рис. 7.1 в виде диаграммы. Из ри-
сунка видно, что критическими инцидентами были: 1) невозможность дозвониться до
человека, которому следовало бы отвечать на звонок, 2) незнание, кто именно дол-
жен отвечать. На основании результатов исследования были предприняты усилия
по созданию системы отслеживания перемещений каждого сотрудника, а также бы-
ла разработана инструкция о том, кто из сотрудников и на какой запрос должен
отвечать. Контрольный листок - это бланк-формуляр или специальная форма, предназ-
наченная для регистрации данных, Ролстадос (1995) . Одно из основных при-
ложений контрольного листка заключается в том, чтобы фиксировать, как часто
встречаются различные проблемы или инциденты. Это дает важную информа-
цию о проблемных областях или возможных причинах ошибок. Использование
контрольных листков создает хорошую основу для принятия решений о том, где
следует сконцентрировать усилия при проведении совершенствования.
Заполнение контрольного листка обычно идет в несколько этапов:
1) Достижение соглашения о том, какие события надо записывать. Все это надо
точно определить, чтобы не было сомнений в том, имело ли место событие
на самом деле. Желательно также включить в контрольный листок позицию
«Прочее», чтобы зарегистрировать инциденты, которые трудно отнести в
2) Определение периода регистрации данных и его удобного деления на интер-
3) Разработка формы (бланка) контрольного листка, используемого для регис-
трации. 4) Сбор данных происходит в течение всего согласованного периода времени.
Предварительно следует убедиться в том, что все принимающие участие в
сборе данных одинаково понимают суть происходящего. Тогда собранные
разными людьми данные будут состоятельными.
5) По окончании сбора данных производится их анализ для выявления собы-
тий, имеющих наивысшую частоту проявления. Это позволит определить
приоритеты проблемных областей в рамках заданного бизнес-процесса для
обеспечения акцентов в работе по совершенствованию. Удобное вспомога-
тельное средство для проведения такого анализа - диаграмма ПаретоДиаграмма Парето
Построение этой схемы основано на так называемом принципе Парето, сфор-
мулированном итальянским математиком Вильфредо Парето в 1800-х годах. Под-
робности данной схемы можно найти также в книге Ролстадоса . Парето был
озабочен распределением богатств в обществе и считал, что 20% населения вла-
деют 80% всех богатств. В переводе на современный язык систем качества этот
принцип заключается в том, что часто примерно 80% всех возможных проявлений
обусловлены примерно 20% всех возможных причин. Разумный подход в этом
случае - начать работу по совершенствованию с атаки именно на эти 20% при-
чин, которые обычно называют «жизненно важным меньшинством». Это совсем
не означает, что можно игнорировать оставшиеся 80% причин: в надлежащий
момент времени этими причинами, которые называют «этим важным большин-
ством», также следует заняться. Принцип Парето определяет приоритеты про-
блем, за решение которых следует браться.
Диаграмма Парето сама по себе представляет графическую интерпретацию в
виде скошенного распределения так называемого правила «80/20». Это причины,
рассортированные по степени важности, по частоте возникновения, по затратам,
по уровню показателей и т.д. При упорядочивании причин на диаграмме Парето
самые важные из них относят к левому краю схемы, так, чтобы это «жизненно
важное меньшинство» было легко идентифицировать. Для повышения информа-
тивности диаграммы Парето обычно на нее наносят и кривую накопленных час-
тот. Пример построения диаграммы представлен на рис. 7.4.
При работе с диаграммой Парето выполняют следующие действия:
1). Определите главную проблему события и ее различные потенциальные при-
чины. С учетом допущений, принятых в настоящей книге, будем считать,
что уже выбран конкретный процесс, который желательно улучшить. Таким
образом, цель построения диаграммы Парето заключается в идентификации
основных причин низкого уровня показателей.
2). Определите, какой количественный показатель будет использоваться при
сравнении возможных причин. В качестве такого показателя можно было бы
взять частоту возникновения разного рода проблем или их следствий в тер-
минах денежных затрат и других условий.
3). Определите период времени, в течение которого будут собраны данные и со-
берите их. Часто эта работа уже оказывается выполненной ранее при за-
полнении контрольных листков. Суть контрольного листка описана в § 7.2.
4). Расположите причины слева направо вдоль горизонтальной оси диаграммы
Парето по убыванию степени их относительной важности. Нарисуйте стол-
бики схемы. Их высота соответствует степени относительной важности соот-
ветствующей
причины.
 5).
Отметьтеполученные
абсолютные значения показателей на
левой вертикаль-
5).
Отметьтеполученные
абсолютные значения показателей на
левой вертикаль-
ной оси. Отметьте относительные значения показателей в процентах на пра-
вой вертикальной оси. Нарисуйте кривую накопления важности вдоль верх-
него края столбиков.
Изучение диаграммы Парето может дать ответ на вопросы типа: 1) «Что пред-
ставляют собой две-три основные причины низкого уровня показателей данного
процесса?» или 2) «Какова доля затрат, приходящихся на самые жизненно важ-
ные причины?». Эта информация может быть использована для действий, на-
правленных на усилия по совершенствованию процесса в сторону достижения
его наивысших результатов.
Построение диаграммы Парето можно упростить, если пользоваться стандар-
тным компьютерным обеспечением, предназначенным для составления элект-
ронных таблиц. Вместе с тем для построения диаграмм Парето есть и специали-
зированное программное обеспечение. Две такие специализированные компьютерные программы - это StatGraphics Plus и ASAS/QC. Они также дают воз-
можность пользователю строить контрольные карты СУП"а. Отметим также пакет
Memory Jogger software, который может применяться с некоторыми инструментами
повышения качества.
Достоинства: Позволяет получать информацию о качествах, которые способствуют или препятствуют достижению результата в работе. Способствует лучшему пониманию содержания работы.
Недостатки: Часть полученной информации может не использоваться при создании модели, так как ряд описанных инцидентов может в итоге оказаться совершенно не характерным для работы.
Привет всем хабражителям,
очень часто, по долгу процессной службы приходиться слышать от сотрудников больших и малых департаментов IT один очень популярный вопрос: в чем разница между запросом на обслуживание и инцидентом?
Дискуссии на эту тему стары, как все вместе взятые методологии управления IT, тем не менее, давайте обратимся к первоисточникам.
Что нам говорит ITIL (официальный перевод глоссария по третьей версии):
Запрос на обслуживание - запрос пользователя на информацию, или консультацию, или на стандартное изменение, доступ к ИТ-услуге.
Инцидент - незапланированное прерывание ИТ-услуги или снижение качества ИТ-услуги.
Как обычно методология не лезет в глубь вещей и очень не любит отвечать на предметные вопросы сотрудников любого Сервис-деска, классифицирующих обращения пользователей. А меж тем, вопросов таких масса, вот несколько примеров:
1) Христоматийный звонок пользователя с просьбой сбросить пароль - как его классифицировать, как запрос на обслуживание или как инцидент? Или, может быть, как инцидент информационной безопасности?
2) Звонок от пользователя, у которого не работает корпоративная почта. Беглый анализ обращения говорит о том, что пользователю необходимо провести первичную настройку почтового клиента. Тем не менее с его точки зрения это инцидент, т.к. сервис не доступен, а его никто не уведомил, что «сама почта не полетит»
Стоит ли говорить что первичная классификация очень важна, так как она определяет весь последующий жизненный цикл обращения, в т.ч. и сроки исполнения.
Мое понимание этого вопроса сводится к вопросу оценки прерывания сервиса для конечного потребителя, и таким образом:
Инцидент - это, в большинстве случаев, прерывание или частичное прерывание ИТ-услуги, которая ранее предоставлялась пользователю в утвержденном режиме (сервис доступен 24/7, либо 5/8).
Пример: у главного бухгалтера компании внезапно пропал доступ к системе финансовой отчетности. С одной стороны предоставление доступа это классический сервисный запрос, но в данном случае на лицо явное прерывание сервиса и, как следствие, частичная деградация бизнес-процесса.
Запрос на обслуживание - это обращение от пользователя, который заинтересован в подключении дополнительной услуги, либо доработке функционала существующих услуг.
Пример: особо любопытный пользователь попытался открыть один из модулей все той же системы финансовой отчетности, но получил сообщение об ошибке. С его т.з. это инцидент, так как он не достиг желаемой цели и не получил искомую информацию, но, с т.з. описанной выше - это классический запрос на обслуживание на предоставление доступа, требующий согласования и выполняемый по стандартной процедуре в согласованный срок.
При этом не стоит забывать про многообразие частных случаев которые вообще сложно поддаются классификации, точка зрения описанная выше не претендует на догму, а лишь стремиться помочь минимизировать количество неправильно классифицированных обращений и улучшить общее время реакции IT на потребности бизнеса.