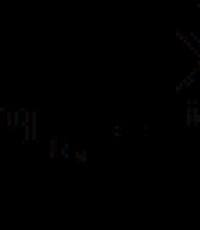Управление на инциденти и проблеми – концепции и принципи. Справяне с инциденти, свързани със сигурността на информацията
Когато обработвате множество инциденти едновременно, е необходимо приоритизиране. Обосновката за присвояване на приоритет е нивото на важност на грешката за бизнеса и за потребителя. Въз основа на диалог с потребителя и в съответствие с разпоредбите на Споразуменията за ниво на обслужване (SLA), Service Desk присвоява приоритети, които определят реда, в който се обработват инцидентите. Когато инцидентите са ескалирани до втора, трета или повече линия за поддръжка, трябва да се запази същият приоритет, но понякога може да се коригира след консултация със сервизното бюро.
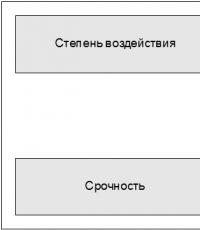
въздействие на инцидента: степента на отклонение от нормалното ниво на предоставяне на услугата, изразена в броя на потребителите или бизнес процесите, засегнати от инцидента;
спешност на инцидента: Приемливо забавяне при разрешаване на инцидент за потребител или бизнес процес.
Приоритетът се определя въз основа на спешността и въздействието. За всеки приоритет се определят броят на специалистите и количеството ресурси, които могат да бъдат насочени към разрешаване на инцидента. Редът, в който се обработват инциденти с еднакъв приоритет, може да се определи според усилията, необходими за разрешаване на инцидента. Например лесно разрешен инцидент може да бъде обработен преди инцидент, който изисква повече усилия.
В управлението на инциденти има начини за намаляване на въздействието и спешността, като например превключване на системата към резервна конфигурация, пренасочване на опашката за печат и т.н.

Ориз. 4.2. Определяне на въздействие, спешност и приоритет
Въздействието и спешността също могат сами по себе си да се променят с течение на времето, например с увеличаване на броя на потребителите, засегнати от инцидент, или в критични моменти във времето.
Въздействието и спешността могат да бъдат комбинирани в матрица, както е показано в таблица 1. 4.1.

Таблица 4.1. Пример за система за приоритетно кодиране
Ескалация
Ако инцидентът не може да бъде разрешен от първата линия за поддръжка в рамките на уговореното време, трябва да бъдат привлечени допълнителни експертни познания или авторитет. Това се нарича ескалация, която настъпва в съответствие с обсъдените по-горе приоритети и съответно времето за разрешаване на инцидента.
Има функционална и йерархична ескалация:
Функционална ескалация (хоризонтално)– означава привличане на повече специалисти или предоставяне на допълнителни права за достъп за разрешаване на инцидента; в същото време е възможно да има разширение извън границите на един структурен ИТ отдел.
Йерархична ескалация (вертикална)– означава вертикален преход (към по-високо ниво) в рамките на организацията, тъй като няма достатъчно организационни правомощия (ниво на власт) или ресурси за разрешаване на инцидента.
Работата на мениджъра на процесите за управление на инциденти е проактивно да запазва функционални възможности за ескалация в рамките на линейните звена на организацията, така че разрешаването на инциденти да не изисква редовна йерархична ескалация. Във всеки случай линейните звена трябва да осигурят достатъчно ресурси за този процес.
Първа, втора и n-редова поддръжка
Маршрутизирането на инцидента или функционалната ескалация беше описано по-горе. Маршрутизирането се определя от необходимото ниво на знания, авторитет и спешност. Първата линия на поддръжка (наричана още поддръжка на ниво 1) обикновено е Service Desk, втората линия е управление на ИТ инфраструктура, третата е разработка на софтуер и архитектура, а четвъртата е доставчици. Колкото по-малка е организацията, толкова по-малко нива на ескалация има. В големи организации мениджърът на процеса за управление на инциденти може да назначи координатори на инциденти в съответните отдели, които да подпомагат неговите дейности. Например координаторите могат да играят ролята на интерфейс между процесните дейности и линейните организационни единици. Всеки от тях координира дейността на своите групи за подкрепа. Процедурата за ескалация е представена графично на фиг. 4.3.

Ориз. 4.3. Ескалация на инцидента (източник: OGC)
4.2. Мишена
Целта на процеса за управление на инциденти е да възстанови нормалното ниво на обслужване, както е определено в Споразумението за ниво на обслужване (SLA), възможно най-бързо, с минимални възможни загуби за бизнес дейностите на организацията и потребителите. В допълнение, процесът за управление на инциденти трябва да поддържа точен запис на инциденти, за да оцени и подобри процеса и да предостави необходимата информация на други процеси.
4.2.1. Ползи от използването на процеса
За бизнеса като цяло:
Навременно разрешаване на инциденти, водещи до намаляване на бизнес загубите;
Повишена потребителска продуктивност;
Независим, фокусиран върху клиента мониторинг на инциденти;
Наличие на обективна информация за съответствието на предоставяните услуги с договорените споразумения (SLA).
За ИТ организация:
Подобрен мониторинг, позволяващ точно сравнение на нивата на производителност на ИТ системата със споразумения (SLA);
Ефективно управление и мониторинг на изпълнението на споразуменията (SLAs) въз основа на надеждна информация;
Ефективно използване на персонала;
Предотвратяване на инциденти и заявки за услуги от загуба или неправилно записване;
Повишаване на точността на информацията в базата данни за управление на конфигурацията (CMDB) чрез проверка при регистриране на инциденти във връзка с конфигурационни елементи (CI);
Повишена удовлетвореност на потребителите и клиентите.
Неизползването на процеса за управление на инциденти може да доведе до следните негативни последици:
Инцидентите могат да бъдат загубени или, обратно, необосновано възприемани като изключително сериозни поради отсъствие на лица, отговорни за наблюдение и ескалация, което може да доведе до намаляване на общото ниво на обслужване;
Потребителите могат да бъдат пренасочени към същите специалисти „в кръг“ без успешно разрешаване на инцидента;
Професионалистите могат постоянно да бъдат прекъсвани от телефонни обаждания от потребители, което ги затруднява да вършат работата си ефективно;
Могат да възникнат ситуации, при които няколко души работят по един и същи инцидент, губейки време непродуктивно и вземайки противоречиви решения;
Възможно е да липсва информация за потребителите и предоставените услуги в подкрепа на управленските решения;
Поради горните потенциални проблеми разходите за компанията и ИТ организацията за поддръжка на услугите ще бъдат по-високи от реално необходимите.
4.3. Процес
На фиг. Фигура 4.4 показва входовете и изходите на даден процес, както и дейностите, които процесът включва.

Ориз. 4.4. Декларация за процеса на управление на инциденти
4.3.1. Процесни входове
Инциденти могат да възникнат във всяка част от инфраструктурата. Те често се съобщават от потребителите, но могат да бъдат открити и от служители на други отдели, както и от системи за автоматично управление, конфигурирани да записват събития в приложенията и техническата инфраструктура.
4.3.2. Управление на конфигурацията
Базата данни за управление на конфигурацията (CMDB) играе важна роля в управлението на инциденти, тъй като определя връзката между ресурси, услуги, потребители и нива на обслужване. Например Управлението на конфигурацията показва кой е отговорен за даден инфраструктурен компонент, което прави възможно по-ефективното разпределяне на инцидентите между екипите. В допълнение, тази база данни помага за разрешаването на оперативни проблеми като пренасочване на опашка за печат или превключване на потребител към друг сървър. Когато се регистрира инцидент, към регистрационните данни се добавя връзка към съответния конфигурационен елемент (CI), което позволява предоставянето на по-подробна информация за източника на грешката. Ако е необходимо, състоянието на съответния компонент в CMDB може да бъде актуализирано.
4.3.3. Управление на проблеми
Ефективното управление на проблеми изисква висококачествено записване на инциденти, което значително ще улесни търсенето на първопричините. От друга страна, управлението на проблеми помага на процеса на управление на инциденти, като предоставя информация за проблеми, известни грешки, заобиколни решения и бързи поправки.
4.3.4. Управление на промените
Инцидентите могат да бъдат разрешени чрез извършване на промени, като например подмяна на монитора. Управлението на промените предоставя на процеса за управление на инциденти информация за планираните промени и техните статуси. Освен това промените могат да причинят инциденти, ако промените са направени неправилно или съдържат грешки. Процесът за управление на промените получава информация за тях от процеса за управление на инциденти.
4.3.5. Управление на нивото на обслужване
Управлението на нивото на обслужване контролира изпълнението на споразуменията (SLA) с клиента по отношение на предоставената му поддръжка. Персоналът, участващ в управлението на инциденти, трябва да е запознат с тези споразумения, за да използва необходимата информация, когато се свързва с потребителите. Освен това се изискват записи на инциденти за целите на докладването, за да се провери дали договореното ниво на обслужване се спазва.
4.3.6. Управление на достъпността
Процесът на управление на наличността използва регистрационни файлове за инциденти и данни за наблюдение на състоянието, предоставени от процеса на управление на конфигурацията, за да определи показателите за наличност на услугата. Подобно на конфигурационен елемент (CI) в конфигурационна база данни (CMDB), на услугата може също да бъде присвоен статус „извън ред“. Това може да се използва за проверка на действителната наличност на услугата и времето за реакция на доставчика. При извършване на такава проверка е необходимо да се запише времето на действията, извършени по време на процеса на обработка на инцидента, от момента на откриване до затваряне.
4.3.7. Управление на капацитета
Процесът на управление на капацитета получава информация за инциденти, свързани с функционирането на самите ИТ системи, например инциденти, възникнали поради недостатъчно дисково пространство или ниска скорост на реакция и др. От своя страна информацията за тези инциденти може да влезе в процеса на управление на инциденти от системния администратор или от самата система въз основа на наблюдение на нейното състояние.
Без ориз. 4.5. показани са стъпките на процеса:

Ориз. 4.5. Процес на управление на инциденти
Приемане и записване– съобщението се получава и се създава запис на инцидент.
Класификация и първоначална поддръжка– задават се вид, статус, степен на въздействие, спешност, приоритет на инцидента, SLA и др. На потребителя може да бъде предложено възможно решение, дори и то да е само временно.
Ако обаждането засяга Заявка за обслужване, тогава се стартира съответната процедура.
Свързване (или съвпадение)– проверява дали инцидентът вече е известен инцидент или известен бъг, дали вече има открит проблем за него и дали има известно решение или заобиколно решение за него.
Изследване и диагностика (Изследване и диагностика)– при липса на известно решение се извършва разследване на инцидента, за да се възстанови нормалната работа възможно най-бързо.
Резолюция и възстановяване– ако се намери решение, работата може да бъде възстановена.
Закриване– потребителят се свързва, за да потвърди приемането на предложеното решение, след което инцидентът може да бъде затворен.
Мониторинг и проследяване на напредъка– следи се целият цикъл на обработка на инцидента и ако инцидентът не може да бъде разрешен навреме, се извършва ескалация.
4.4. дейности
4.4.1. Прием и регистрация
В повечето случаи инцидентите се регистрират от Service Desk, където се докладват инциденти. Всички инциденти трябва да бъдат записани незабавно след уведомяване поради следните причини:
Трудно е да се запише точно информация за инцидент, ако не се направи незабавно;
Мониторингът на хода на работата по разрешаване на инцидент е възможен само ако инцидентът е регистриран;
Регистрираните инциденти помагат при диагностицирането на нови инциденти;
Управлението на проблеми може да използва регистрирани инциденти, когато работи за намиране на първопричините;
По-лесно е да се определи степента на въздействие, ако всички съобщения (обаждания) се записват;
Без записване на инциденти е невъзможно да се наблюдава изпълнението на споразуменията (SLA);
Незабавното регистриране на инциденти предотвратява ситуации, при които или множество хора работят по едно и също обаждане, или никой не прави нищо, за да разреши инцидента.
Местоположението на инцидента се определя от това откъде е дошло съобщението за него. Инцидентите могат да бъдат открити, както следва:
Открито от потребител: Той докладва инцидента на сервизното бюро.
Открит от системата: Когато бъде открито събитие в приложението или техническата инфраструктура, например когато е надвишен критичен праг, събитието се записва като инцидент в системата за докладване на инциденти и, ако е необходимо, ескалира до екипа за поддръжка.
Открит от Service Desk: Служителят записва инцидента.
Открито от някой в друг ИТ отдел: Този специалист регистрира инцидента в системата за докладване на инциденти или го докладва на Service Desk.
Трябва да се избягва двойното записване на един и същи инцидент. Следователно, когато регистрирате инцидент, трябва да проверите дали има подобни открити инциденти:
Ако има (и се отнасят за същия инцидент), информацията за инцидента се актуализира или инцидентът се регистрира отделно и се установява връзка (линк) към основния инцидент; ако е необходимо, нивото на въздействие и приоритетът се променят и се добавя информация за новия потребител.
Ако не (различно от открит инцидент), е регистриран нов инцидент.
И в двата случая продължаването на процеса е същото, въпреки че в първия случай следващите стъпки са много по-прости.
При регистриране на инцидент се извършват следните действия:
Присвояване на номер на инцидент: В повечето случаи системата автоматично присвоява нов (уникален) номер на инцидент. Често този номер се предоставя на потребителя, за да може да го използва при бъдещи контакти.
Записване на основна диагностична информация: време, признаци (симптоми), потребител, служител, приел проблема за обработка, място на инцидента и информация за засегнатата услуга и/или техническо средство.
Записване на допълнителна информация за инцидента: Информацията се добавя, например, от скрипт или процедура за запитване или от база данни за конфигурация (CMDB) (обикновено въз основа на връзките на конфигурационен елемент, дефинирани в CMDB).
Алармено съобщение: Ако възникне инцидент със силно въздействие, като например критичен отказ на сървъра, се издава предупреждение до други потребители и ръководство.
4.4.2. Класификация
Класификацията на инцидентите има за цел да определи категорията им, за да улесни наблюдението и докладването. Желателно е възможностите за класификация да са възможно най-широки, но това изисква по-високо ниво на отговорност на персонала. Понякога те се опитват да комбинират няколко аспекта на класификацията в един списък, като тип, група за поддръжка и източник. Това често предизвиква объркване. По-добре е да използвате няколко кратки списъка. Този раздел разглежда въпроси, свързани с класификацията.
Централна система за обработка– подсистема за достъп, централен сървър, приложение.
Нет– рутери, сегменти, хъб, IP адреси.
Работна станция– монитор, мрежова карта, дисково устройство, клавиатура.
Използване и функционалност– услуга (сервиз), възможности на системата, наличност, резервно копие (backup), документация.
Организация и процедури– поръчка, искане, поддръжка, уведомяване (комуникации).
Заявка за обслужване– потребителска заявка до Service Desk за поддръжка, информация, документация или консултация. Това може да бъде отделено в отделна процедура или да се третира по същия начин като истински инцидент.
Приоритет
След това се присвоява приоритет, за да се гарантира, че екипът за поддръжка обръща на инцидента нужното внимание. Приоритетът е число, определено от спешността (колко бързо трябва да се поправи) и въздействието (колко щети ще бъдат нанесени, ако не бъдат поправени бързо).
Приоритет = Спешност x Въздействие.
Услуги (услуги)
За идентифициране на услугите, засегнати от инцидента, може да се използва списък със съществуващи споразумения за ниво на обслужване (SLA). Този списък също ще ви позволи да зададете времето за ескалация за всяка от услугите, дефинирани в SLA.
Помощна група
Ако сервизното бюро не може да разреши инцидента незабавно, се назначава екип за поддръжка, който да разреши инцидента. Основата за разпределение на инциденти (маршрутизиране) често е информация за категория. Когато се дефинират категории, може да се наложи да се обърне внимание на структурата на групите за подкрепа. Правилното разпределение на инцидентите е от съществено значение за ефективността на процеса за управление на инциденти. Следователно един от ключовите показатели за ефективност (KPI) на процеса за управление на инциденти може да бъде броят на неправилно разпределените билети.
Срок за решение
Като се има предвид приоритетът и споразумението за SLA, потребителят се информира за максималното очаквано време за разрешаване на инцидента. Тези срокове също се записват в системата.
Идентификационен номер на инцидент
Абонатът се информира за инцидентния номер за точната му идентификация при последващи разговори.
Статус
Състоянието на инцидент показва неговата позиция в процеса на обработка на инцидента. Примери за състояния могат да бъдат:
Планиран;
Назначен;
Активен;
Отложено;
Позволен;
4.4.3. Обвързване (съпоставяне)
След класификацията се прави проверка дали подобен инцидент е имало преди и дали има готово решение или заобиколно решение. Ако даден инцидент има същите характеристики като отворен проблем или известна грешка, той може да бъде свързан с него.
4.4.4. Изследване и диагностика
Сервизното бюро или екипът за поддръжка ескалира инциденти, които нямат решение или са извън възможностите на лицето, което работи с тях, към следващото ниво на екип за поддръжка с повече опит и знания. Този екип проучва и разрешава инцидента или го ескалира до следващото ниво на екипа за поддръжка.
По време на процеса на разрешаване на инцидента различни специалисти могат да актуализират записа на инцидента, като променят текущото състояние, информация за предприетите действия, преразглеждане на класификацията и актуализиране на часа и кода на служителя.
4.4.5. Решение и възстановяване
След успешно приключване на анализа и разрешаване на инцидента, служителят записва решението в системата. В някои случаи е необходимо да подадете заявка за промяна (RFC) към процеса за управление на промените. В най-лошия случай, ако не се намери решение, инцидентът остава открит.
4.4.6. Затваряне
След като дадено решение бъде внедрено така, че потребителят да е удовлетворен, екипът за поддръжка ескалира инцидента обратно към Service Desk. Тази услуга се свързва със служителя, съобщил за инцидента, за да получи потвърждение, че проблемът е разрешен успешно. Ако той потвърди това, тогава инцидентът може да бъде приключен; в противен случай процесът се възобновява на подходящото ниво. Когато даден инцидент е затворен, е необходимо да се актуализира последната категория, приоритет, услуга(и), засегната(и) от инцидента, и конфигурационния елемент (CI), който е причинил неуспеха.
4.4.7. Мониторинг и проследяване на напредъка на решението
В повечето случаи Service Desk, като „собственик“ на всички инциденти, отговаря за наблюдението на напредъка на разрешаването. Тази услуга трябва също така да информира потребителя за състоянието на инцидента. Обратната връзка с потребителите може да е подходяща след промяна в състоянието, като например ескалиране на инцидент до следващата линия за поддръжка, промяна на очакваното време за разрешаване, ескалация и т.н. По време на наблюдение е възможна функционална ескалация към други групи за поддръжка или йерархична ескалация за вземане на изпълнителни решения .
4.5. Контрол на процесите
Основата за контрол на процеса са отчетите за различни целеви групи. Мениджърът на процесите за управление на инциденти е отговорен за тези доклади, както и за пощенския списък и графика за докладване. Докладите могат да включват специализирана информация за следните функционални звена:
Мениджърът на процеса за управление на инциденти се нуждае от доклада, за да:
Идентифициране на липсващи връзки в процеса;
Идентифициране на нарушения на споразуменията за ниво на обслужване (SLA);
Проследяване на хода на процеса;
Определяне на тенденциите на развитие.
Управление на линейни ИТ отдели– отчет за управление на групата за подкрепа; може да бъде полезен и при управлението на ИТ отдела. Докладът трябва да съдържа следната информация:
Напредък в разрешаването на инциденти;
Време за разрешаване на инциденти в различни групи за поддръжка.
Управление на нивото на обслужване– докладът трябва да съдържа преди всичко информация за качеството на предоставените услуги. Мениджърът на процеса за управление на нивото на обслужване трябва да получи цялата информация, необходима за изготвяне на отчети за нивото на обслужване за клиентите. Докладите до клиентите трябва да предоставят информация дали споразуменията за ниво на обслужване се спазват в рамките на процеса за управление на инциденти.
Мениджъри на други процеси за управление на ИТ услуги– докладите за мениджърите на други процеси трябва преди всичко да бъдат информативни, тоест да съдържат цялата необходима информация. Например, процес за управление на инциденти, базиран на записи на инциденти, може да предостави следната информация:
Брой разкрити и записани инциденти;
Брой разрешени инциденти, разделен на времето за разрешаване;
Статус и брой неразрешени инциденти;
Инциденти по период на възникване, групи клиенти, групи за поддръжка и време за разрешаване в съответствие със споразумението (SLA);
4.5.1. Критични фактори за успех
Успешното управление на инциденти изисква следното:
Актуална конфигурационна база данни (CMDB), която помага да се оцени въздействието и спешността на инцидентите. Тази информация може да бъде получена и от потребителя, но в този случай тя може да бъде по-малко пълна и доста субективна, което ще доведе до увеличаване на времето, необходимо за разрешаване на инциденти.
За да се оцени ефективността на процеса, е необходимо ясно да се дефинират контролни параметри и измерими резултати, често наричани показатели за ефективност. Тези показатели се отчитат редовно, например веднъж седмично, за да осигурят картина на промените, от която могат да се идентифицират тенденциите. Примери за такива параметри са:
Общ брой инциденти;
Средно време за разрешаване на инциденти;
Средно време за разрешаване на инциденти по приоритет;
Среден брой инциденти, разрешени в рамките на SLA;
Процент на инциденти, разрешени от първата линия за поддръжка (без насочване към други групи);
Средна цена за поддръжка на инцидент;
Брой разрешени инциденти на работно място или на служител на Service Desk;
Инциденти, разрешени без посещение на потребителя (дистанционно);
Брой (или процент) на инциденти с първоначално неправилна класификация;
Брой (или процент) на инцидентите, неправилно присвоени на групи за поддръжка.
4.5.3. Функции и роли
Изпълнението на процесите се осъществява в хоризонтална равнина чрез йерархичната структура на организацията. Това е възможно само при ясно дефиниране на отговорностите и правомощията, свързани с изпълнението на процесите. За да се увеличи гъвкавостта, може да се използва подход, базиран на роли (т.е. дефиниране на роли). В малки организации или с цел намаляване на общите разходи е възможно да се комбинират роли, например комбиниране на ролите на Управление на промените и Мениджър на процеси за управление на конфигурацията.
Мениджър на процеса за управление на инциденти
В много организации ролята на мениджър за управление на инциденти се играе от мениджъра на бюрото за обслужване. Отговорностите на мениджъра на процеса за управление на инциденти включват следното:
Следене на ефективността и рационалността на процеса;
Мониторинг на работата на групите за подкрепа;
Разработване и поддръжка на системата за управление на инциденти.
Персонал на групата за поддръжка
Първата линия за поддръжка е отговорна за записване, класифициране, съпоставяне (свързване), присвояване на групи за поддръжка, разрешаване и затваряне на инциденти.
Останалите екипи за поддръжка участват предимно в разследване, диагностициране и разрешаване на инциденти в рамките на установените приоритети.
4.6. Разходи и проблеми
4.6.1. Разноски
Разходите, свързани с управлението на инциденти, включват първоначални разходи за внедряване (напр. разходи за разработване на процеса, обучение и обучение на персонал), подбор и доставка на инструменти за подпомагане на процеса. Изборът на инструменти може да отнеме значително време. Освен това има оперативни разходи, свързани със заплащането на персонала и използването на инструменти. Тези разходи до голяма степен зависят от структурата на управлението на инциденти, набора от дейности, включени в процеса, областите на отговорност и броя на отделите.
4.6.2. проблеми
При внедряването на Управление на инциденти могат да възникнат следните проблеми:
Потребителите и ИТ специалистите работят около процедурите за управление на инциденти– ако потребителите отстранят грешките сами или директно се свържат със специалисти, без да спазват установените процедури, ИТ организацията няма да получи информация за реално предоставеното ниво на услугата, броя на грешките и много други. Докладите до ръководството също няма да отразяват адекватно ситуацията.
Претоварване с инциденти и отлагане „за по-късно“– ако има неочаквано увеличение на броя на инцидентите, може да няма достатъчно време за правилна регистрация, тъй като преди края на въвеждането на информация за инцидента от един потребител, става необходимо да се обслужи следващият. В този случай въвеждането на описанията на инциденти може да не е достатъчно точно и процедурите за разпределяне на инциденти към групите за поддръжка няма да бъдат извършени правилно. В резултат на това решенията са с лошо качество и натоварването се увеличава още повече. В случаите, когато броят на откритите инциденти започне бързо да се увеличава, процедура за спешно разпределяне на допълнителни ресурси в рамките на организацията може да предотврати претоварването на персонала.
Ескалация– Както е известно, ескалация на инциденти е възможна в рамките на процеса за управление на инциденти. Твърде много ескалации могат да окажат отрицателно въздействие върху работата на специалистите, които следователно се откъсват от планираната им работа.
Липса на каталог на услуги и споразумения за ниво на обслужване (SLA)– Ако поддържаните услуги и продукти не са добре дефинирани, тогава може да е трудно за участващите в управлението на инциденти разумно да откажат помощ на потребителите.
Липса на ангажираност процесен подход от страна на ръководството и персонала– разрешаването на инциденти с помощта на процесния подход обикновено изисква промяна в културата и по-високо ниво на отговорност за тяхната работа от страна на персонала. Това може да предизвика значителна съпротива в организацията. Ефективното управление на инциденти изисква служителите да разбират и наистина да се ангажират с процесния подход, вместо просто да участват.
Бележки:
„Веригата“ се отнася до веригата на създаване на принадена стойност. – Прибл. изд.
В ITIL литературата понятието „функция“ се свързва с вертикално (линейно) разделение на организация, която изпълнява съответните функционални отговорности и всъщност е синоним на него. – Прибл. изд.
Заявка за обслужване.
Искане за промяна (RFC).
Конфигурационен елемент (CI).
Ключови показатели за ефективност – KPI.
Индикатори за ефективност.
Ефективност и ефикасност.
Тези. софтуер. – Прибл. изд.
Осигуряване на сигурност на бизнес информацията Андрианов В.В.
4.1.4. Примери за инциденти
4.1.4. Примери за инциденти
Главна информация
Този раздел описва публикувани подробности за някои от нашумелите инциденти. В същото време обобщаването на инцидентите предоставя цял набор от обстоятелства, характеризиращи разнообразието от заплахи за информационната сигурност от персонала, както по отношение на мотиви и условия, така и по отношение на използваните средства. Сред най-често срещаните инциденти отбелязваме следното:
Изтичане на официална информация;
Кражба на клиенти и бизнес на организацията;
Саботаж на инфраструктурата;
Вътрешна измама;
Фалшифициране на отчети;
Търговия на пазари въз основа на вътрешна и частна информация;
Злоупотреба с власт.
анотация
Като отмъщение за твърде малък бонус, 63-годишният Роджър Дуронио (бивш системен администратор в UBS Paine Webber) инсталира „логическа бомба“ на сървърите на компанията, която унищожи всички данни и парализира работата на компанията за дълго време.
Описание на инцидента
Дуронио бил недоволен от заплатата си от 125 000 долара на година, което може би е причината за въвеждането на логическата бомба. Последната капка за системния администратор обаче беше бонусът, който получи в размер на $32 000 вместо очакваните $50 000. Когато открива, че бонусът му е много по-малък от очакваното, Дуронио настоява шефът му да предоговори трудовия си договор на 175 000 долара годишно или ще напусне компанията. Отказано му е увеличение на заплатата, а също така е помолен да напусне сградата на банката. Като отмъщение за такова отношение, Дуронио реши да използва своето „изобретение“, въведено предварително, предвиждайки такъв обрат на събитията.
Дуронио внедри „логическата бомба“ от домашния си компютър няколко месеца преди да получи това, което смяташе за твърде малък бонус. Логическата бомба беше инсталирана на около 1500 компютъра в мрежа от клонове в цялата страна и настроена на точно определен час - 9.30, точно навреме за началото на банковия ден.
Дуронио подаде оставка от UBS Paine Webber на 22 февруари 2002 г., а на 4 март 2002 г. логическа бомба последователно изтри всички файлове на главния сървър на централната база данни и 2000 сървъра в 400-те клона на банката, като същевременно деактивира системата за архивиране.
По време на процеса адвокатът на Дуронио посочи, че виновникът за инцидента не може да бъде само обвиняемият: предвид несигурността на ИТ системите на UBS Paine Webber, всеки друг служител би могъл да стигне до там под името на Дуронио. Проблемите с ИТ сигурността в банката станаха известни още през януари 2002 г.: по време на одит беше установено, че 40 души от ИТ службата могат да влязат в системата и да получат администраторски права с една и съща парола и да разберат кой точно го е направил или друго действие не беше възможно. Адвокатът също обвини UBS Paine Webber и компанията @Stake, наета от банката да разследва инцидента, че са унищожили доказателства за атаката. Неопровержимото доказателство за вината на Дуронио обаче бяха частите от злонамерен код, намерени в домашните му компютри, и отпечатано копие на кода в гардероба му.
Вътрешни възможности
Като един от системните администратори на компанията, Дуронио получи отговорност за и достъп до цялата компютърна мрежа UBS PaineWebber. Освен това е имал достъп до мрежата от домашния си компютър чрез защитена интернет връзка.
причини
Както беше посочено по-рано, мотивите му бяха пари и отмъщение. Дуронио получи годишна заплата от $125 000 и бонус от $32 000, докато очакваше $50 000 и така отмъсти за разочарованието си.
Освен това Дуронио реши да спечели пари от атаката: очаквайки спад в акциите на банката поради ИТ катастрофа, той направи фючърсна поръчка за продажба, за да получи разликата, когато курсът падне. Подсъдимият е похарчил 20 000 долара за това. Ценните книжа на банката обаче не паднаха, а инвестициите на Дуронио не се изплатиха.
Последствия
„Логическата бомба“, поставена от Дуронио, спря работата на 2000 сървъра в 400 фирмени офиса. Според ИТ мениджъра на UBS Paine Webber Елвира Мария Родригес това е катастрофа „10 плюс по скала от 10“. В компанията цареше хаос, който отне почти ден да елиминира 200 инженери от IBM. Общо около 400 специалисти са работили за коригиране на ситуацията, включително ИТ службата на самата банка. Щетите от инцидента се оценяват на 3,1 милиона долара. Осем хиляди брокери в цялата страна бяха принудени да спрат работа. Някои от тях успяха да се върнат към нормални операции след няколко дни, някои след няколко седмици, в зависимост от това колко силно са били засегнати техните бази данни и дали банковият клон разполага с резервни копия. Като цяло банковите операции бяха възобновени в рамките на няколко дни, но някои сървъри никога не бяха напълно възстановени, до голяма степен поради факта, че 20% от сървърите нямаха резервни съоръжения. Само година по-късно целият сървърен парк на банката отново е напълно възстановен.
По време на процеса срещу Дуронио в съда той беше обвинен в следните обвинения:
Измами с ценни книжа – Това обвинение носи максимално наказание от 10 години във федерален затвор и глоба от 1 милион долара;
Компютърна измама - Това обвинение носи максимално наказание от 10 години затвор и глоба от $250 000.
В резултат на процеса в края на декември 2006 г. Дуронио беше осъден на 97 месеца без замяна.
"Вимпелком" и "Шерлок"
анотация
С цел печалба бивши служители на компанията VimpelCom (търговска марка Beeline) предлагаха подробности за телефонни разговори на мобилни оператори чрез уебсайта.
Описание на инцидента
Служители на компанията VimpelCom (бивши и настоящи) организираха уебсайта www.sherlok.ru в Интернет, за който компанията VimpelCom научи през юни 2004 г. Организаторите на този сайт предложиха услуга - търсене на хора по фамилия, телефонен номер и други данни. През юли организаторите на сайта предложиха нова услуга - детайлизиране на телефонни разговори на мобилни оператори. Детайлизирането на разговорите е разпечатка на номерата на всички входящи и изходящи разговори, посочваща продължителността на разговорите и тяхната цена, използвана от операторите, например за таксуване на абонати. Въз основа на тези данни можем да направим заключение за текущите дейности на абоната, неговата сфера на интереси и кръг от познати. От прессъобщението на дирекция „К” на МВР (наричано по-нататък МВР) се уточнява, че подобна информация струва на клиента 500 долара.
Служители на компанията VimpelCom, след като откриха този сайт, независимо събраха доказателства за престъпната дейност на сайта и прехвърлиха случая на Министерството на вътрешните работи. Служители на Министерството на вътрешните работи образуваха наказателно дело и съвместно с компанията VimpelCom установиха самоличността на организаторите на този престъпен бизнес. А на 18 октомври 2004 г. главният заподозрян 1 е задържан на местопрестъплението.
Освен това на 26 ноември 2004 г. бяха задържани останалите шестима заподозрени, включително трима служители на абонатната служба на самата компания VimpelCom. По време на разследването се оказа, че сайтът е създаден от бивш студент на Московския държавен университет, който не е работил в тази компания.
Документацията по този инцидент стана възможна благодарение на решението на Конституционния съд от 2003 г., което призна, че подробностите за разговорите съдържат тайна на телефонните разговори, защитена от закона.
Вътрешни възможности
Двама от служителите на VimpelCom, идентифицирани сред участниците в инцидента, са работили като касиери в компанията, а третият е бивш служител и е работил на Митински пазар по време на престъплението.
Работата като касиери в самата компания показва, че тези служители са имали пряк достъп до информацията, предлагана за продажба на уебсайта www.sherlok.ru. Освен това, тъй като бивш служител на компанията вече е работил на пазара Митински, може да се предположи, че с течение на времето този пазар може да се превърне в един от каналите за разпространение на тази информация или всяка друга информация от базите данни на компанията VimpelCom.
Последствия
Основните последици за VimpelCom от този инцидент могат да бъдат удар върху репутацията на самата компания и загуба на клиенти. Този инцидент обаче стана публичен директно благодарение на активните действия на самата компания.
В допълнение, оповестяването на тази информация може да има отрицателно въздействие върху клиентите на VimpelCom, тъй като детайлите на разговорите ни позволяват да направим заключение за текущата дейност на абоната, неговата сфера на интереси и кръг от познати.
През март 2005 г. Останкинският районен съд на Москва осъди заподозрените, включително трима служители на компанията VimpelCom, на различни глоби. Така организаторът на групата беше глобен с 93 000 рубли. Работата на уебсайта www.sherlok.ru обаче беше спряна за неопределено време едва от 1 януари 2008 г.
Най-голямото изтичане на лични данни в историята на Япония
анотация
През лятото на 2006 г. се случи най-голямото изтичане на лични данни в историята на Япония: служител на гиганта за печат и електроника Dai Nippon Printing открадна диск с лична информация на почти девет милиона граждани.
Описание на инцидента
Японската компания Dai Nippon Printing, специализирана в производството на печатни продукти, допусна най-голямото изтичане в историята на страната си. Хирофуми Йокояма, бивш служител на един от контрагентите на компанията, копира лични данни на клиенти на компанията на мобилен твърд диск и ги открадва. Общо 8,64 милиона души бяха изложени на риск, тъй като откраднатата информация включваше имена, адреси, телефонни номера и номера на кредитни карти. Откраднатата информация включва информация за клиенти от 43 различни компании, като 1 504 857 клиенти на American Home Assurance, 581 293 клиенти на Aeon Co и 439 222 клиенти на NTT Finance.
След кражбата на тази информация, Хирофуми започва търговия с частна информация в части от 100 000 записа. Благодарение на стабилния доход вътрешният човек дори напусна постоянната си работа. До момента на задържането си Хирофуми е успял да продаде данните на 150 000 клиенти на най-големите кредитни компании на група измамници, специализирани в онлайн покупки. Освен това някои от данните вече са използвани за измами с кредитни карти.
Повече от половината организации, чиито клиентски данни са били откраднати, дори не са били предупредени за изтичането на информация.
Последствия
В резултат на този инцидент загубите на гражданите, потърпевши от измами с кредитни карти, които станаха възможни само в резултат на това изтичане, възлизат на няколко милиона долара. Общо клиенти на 43 различни компании бяха засегнати, включително Toyota Motor Corp., American Home Assurance, Aeon Co и NTT Finance. Повече от половината организации обаче дори не са били предупредени за изтичането.
През 2003 г. Япония прие Закона за защита на личната информация от 2003 г. (PIPA), но прокурорите не успяха да го приложат в действителния процес на делото в началото на 2007 г. Прокуратурата не успя да обвини вътрешния човек в нарушаване на PIPA. Той е обвинен само в кражба на твърд диск на стойност 200 долара.
Не се оценява. Хакер от Запорожие срещу украинска банка
анотация
Бивш системен администратор на една от големите банки в Украйна прехвърли около 5 милиона гривни през банката, в която преди това е работил, от сметката на регионалната митница към сметката на несъществуваща фалирала компания в Днепропетровск.
Описание на инцидента
Кариерата му като системен администратор започва, след като завършва техникум и е назначен в една от големите банки в Украйна в отдел софтуер и хардуер. След известно време ръководството забелязва таланта му и решава, че той ще бъде по-полезен за банката като ръководител на отдел. Пристигането на ново ръководство в банката обаче доведе и до кадрови промени. Той беше помолен временно да освободи поста си. Скоро новото ръководство започна да сформира своя екип, но талантът му се оказа непотърсен и му беше предложена несъществуващата позиция на заместник-началник, но в друг отдел. В резултат на такива промени в персонала той започна да прави нещо съвсем различно от това, което знаеше най-добре.
Системният администратор не можа да се примири с това отношение на ръководството към себе си и подаде оставка по собствено желание. Той обаче беше преследван от собствената си гордост и негодувание към ръководството, освен това искаше да докаже, че е най-добрият в бизнеса си и да се върне в отдела, където започна кариерата му.
След като подаде оставка, бившият системен администратор реши да върне интереса на предишното ръководство към него, като използва несъвършенствата на системата „Банка-клиент“, използвана в почти всички банки в Украйна 2 . Планът на системния администратор беше да реши да разработи своя собствена програма за сигурност и да я предложи на банката, като се върне на предишното си работно място. Изпълнението на плана се състоеше в проникване в системата Банка-Клиент и извършване на минимални промени в нея. Цялото изчисление беше направено на базата на факта, че банката щеше да открие системен хак.
За да проникне в посочената система, бившият системен администратор е използвал пароли и кодове, които е научил при работа с тази система. Цялата друга информация, необходима за хакване, е получена от различни хакерски сайтове, където са описани подробно различни случаи на хакване на компютърни мрежи, хакерски техники и целия софтуер, необходим за хакване.
След като създаде вратичка в системата, бившият системен администратор периодично проникваше в компютърната система на банката и оставяше различни знаци в нея, опитвайки се да привлече вниманието към фактите за хакване. Банковите специалисти трябваше да засекат хака и да алармират, но за негова изненада никой дори не забеляза проникването в системата.
Тогава системният администратор реши да промени плана си, като направи корекции в него, които не можеха да останат незабелязани. Той решил да фалшифицира платежно нареждане и да го използва за прехвърляне на голяма сума през компютърната система на банката. Използвайки лаптоп и мобилен телефон с вграден модем, системният администратор прониква в компютърната система на банката около 30 пъти: преглежда документи, клиентски сметки, парични потоци - в търсене на подходящи клиенти. Като такива клиенти той избра регионалната митница и фалиралата компания в Днепропетровск.
След като отново получи достъп до системата на банката, той създаде платежно нареждане, в което изтегли 5 милиона гривни от личната сметка на регионалната митница и ги прехвърли през банката по сметката на фалиралата компания. Освен това той целенасочено допусна няколко грешки в „плащането“, което от своя страна трябваше допълнително да помогне за привличане на вниманието на банковите специалисти. Но дори и такива факти не бяха забелязани от банковите специалисти, обслужващи системата Банка-клиент, и те спокойно преведоха 5 милиона гривни по сметката на несъществуваща компания.
В действителност системният администратор е очаквал, че средствата няма да бъдат прехвърлени, че фактът на хакване ще бъде открит преди прехвърлянето на средствата, но на практика всичко се оказа различно и той стана престъпник, а фалшивият му превод ескалира в кражба.
Фактът на хакване и кражба на средства в особено големи размери беше открит само няколко часа след превода, когато банкови служители се обадиха на митницата, за да потвърдят превода. Но съобщиха, че никой не е превеждал такава сума. Парите спешно са върнати в банката, а в прокуратурата на Запорожка област е образувано наказателно дело.
Последствия
Банката не е претърпяла никакви загуби, тъй като парите са върнати на собственика, а компютърната система е получила минимални щети, в резултат на което ръководството на банката е отказало всякакви претенции към бившия системен администратор.
През 2004 г. с указ на президента на Украйна наказателната отговорност за компютърни престъпления беше засилена: глоби от 600 до 1000 необлагаеми минимума, лишаване от свобода от 3 до 6 години. Бившият системен администратор обаче е извършил престъпление преди президентският указ да влезе в сила.
В началото на 2005 г. се проведе процес срещу системния администратор. Той е обвинен в извършване на престъпление по част 2 на член 361 от Наказателния кодекс на Украйна - незаконна намеса в работата на компютърни системи, причиняваща вреда и по част 5 на член 185 - кражба, извършена в особено големи размери. Но тъй като ръководството на банката отказа да предяви претенции срещу него, обвинението за кражба беше свалено от него и част 2 от член 361 беше променена на част 1 - незаконна намеса в работата на компютърни системи.
Безконтролна търговия в банка Societe Generale
анотация
На 24 януари 2008 г. Societe Generale обяви загуба от 4,9 милиарда евро поради машинациите на своя търговец Jerome Kerviel. Както показа вътрешно разследване, в продължение на няколко години търговецът отваря позиции над лимита във фючърси за европейски фондови индекси. Общият размер на отворените позиции възлиза на 50 милиарда евро.
Описание на инцидента
От юли 2006 г. до септември 2007 г. системата за вътрешен контрол на компютъра издаде предупреждение за възможни нарушения 75 пъти (това е колко пъти Джеръм Кервиел извърши неразрешени транзакции или позициите му надвишиха допустимия лимит). Служители от отдела за мониторинг на риска на банката не са извършвали подробни проверки на тези предупреждения.
Кервиел за първи път започна да експериментира с неразрешена търговия през 2005 г. Тогава той зае къса позиция за акциите на Allianz, очаквайки пазарът да падне. Скоро пазарът наистина падна (след терористичните атаки в Лондон), така бяха спечелени първите 500 000 евро. По-късно Кервиел разказа на разследващите за чувствата си от първия си успех: „Вече знаех как да затворя позицията си и бях горд от резултата, но в същото време бях изненадан. Успехът ме накара да продължа, беше като снежна топка... През юли 2007 г. предложих да заема къса позиция в очакване на спад на пазара, но не получих подкрепа от моя мениджър. Прогнозата ми се сбъдна и спечелихме, този път напълно законно. Впоследствие продължих да извършвам подобни операции на пазара или със съгласието на началството, или при липса на изричното му възражение... Към 31 декември 2007 г. печалбата ми достигна 1,4 млрд. евро. В този момент не знаех как да декларирам това в моята банка, тъй като беше много голяма сума, която не беше декларирана никъде. Бях щастлив и горд, но не знаех как да обясня на моето ръководство получаването на тези пари и да не си навлека подозрение за извършване на неразрешени транзакции. Затова реших да скрия печалбата си и да проведа обратната фиктивна операция...”
Всъщност в началото на януари същата година Джеръм Кервиел отново влезе в играта с фючърсни договори за трите индекса Euro Stoxx 50, DAX и FTSE, което му помогна да победи пазара в края на 2007 г. (въпреки че той предпочете да сключи къси позиции на време). Според изчисленията в навечерието на 11 януари портфейлът му е съдържал 707,9 хиляди фючърса (всеки на стойност 42,4 хиляди евро) на Euro Stoxx 50, 93,3 хиляди фючърса (192,8 хиляди евро за 1 брой) на DAX и 24,2 хиляди фючърса (82,7 хиляди евро). за 1 договор) за индекса FTSE. Общо спекулативната позиция на Кервиел се равняваше на 50 милиарда евро, тоест повече от стойността на банката, в която той работеше.
Знаейки времето на чековете, той отвори фиктивна хеджираща позиция в точния момент, която по-късно затвори. В резултат на това рецензентите никога не са виждали нито една позиция, която може да се счита за рискована. Те не могат да бъдат разтревожени от големите количества транзакции, които са доста често срещани на индексния фючърсен пазар. Той бил подведен от фиктивни транзакции, извършвани от сметки на клиенти на банката. Използването на сметки на различни банкови клиенти не доведе до видими за контрольорите проблеми. С течение на времето обаче Kerviel започна да използва едни и същи клиентски акаунти, което доведе до „ненормална“ активност, наблюдавана в тези акаунти и на свой ред привлече вниманието на администраторите. Това беше краят на измамата. Оказа се, че партньор на Кервиел в многомилиардната сделка е голяма германска банка, която уж е потвърдила астрономическата сделка по имейл. Електронното потвърждение обаче породи съмнения сред инспекторите и в Societe Generale беше създадена комисия, която да ги провери. На 19 януари, в отговор на запитване, германската банка не призна тази транзакция, след което търговецът се съгласи да признае.
Когато беше възможно да се установи астрономическият размер на спекулативната позиция, главният изпълнителен директор и председател на борда на директорите на Societe Generale Даниел Бутон обяви намерението си да затвори рисковата позиция, открита от Кервиел. Това отне два дни и доведе до загуби от 4,9 милиарда евро.
Вътрешни възможности
Джером Кервиел е работил пет години в т. нар. бек офис на банката, тоест в отдел, който не сключва директно сделки. Занимава се само с осчетоводяване, изпълнение и регистрация на сделки и следи търговците. Тази дейност ни позволи да разберем характеристиките на системите за контрол в банката.
През 2005 г. Кервиел е повишен. Той стана истински търговец. Непосредствените отговорности на младия мъж включваха основни операции за минимизиране на рисковете. Работейки на фючърсния пазар за европейски фондови индекси, Джером Кервиел трябваше да наблюдава как се променя инвестиционният портфейл на банката. И основната му задача, както обясни един представител на Societe Generale, беше да намали рисковете, като играе в обратната посока: „Грубо казано, виждайки, че банката залага на червено, той трябваше да заложи на черно.“ Като всички младши търговци, Кервиел имаше лимит, който не можеше да превиши, който се наблюдаваше от бившите му колеги в бек офиса. Societe Generale имаше няколко нива на защита, например търговците можеха да отварят позиции само от работния си компютър. Всички данни за отваряне на позиции се предават автоматично в реално време към бек офиса. Но, както се казва, най-добрият бракониер е бившият лесовъд. А банката направи непростима грешка, като постави бившия лесничей в позицията на ловец. Джером Кервиел, който имаше почти пет години опит в наблюдението на търговците, не намери за трудно да заобиколи тази система. Той знаеше паролите на други хора, знаеше кога се извършват проверки в банката и беше добре запознат с информационните технологии.
причини
Ако Кервиел е бил замесен в измама, това не е било с цел лично обогатяване. Това казват неговите адвокати, а представители на банката също признават това, наричайки действията на Кервиел ирационални. Самият Кервиел казва, че е действал единствено в интерес на банката и е искал само да докаже таланта си на търговец.
Последствия
В края на 2007 г. дейността й е донесла на банката около 2 млрд. евро печалба. Във всеки случай това казва самият Кервиел, твърдейки, че ръководството на банката вероятно е знаело какво прави, но е предпочело да си затваря очите, стига да е печеливш.
Затварянето на рисковата позиция, открита от Kerviel, доведе до загуби от 4,9 милиарда евро.
През май 2008 г. Daniel Bouton напусна поста главен изпълнителен директор на Societe Generale и беше заменен на тази позиция от Frédéric Oudea. Година по-късно той е принуден да напусне поста си на председател на борда на директорите на банката. Причината за напускането му бяха остри критики от пресата: Бутон беше обвинен във факта, че висшите мениджъри на банката под негов контрол насърчават рискови финансови транзакции, извършвани от банкови служители.
Въпреки подкрепата на борда на директорите, натискът върху г-н Бутон се увеличи. Акционерите на банката и много френски политици поискаха оставката му. Френският президент Никола Саркози също призова Даниел Бутон да подаде оставка, след като стана известно, че през година и половина преди скандала компютърната система за вътрешен контрол на Societe Generale е издала предупреждение 75 пъти, т.е. .
Веднага след откриването на загубите Societe Generale създаде специална комисия за разследване на действията на търговеца, която включваше независими членове на борда на директорите на банката и одитори PricewaterhouseCoopers. Комисията заключи, че системата за вътрешен контрол на банката не е достатъчно ефективна. Това доведе до невъзможност на банката да предотврати такава мащабна измама. В доклада се посочва, че „служителите на банката не са извършвали систематични проверки“ на дейността на търговеца, а самата банка не е имала „система за контрол, която да предотврати измами“.
В доклада за резултатите от одита на търговеца се посочва, че след резултатите от разследването е взето решение за „значително засилване на процедурата за вътрешен надзор върху дейността на служителите на Societe Generale“. Това ще стане чрез по-строга организация на работата на отделните звена на банката и координиране на взаимодействието им. Ще бъдат предприети и мерки за проследяване и персонализиране на търговските операции на банковите служители чрез „укрепване на системата за ИТ сигурност и разработване на високотехнологични решения за персонална идентификация (биометрия)“.
От книгата Осигуряване на сигурност на бизнес информацията автор Андрианов В.В.4.2.2. Типология на инцидентите Обобщението на световната практика ни позволява да идентифицираме следните видове инциденти на информационната сигурност, включващи персонал на организацията: - разкриване на официална информация; - фалшифициране на отчети; - кражба на финансови и материални активи; - саботаж
От книгата Пенсия: процедура за изчисляване и регистрация автор Минаева Любов Николаевна4.3.8. Разследване на инцидент Инцидент, в който е замесен служител на организация, е спешен случай за повечето организации. Следователно начинът, по който се организира едно разследване, силно зависи от съществуващата корпоративна култура на организацията. Но можете уверено
От книгата Дневна търговия на Форекс пазара. Стратегии за печалба от Лин Кети2.5. Примери Нека разгледаме някои възможности за назначаване на трудови пенсии в случай на прехвърляне на документи до териториалните органи на Пенсионния фонд по пощата: Пример 1 Заявление за назначаване на трудова пенсия за старост е изпратено до териториалния орган на фонда
От книгата Практика на управление на човешките ресурси автор Армстронг Майкъл3.5. Примери Пример 1 Трудовият стаж се състои от периоди на работа от 15 март 1966 г. до 23 май 1967 г.; от 15.09.1970 г. до 21.05.1987 г.; от 01.01.1989 г. до 31.12.1989 г.; от 04.09.1991 г. до 14.07.1996 г.; от 15.07.1996 г. до 12.07.1998 г. и военна служба от 27.05.1967 г. до 09.06.1969 г. Нека изчислим трудовия стаж, за да оценим пенсионните права
От книгата на автора4.4. Примери Пример 1 Инженер Сергеев А.П., роден през 1950 г., кандидатства за пенсия за старост през март 2010 г. През 2010 г. той навърши 60 години. Общият стаж за определяне на правото на пенсия към 1 януари 2002 г. е 32 години, 5 месеца и 18 дни, включително 30 години преди 1991 г.
От книгата на автора6.3. Примери Пример 1 Мениджър продажби В. Н. Соколов работи по трудов договор от 1 януари 2010 г. На 1 януари 2013 г. той умира на 25 години. В същото време той все още има дееспособни родители, дееспособна съпруга и дъщеря на 3 години. В този случай правото на получаване на труд
От книгата на автора7.4. Примери Пример 1 Управител Василиев Р.С., 60 години. Общият стаж по трудовата книжка за определяне на пенсионните права към 1 януари 2002 г. е 40 години. Средната месечна печалба за 2000-2001 г., според персонализираните счетоводни данни, е 4000 рубли. Ще изчислим и сравним размерите на пенсиите според
От книгата на автора8.3. Примери Пример 1 Пенсионер получава пенсия за инвалидност от I група. От 20 май до 5 юни 2009 г. той е подложен на повторен преглед в BMSE и е признат за III група инвалидност на 3 юни 2009 г. Групата инвалидност в този случай намалява. Основната част от пенсията подлежи на
От книгата на автора10.4. Примери Пример 1 Смъртта на пенсионер е настъпила на 28 януари 2009 г. Вдовицата на пенсионера е подала молба за пенсия през февруари 2009 г. Не е установено съжителството на вдовицата с пенсионера към деня на смъртта.В това пенсионно дело териториалният орган на гр. фондът прие
От книгата на автора14.7. Примери Пример 1 Кошкина V.N., която е била на издръжка на починалия си съпруг, навършва 55 години 3 месеца след смъртта му. Кандидатствах за пенсия след 1 година от датата на смъртта на моя съпруг.Съгласно пенсионното законодателство пенсията ще бъде назначена от датата
От книгата на автора17.5. Примери Пример 1 Индивидуален предприемач наема четирима души по трудов договор: Мороз К. В. (р. 1978 г.), Светлова Т. Г. (р. 1968 г.), Леонова Т. Н. (р. 1956 г.) и Комаров С. Н. (р. 1952 г.). Да предположим, че месечната заплата на всеки от тях е 7000 рубли.
От книгата на автораПримери Нека да разгледаме някои примери за това как работи тази стратегия: 1. 15-минутна графика на EUR/USD на фиг. 8.8. Съгласно правилата на тази стратегия виждаме, че EUR/USD пада и се търгува под 20-дневната пълзяща средна. Цените продължиха да се понижават, движейки се към 1.2800, което е
От книгата на автораПримери Нека проучим няколко примера.1. На фиг. Фигура 8.22 показва 15-минутна графика на USD/CAD. Общият обхват на канала е приблизително 30 точки. В съответствие с нашата стратегия, ние поставяме поръчки за влизане 10 пункта над и под канала, т.е. при 1.2395 и 1.2349. Поръчката за покупка е изпълнена
От книгата на автораПримери Нека да разгледаме някои примери за тази стратегия в действие.1. На фиг. Фигура 8.25 показва дневната графика на EUR/USD. На 27 октомври 2004 г. пълзящите средни EUR/USD формираха постоянен правилен ред. Отваряме позиция пет свещи след началото на формирането при 1.2820.
С нарастването на ролята на ИТ в една компания нараства и необходимостта от осигуряване на добро ниво на обслужване и осигуряване на максимална достъпност на ИТ услугите. Бизнес потребителят трябва да може да получи решения на проблемите си, ако възникнат възможно най-бързо и да работят по всяко време. Внедряване на процеси управление на инцидентии проблемите са насочени именно към това. В тази статия описваме как може да се организира работата на ИТ услуга в рамките на управление на инцидентии проблеми. Това описание се основава на ITIL предложения и опита на нашите клиенти.
Езикът на случките и проблемите
ITIL Service Support е световно признат модел. Базира се на най-добрите практики и се използва за насочване на ИТ организациите при разработването на подходи за управление на услугите. Този модел е обещаващ. Той също така определя допълнителни елементи, необходими за успешното функциониране на една ИТ организация като бизнес с услуги. Той предоставя технически речник за дискусии в бюрото за помощ, дефинира концепции и подчертава разликите между различните дейности. Например дейностите, необходими за реагиране на прекъсвания на услугата и тяхното възстановяване, са различни от дейностите, необходими за намиране и отстраняване на причините за прекъсвания на услугата.
Инциденти
Инцидент- всяко събитие, което не е част от стандартните операции на услугата и причинява или може да причини прекъсване на услугата или намаляване на качеството на услугата.
Примери за инциденти са:
- Потребителят не може да получава имейл
- Инструментът за наблюдение на мрежата показва, че комуникационният канал скоро ще се запълни
- Потребителят усеща, че приложението се забавя
проблеми
проблем— има неизвестна причина за един или повече инциденти Един проблем може да породи няколко инцидента.
Грешки
Известна грешка— има инцидент или проблем, за който е установена причината и е разработено решение за заобикалянето или отстраняването му. Грешките могат да бъдат идентифицирани чрез анализ на потребителски оплаквания или анализ на системи.
Примерите за грешки включват:
- Неправилна компютърна мрежова конфигурация
- Инструментът за наблюдение неправилно определя състоянието на канала, когато рутерът е зает
Съотношение на понятията управление на инциденти и проблемите са показани на фигура 1. Инцидентите, проблемите и известните грешки са свързани в един вид жизнен цикъл: инцидентите често са индикатори за проблеми ⇒ идентифицирането на причината за проблема идентифицира грешката ⇒ грешките след това се коригират систематично.
- има дейност за възстановяване на нормалното обслужване с минимални закъснения и въздействие върху бизнес операциите, което е реактивна, краткосрочно фокусирана услуга за възстановяване.
Включва:
- Откриване и запис на инциденти
- Класификация и първоначална поддръжка
- Изследване и диагностика
- Решение и възстановяване
- Затваряне
- Собственост, наблюдение, проследяване и комуникация
Управление на проблеми
Управление на проблеми — има дейности за минимизиране на въздействието върху бизнеса на проблеми, причинени от грешки в ИТ инфраструктурата, за предотвратяване на повторение на инциденти, свързани с такива грешки. Управлението на проблеми идентифицира причините за проблемите и идентифицира заобиколни решения или решения.
Управлението на проблеми включва:
- Контрол на проблемите
- Контрол на грешките
- Предотвратяване на проблеми
- Анализ на основните проблеми
Контрол на проблемите
Целта на контрола на проблема— открийте причината за проблема, като следвате тези стъпки:
- Идентифициране и регистриране на проблеми
- Класификация на проблемите и приоритизиране на техните решения
- Изследване и диагностика на причините
Контрол на грешките
Контролът на грешките гарантира, че проблемите се коригират чрез:
- Идентифициране и регистриране на известни грешки
- Оценяване на средствата за защита и тяхното приоритизиране
- Регистрация за временно решение в инструментите за поддръжка
- Затваряне на известни проблеми чрез прилагане на корекции
- Наблюдавайте известни грешки, за да определите необходимостта от повторно приоритизиране
Анализ на проблема
Цел на анализа на проблемае да се подобрят процесите управление на инцидентии управление на проблеми. Какво се постига чрез изследване на качеството на резултатите от дейностите по отстраняване на големи проблеми и аварии.
Организационни роли и разпределение на отговорностите
Най-разпространената структура на системата за поддръжка е модел на нива, в който се прилагат нарастващи нива на технически възможности за разрешаване на инцидент или проблем. Действителните роли и отговорности, използвани при внедряването на многостепенна система за поддръжка, може да варират в зависимост от персонала, историята и политиките на конкретната организация. Въпреки това, следното описание на многостепенна система за поддръжка е типично за много организации.
Първо ниво на поддръжка
Организацията (подразделението), представляваща първото ниво на поддръжка, обикновено се отнася до оперативните услуги. По правило се нарича диспечерска служба, Call Center, Service Desk.
Роли. Собственик на процеса
Първото ниво на поддръжка гарантира, че е установен и поддържан добре дефиниран, последователно изпълняван, подходящо измерен, ефективен процес. управление на инциденти. Получавайте и управлявайте всички проблеми с обслужването на клиенти. Първото ниво на поддръжка е единствената точка за контакт за ескалиране на проблеми с услугата и действа като защитник на крайния потребител, за да гарантира, че проблемите с услугата се разрешават своевременно.
Първа линия на поддръжка
Организацията за поддръжка от първо ниво прави първия опит да разреши проблема с услугата, докладван от крайния потребител.
Отговорности
- Гарантирано е, че картата на инцидента съдържа точно и достатъчно подробно описание на проблема
- Правилният избор на важност/приоритет на инцидента е гарантиран
- Определят се естеството на проблема, потребителските контакти, въздействието върху бизнеса и очакваното време за разрешаване
Собственост на всеки инцидент.Като защитник на крайния потребител, първото ниво на поддръжка гарантира, че всеки инцидент е разрешен успешно. Това гарантира своевременно разрешаване на проблеми чрез:
- Разработване и управление на план за действие за разрешаване на проблема
- Иницииране на конкретни задачи за служители и бизнес партньори
- Ескалирайте инцидента, ако е необходимо, когато целта не е постигната навреме
- Осигурете вътрешна комуникация в съответствие с целите на услугата
- Защита на интересите на участващите бизнес партньори
Първото ниво на поддръжка използва база данни за управление на проблеми, за да съпостави инциденти с известни грешки и да приложи по-рано открити решения за инциденти. Целта е 80 процента от инцидентите да бъдат разрешени. Останалите инциденти се прехвърлят (ескалират) на второ ниво.
Непрекъснато подобряване на процеса на управление на инциденти.Като собственик на даден процес, първото ниво на поддръжка гарантира, че процесът се подобрява, когато е необходимо чрез:
- Оценете ефективността на процеса и механизмите за поддръжка като отчети, видове комуникация и формати на съобщения, процедури за ескалация
- Разработване на специфични за отдела отчети и процедури
- Поддържайте и подобрявайте комуникацията и списъците за ескалация
- Участие в процеса на анализ на проблема
Точно записване на инциденти.Първото ниво на поддръжка гарантира, че информацията за инцидента се записва в системния регистър. За това трябва да има:
Способности и умения
Междуличностните умения са от първостепенно значение.Поддържащият персонал от първо ниво участва предимно в приоритизирането и управлението на проблеми. На това ниво на поддръжка се извършват само малки технически изследвания. Възможност за прилагане на „консервирани“ решения. Персоналът от първо ниво трябва да може да разпознава симптомите, да използва инструменти за търсене, за да открие предварително разработени решения и да подпомага крайните потребители при прилагането на такива решения.
Второ ниво на поддръжка
Това ниво обикновено се отнася и за оперативни услуги.
Роли
- Разследване на инцидента.Второто ниво на поддръжка проучва, диагностицира и разрешава повечето инциденти, които не са разрешени на първото ниво. Тези инциденти обикновено показват нови проблеми.
- Собственик на процеса за управление на проблеми.Второто ниво на поддръжка гарантира, че е налице добре дефиниран и ефективен процес за управление на проблеми.
- Проактивно управление на инфраструктурата.Второто ниво на поддръжка използва инструменти и процеси, за да гарантира, че проблемите са идентифицирани и разрешени преди възникването на инциденти.
Отговорности
- Разрешаване на инциденти, отнесени от първо ниво.Ако първото ниво на поддръжка се очаква да разреши 80% от инцидентите, то второто ниво на поддръжка се очаква да разреши 75% от инцидентите, посочени от първото ниво, тоест 15% от броя на докладваните инциденти. Останалите инциденти се прехвърлят на трето ниво.
- Определяне на причините за проблемите.Второто ниво на поддръжка идентифицира причините за проблемите и предлага заобиколни решения или решения. Те ангажират и управляват други ресурси, ако е необходимо, за да определят причините. Разрешаването на проблеми ескалира до трето ниво, когато причината е архитектурен или технически проблем, който надхвърля нивото на техните умения.
- Уверете се, че поправките и проблемите са разрешени.Второто ниво на поддръжка гарантира, че проектите са инициирани в рамките на организациите за развитие за изпълнение на планове за разрешаване на известни проблеми. Те гарантират, че намерените решения са документирани, съобщени на персонал от първо ниво и внедрени в инструменти.
- Постоянно наблюдение на инфраструктурата.Второто ниво на поддръжка се опитва да идентифицира проблемите, преди да възникнат инциденти, като наблюдава компонентите на инфраструктурата и предприема коригиращи действия, когато бъдат открити дефекти или погрешни тенденции.
- Проактивен анализ на тенденциите при инциденти.Инцидентите, които вече са се случили, се разглеждат, за да се определи дали показват проблеми, които трябва да бъдат коригирани, за да се предотврати тяхното причиняване на нови инциденти. Тези инциденти, които са затворени и не са свързани с известни проблеми, се проверяват за потенциални проблеми.
- Непрекъснато подобряване на процеса на управление на проблеми.Като собственик на процеса за управление на проблеми, второто ниво на поддръжка гарантира, че процесът и съществуващите възможности са адекватни и ги подобрява, когато е необходимо. Те провеждат сесии за анализ на проблеми, за да идентифицират извлечените поуки и да гарантират, че контролите на процесите, като срещи и доклади, са адекватни.
Способности и умения
- Технически компетентен с разумни комуникационни умения.Обслужващият персонал от второ ниво трябва да притежава набор от технически умения във всички поддържани технологии, включително мрежи, сървъри и приложения. Често срещан дефицит в организациите от второ ниво е познаването на операционни системи и приложения. Не трябва да има значителна разлика между организациите от второ и трето ниво. Някои служители от второ ниво трябва да са толкова квалифицирани, колкото служителите от трето ниво.
- Познания за мрежи, сървъри и приложения.Организациите от ниво 2 трябва да могат да разрешават инциденти и проблеми в пълния набор от технологии, използвани в компанията.
Трето ниво на поддръжка
Това ниво на поддръжка обикновено попада в екипа за разработка на приложения и мрежова инфраструктура.
Роли
- Планиране и проектиране на ИТ инфраструктура.Обикновено екипът за поддръжка на трето ниво играе малка роля в управление на инцидентии управление на проблеми, тъй като такива организации се занимават предимно с планиране и проектиране на ИТ инфраструктура. В това си качество тяхната цел е да внедрят бездефектна инфраструктура, която не е източник на проблеми и инциденти.
- Последната граница в ескалацията.Ако инцидентът или проблемът е извън възможностите на екипа за поддръжка от второ ниво, тогава екипът за поддръжка от трето ниво поема отговорност за намирането на решение.
Отговорности
- Разрешаване на инциденти, отнесени от второ ниво.Тъй като повечето инциденти са причинени от известни грешки, много малко инциденти (5%) преминават през второто ниво до третото. Третото ниво отговаря за разрешаването на всички инциденти, които идват при тях.
- Участвайте в дейности за управление на проблеми.Третото ниво на поддръжка е свързано с намиране на причините, заобиколни решения и отстраняване на грешки.
- Прилагане на мерки за отстраняване на грешки от инфраструктурата.Третото ниво има значителна роля в планирането, проектирането и изпълнението на проекти за справяне с недостатъците на инфраструктурата. Изпълнението на тези проекти трябва да се координира с редовните дейности по развитие на инфраструктурата, за да се постигне правилният баланс.
Способности и умения
- Експерти в своите области.Екипите от ниво 3 трябва да бъдат експертите, които планират и проектират ИТ инфраструктурата.
процеси
Има три основни процеса, свързани с управление на инцидентии управление на проблеми:
- процес на управление на инциденти
- процес на контрол на проблема
- процес на контрол на грешките
Тези основни процеси присъстват в почти всички напреднали организации, въпреки че може да имат други имена.
Процес на управление на инциденти
Този процес е насочен към възстановяване на прекъснатата услуга възможно най-бързо. Таблица 1 показва основните параметри на този процес, а фигура 1 показва диаграма на работата му.
|
Параметър на процеса |
Описание |
|---|---|
|
Предназначение |
|
|
Собственик |
|
|
|
|
|
|
Типични числени параметри |
|
Фигура 1. Модел на процеса
Процесът на контрол на проблемите се фокусира върху приоритизирането, разпределянето и наблюдението на усилията за определяне на причините за проблемите и как те да бъдат разрешени временно или постоянно. Този процес може да бъде оприличен на управление на портфолио от проекти, където всеки проблем е проект, който трябва да се управлява в рамките на портфолио от подобни проекти. Основните параметри на проекта за контрол на проблема са показани в таблица 2.
|
Параметър на процеса |
Описание |
|---|---|
|
Предназначение |
|
|
Собственик | |
|
|
|
|
|
Типични числени параметри |
|
Входът към един процес може да дойде от множество източници. Обикновено инцидентите с висока степен на сериозност се ескалират автоматично към процеса на управление на проблеми. В организации със силно второ ниво на поддръжка инцидентите, ескалирани до третото ниво на поддръжка, също рутинно се насочват към процеса за контрол на проблемите. И накрая, ежедневната среща може да пренасочи определени инциденти към процесите за контрол на проблемите. Процесът, който прилага контрол на проблема, е показан на фигура 2.

Фигура 2. Модел на процеса на контрол на проблемите
Фокусът на процеса на контрол на проблема е да се определят причините. Съставът на участниците в анализа на причината и продължителността на времето, необходимо за извършване на такъв анализ, зависи от самия проблем. Следните твърдения могат да се считат за правилни:
- Ако имате достатъчно проблеми, назначете постоянен екип. В противен случай създайте екип, когато възникне проблем, почти по същия начин, както се формира екип за проект;
- Екипът почти винаги трябва да има интердисциплинарен опит и знания. И това разбира се зависи от естеството на проблема;
- При възникване на проблема трябва да се даде оценка на времето за определяне на причината (разработване на план на проекта). Напредъкът на отбора трябва да се измерва спрямо тази оценка.
След като ресурсите са разпределени и приоритизирани, действителната механика за определяне на причината може да приеме много форми. Такива методи за търсене на причини като анализ на Кепнер и Трего, диаграми на Ишикава, диаграми на Парето и др. са се доказали добре.
Мониторингът на грешки осигурява документиране на методи за преодоляване на грешки и уведомяване на обслужващия персонал за тях (методи). Това включва и поддържане на контакт с други технически и развойни организации, което също помага за идентифициране на грешки. Освен това контролът на грешките влияе върху разработчиците да прилагат корекции за известни грешки. Таблица 3 показва основните параметри на процеса на контрол на грешките. Фигура 3 показва модел на процеса на контрол на грешките.
|
Параметър на процеса |
Описание |
|---|---|
|
Предназначение |
|
|
Собственик |
|
|
|
|
|
|
Типични числени параметри |
|

Фигура 3. Модел на процеса за контрол на грешки
Взаимодействия
Обикновено взаимодействията в този процес приемат една от двете форми. Това са или съобщения за състоянието на инцидент или проблем, които се предоставят на различни групи и/или лица въз основа на одобрени правила и шаблони, или съобщения за заявки, които изискват от получателя да предприеме определени действия, обикновено съдържащи в допълнение към действителна заявка/искане, връзка към инцидента, номер, телефонен номер на потребителя или друга връзка към него.
Много компании разчитат на възможностите за автоматизирани съобщения, предоставени от софтуера. Такива съобщения се изпращат съгласно строги правила, за да се поддържа ескалация. Съобщенията за състояние от софтуерните системи обикновено се генерират от данни, въведени в полета на карта за инцидент. Следователно такива съобщения често са непълни и подобни на разбъркване поради факта, че полетата, използвани за конструиране на автоматизирани съобщения, могат да бъдат нередовно актуализирани с навременна информация или автоматично попълнени от софтуер за наблюдение, използващ жаргон за съобщения за грешка.
За да се коригират тези недостатъци, възможностите за автоматична комуникация се допълват, особено в случай на инциденти с висока степен на тежест, с ръчни съобщения.
Ескалация
Механизъм за ескалацияПомага за своевременното разрешаване на инцидент чрез увеличаване на капацитета на персонала, нивото на усилия и приоритета, фокусиран върху разрешаването на инцидента. Най-добрите организации имат добре дефинирани пътища за ескалация с графики и отговорности, ясно дефинирани на всяка стъпка. Използват средства управление на инцидентиза автоматично прехвърляне на отговорността към нарастващи нива на поддръжка в зависимост от времевите ограничения и сложността.
Времевите рамки и отговорностите за ескалация варират значително в зависимост от организацията, индустрията и нивото на сложност на проблемите. Във водещи организации се провеждат дискусии с крайните потребители, за да се определят подходящи времеви рамки и ескалация на отговорностите. Резултатът от такива преговори се прилага под формата на споразумения за ниво на обслужване, автоматизирани инструменти, списъци и шаблони.
Функционална ескалация
Функционална ескалацияима ескалация на инцидент до по-високо ниво на поддръжка, когато знанията или опитът са недостатъчни или договореният времеви интервал е изтекъл. Напредналите организации определят матрица от нива на сериозност въз основа на степента на въздействие върху бизнеса, времевата рамка за разрешаване на инцидента и интервалите от време, в които инцидентът трябва да бъде ескалиран до по-напреднал екип. Таблица 4 представя такава матрица.
В повечето организации групите за поддръжка от първо и второ ниво са фокусирани върху работата на съществуваща инфраструктура, докато третото ниво на поддръжка обикновено се осигурява от групи, които отговарят за планирането на развитието на инфраструктурата и нейния дизайн. Следователно, внимателното планиране на това как отговорността ще бъде функционално прехвърлена на третото ниво е от решаващо значение.
|
Ниво на инцидент |
Описание |
Срок за решение |
Първо ниво |
Първа ескалация |
Втора ескалация |
Трета ескалация |
|---|---|---|---|---|---|---|
|
Повече от 50 потребители не могат да извършват бизнес транзакции |
1-во ниво на поддръжка |
2-ро ниво на поддръжка |
3-то ниво на поддръжка |
1-ви управител Спешна среща |
||
|
10 до 49 потребители не могат да извършват бизнес транзакции |
1-во ниво на поддръжка |
2-ро ниво на поддръжка |
3-то ниво на поддръжка |
1-ви управител Спешна среща |
||
|
1 до 9 потребители не могат да извършват бизнес транзакции |
1-во ниво на поддръжка |
2-ро ниво на поддръжка |
3-то ниво на поддръжка |
1-ви управител |
В напредналите организации обикновено се определя дежурен пейджър. Мениджърът на всяка технологична група е отговорен за изготвянето на график за обработка на повиквания за такива повиквания на пейджър и гарантира, че повикванията се обслужват по всяко време. В допълнение трябва да се дефинира йерархична (управленска) процедура за ескалация за всяка технологична група. Обикновено директният мениджър на екип от трето ниво е първият лидер в ескалацията.
Йерархична ескалация
За да се гарантира, че даден инцидент получава подходящия приоритет и необходимите ресурси са разпределени, преди да бъде надхвърлена времевата рамка за разрешаване, йерархичната ескалация включва управление в процеса. Йерархичната ескалация може да се извърши на всяко ниво на поддръжка. В таблица 4 йерархичната ескалация възниква в третата стъпка на ескалация за проблеми от всички нива на сериозност.
В напредналите организации ескалацията към ръководството става автоматично съгласно предварително дефинирана процедура, базирана на сериозността на проблема. След като възникне ескалация, от подходящия мениджър се очаква активно да управлява разрешаването на проблемите и да стане единствената точка за контакт за съобщения за състоянието.
Отчитане и подобряване на процеса
Статистическите отчети във водещи организации се използват за мониторинг, непрекъснато подобряване на процесите и анализ на показателите за ефективност спрямо нивото на обслужване, договорено с клиентите.
За контрол на процеса управление на инцидентии управлението на проблеми може например да използва отчети, съдържащи стойностите на следните параметри:
- Брой отворени в момента карти с инциденти, разбити по ниво на важност, прекарано време, групи на отговорност
- Брой проблемни карти, отворени в момента (чиято причина все още не е установена)
Такива отчети позволяват на мениджърите да вземат решения относно разпределението на ресурсите и посоката на усилията на персонала. Редовно използване на параметри на типа:
- Средно време за обработка на картата на всяко ниво
- Броят на преминалите и разрешени карти на всяко ниво може да помогне за идентифициране на слабостите в ИТ инфраструктурата
И накрая, жизненоважен набор от отчети, като например:
- Процент на инцидентите, разрешени в рамките на даден период от време
- Средното време за възстановяване на услугата позволява на ИТ организациите да взаимодействат със своите потребители и да съпоставят постигнатото ниво на производителност с целевото ниво на услугата
Заключение
Разработване на процеси и процедури управление на инцидентисе извършва от много организации, но не всички от тези организации правят същото за управление на проблеми. Това често се дължи на липсата на ясно разбиране на характеристиките на тези две дейности. е най-простата дейност за разбиране, защото просто създава механизъм за реагиране на прекъсвания на услугата. Тъй като „скърцащото колело винаги ще има грес“, управлението на инциденти се развива доста бързо. Често обаче има по-малко възможности за развитие на управление на проблеми.
Управлението на проблеми е по-скоро като управление на портфолио от проекти, всеки с цел идентифициране на причината за проблем. Инцидентите често са първият индикатор за проблем и след като се сблъска с инцидент, организацията трябва да разполага с процес и процедури за определяне на причината.
Продължавайки аналогията с портфолиото на проекта, организацията за управление на проблеми трябва да разработи критерий за идентифициране на проблемите, които трябва да бъдат проучени, за да се определят причините, почти по същия начин, както се прави за критерия за вземане на решение за избор на нов проект. Проблеми, които не са проучени, продължават да се наблюдават за бъдещи изследвания. След като се открие причината и се разработи решение, организацията проследява напредъка в прилагането на решението.
Основната причина за инцидент на информационната сигурност е потенциалната способност на нападателя да получи неоправдани привилегии за достъп до актив на организация. Оценката на риска от подобна възможност и вземането на правилно решение за защита е основната задача на екипа за реагиране.
Всеки риск трябва да бъде приоритизиран и третиран в съответствие с политиката за оценка на риска на организацията. Оценката на риска се разглежда като непрекъснат процес, чиято цел е да се постигне приемливо ниво на защита, с други думи, трябва да се въведат достатъчни мерки за защита на актива от неразумна или неоторизирана употреба. Оценката на риска допринася за класификацията на активите. В по-голямата част от случаите активите, които са критични от гледна точка на риска, също са критични за бизнеса на организацията.
Специалистите от екипа за реагиране анализират заплахите и помагат да се поддържа актуален моделът на нарушителя, приет от службата за информационна сигурност на организацията.
За да може екипът за реагиране да работи ефективно, организацията трябва да разполага с процедури за описание на функциониращите процеси на звената. Особено внимание трябва да се обърне на попълването на документната база на услугата за информационна сигурност.
Откриване и анализ на инциденти в информационната сигурност
Инцидентите със сигурността на информацията могат да имат различни източници на произход. В идеалния случай организацията трябва да бъде подготвена за всяка проява на злонамерена дейност. На практика това не е осъществимо.
Функцията за реагиране трябва да класифицира и опише всеки инцидент, който се случва в организацията, както и да класифицира и опише възможни инциденти, които са били приети въз основа на анализа на риска.
За да разширите тезауруса относно възможните заплахи и възможни инциденти, свързани с тях, добра практика е да използвате постоянно актуализирани отворени източници в Интернет.
Признаци на инцидент със сигурността на информацията
Предположението, че в дадена организация е възникнал инцидент с информационната сигурност, трябва да се основава на три основни фактора:
- Съобщенията за инцидент на информационната сигурност се получават едновременно от няколко източника (потребители, IDS, регистрационни файлове)
- IDS сигнализира многократно повтарящо се събитие
- Анализът на лог файловете на автоматизираната система дава основа на системните администратори да заключат, че може да възникне инцидент.
Като цяло признаците за инцидент попадат в две основни категории, съобщения, че инцидент се случва в момента, и доклади, че инцидент може да възникне в близко бъдеще. Следват някои признаци за настъпило събитие:
- IDS открива препълване на буфера
- известие за антивирусна програма
- Срив на уеб интерфейса
- Потребителите съобщават за изключително ниски скорости при опит за достъп до интернет
- системният администратор открива наличието на файлове с нечетими имена
- Потребителите съобщават за много дублирани съобщения във входящите си кутии
- хостът записва в журнала за проверка относно промяната на конфигурацията
- приложението записва множество неуспешни опити за оторизация в лог файла
- мрежовият администратор открива рязко увеличение на мрежовия трафик и т.н.
Примери за събития, които могат да служат като източници на информационна сигурност, включват:
- регистрационните файлове на сървъра записват сканиране на портове
- съобщение в медиите за появата на нов тип експлойт
- открито изявление от компютърни престъпници, обявяващи война на вашата организация и др.
Анализ на инциденти със сигурността на информацията
Инцидентът не е очевиден факт, а напротив, нападателите се опитват да направят всичко възможно да не оставят следи от дейността си в системата. Признаците за инцидент включват незначителна промяна в конфигурационния файл на сървъра или, на пръв поглед, стандартна жалба на потребител по имейл. Вземането на решение за настъпване на инцидентно събитие до голяма степен зависи от компетентността на експертите от екипа за реагиране. Необходимо е да се прави разлика между случайна операторска грешка и злонамерено целенасочено въздействие върху информационна система. Фактът, че инцидентът със сигурността на информацията се обработва „на празен ход“, също е инцидент със сигурността на информацията, тъй като отвлича вниманието на експертите от екипа за реагиране от належащите проблеми. Ръководството на организацията трябва да обърне внимание на това обстоятелство и да предостави на експертите от екипа за реагиране известна свобода на действие.
Компилацията от диагностични матрици служи за визуализиране на резултатите от анализа на събитията, случващи се в информационната система. Матрицата се формира от редове с потенциални признаци на инцидент и колони с типове инциденти. Пресичането дава оценка на събитието по приоритетната скала „висок“, „среден“, „нисък“. Диагностичната матрица е предназначена да документира потока от логически заключения на експертите в процеса на вземане на решения и заедно с други документи служи като доказателство за разследването на инцидента.
Документиране на инцидент със сигурността на информацията
Документирането на събитията от инцидент със сигурността на информацията е необходимо за събиране и последващо консолидиране на доказателства от разследването. Всички факти и доказателства за злонамерено въздействие трябва да бъдат документирани. Прави се разграничение между технологични доказателства и оперативни доказателства за въздействие. Технологичните доказателства включват информация, получена от технически средства за събиране и анализ на данни (снифери, IDS); оперативните доказателства включват данни или доказателства, събрани по време на проучване на персонала, доказателства за обаждания до сервизното бюро, обаждания до кол центъра.
Типична практика е поддържането на дневник за разследване на инциденти, който няма стандартна форма и се разработва от екипа за реагиране. Ключовите позиции на такива списания могат да бъдат:
- текущо състояние на разследването
- описание на инцидента
- действия, извършени от екипа за реагиране по време на обработката на инцидента
- списък на участниците в разследването с описание на техните функции и процент на заетост в процедурата по разследване
- списък на доказателствата (със задължително посочване на източниците), събрани по време на обработката на инцидента
размер на шрифта
НАЦИОНАЛЕН СТАНДАРТ НА РУСКАТА ФЕДЕРАЦИЯ - ИНФОРМАЦИОННИ ТЕХНОЛОГИИ - МЕТОДИ И СРЕДСТВА ЗА СИГУРНОСТ - УПРАВЛЕНИЕ... Актуално през 2018 г.
6 Примери за инциденти със сигурността на информацията и техните причини
Инцидентите, свързани със сигурността на информацията, могат да бъдат умишлени или случайни (например резултат от човешка грешка или природни явления) и причинени както от технически, така и от нетехнически средства. Техните последици могат да включват събития като неразрешено разкриване или модифициране на информация, нейното унищожаване или други събития, които я правят недостъпна, както и повреда или кражба на активите на организацията. Инцидентите на информационната сигурност, които не са докладвани, но са били идентифицирани като инциденти, не могат да бъдат разследвани и не могат да бъдат приложени защитни мерки за предотвратяване на повторното възникване на тези инциденти.
По-долу са дадени някои примери за инциденти със сигурността на информацията и техните причини, които са предоставени само с цел разясняване. Важно е да се отбележи, че тези примери не са изчерпателни.
6.1 Отказ от услуга
Отказът от услуга е широка категория инциденти със сигурността на информацията, които имат едно общо нещо.
Такива инциденти със сигурността на информацията водят до невъзможност на системи, услуги или мрежи да продължат да функционират със същата производителност, най-често с пълен отказ на достъп на оторизирани потребители.
Има два основни типа инциденти на информационната сигурност, свързани с отказ на услуга, причинени от технически средства: унищожаване на ресурс и изчерпване на ресурс.
Някои типични примери за такива умишлени инциденти с „отказ на услуга“ за техническа информационна сигурност са:
Пробване на мрежови адреси за излъчване, за да се запълни напълно мрежовата честотна лента с трафик на съобщения за отговор;
Предаване на данни в нежелан формат към система, услуга или мрежа в опит да се наруши или наруши нормалната й работа;
Отваряне на множество сесии едновременно към определена система, услуга или мрежа в опит да се изчерпят нейните ресурси (т.е. забавяне, блокиране или унищожаване).
Някои инциденти с „отказ на услуга“ за техническа информационна сигурност могат да възникнат случайно, например в резултат на конфигурационна грешка, направена от оператор или поради несъвместимост на приложния софтуер, докато други може да са умишлени. Някои инциденти с техническа информационна сигурност „отказ от услуга“ са инициирани умишлено с цел разрушаване на система, услуга и намаляване на производителността на мрежата, докато други са само странични продукти от други злонамерени дейности.
Например, някои от най-разпространените методи за скрито сканиране и идентификация могат да доведат до пълното унищожаване на стари или неправилно конфигурирани системи или услуги, когато бъдат сканирани. Трябва да се отбележи, че много умишлени технически инциденти с отказ на услуга често се инициират анонимно (т.е. източникът на атаката е неизвестен), тъй като атакуващият обикновено няма информация за атакуваната мрежа или система.
Инцидентите на IS „отказ от услуга“, създадени с нетехнически средства и водещи до загуба на информация, услуги и (или) устройства за обработка на информация, могат да бъдат причинени, например, от следните фактори:
Нарушения на системите за физическа сигурност, водещи до кражба, умишлено увреждане или унищожаване на оборудване;
Случайна повреда на оборудването и (или) неговото местоположение от пожар или вода/наводнение;
Екстремни условия на околната среда, като високи температури (поради повреда на климатичната система);
Неправилно функциониране или претоварване на системата;
Неконтролирани промени в системата;
Неправилно функциониране на софтуер или хардуер.
6.2 Събиране на информация
Най-общо казано, инцидентите със сигурността на информацията „събиране на информация“ предполагат действия, свързани с идентифициране на потенциални цели за атака и получаване на разбиране за услугите, изпълнявани на идентифицираните цели за атака. Такива инциденти със сигурността на информацията изискват разузнаване, за да се определи:
Наличието на цел, получаване на разбиране за мрежовата топология около нея и с кого тази цел обикновено е свързана чрез обмен на информация;
Потенциални уязвимости на целта или нейната непосредствена заобикаляща мрежова среда, които могат да бъдат използвани за атака.
Типични примери за атаки, насочени към събиране на информация с технически средства са:
Нулиране на DNS (система за имена на домейни) записи за целевия интернет домейн (прехвърляне на DNS зона);
Изпращане на тестови заявки до произволни мрежови адреси с цел намиране на работещи системи;
Проучване на системата за идентифициране (например чрез контролна сума на файла) на хост операционната система;
Сканиране на налични мрежови портове за системата на протокола за прехвърляне на файлове, за да се идентифицират съответните услуги (например имейл, FTP, мрежа и др.) и софтуерните версии на тези услуги;
Сканиране на една или повече услуги с известни уязвимости в диапазон от мрежови адреси (хоризонтално сканиране).
В някои случаи събирането на техническа информация се разширява до неоторизиран достъп, ако например нападател се опита да получи неоторизиран достъп, докато търси уязвимост. Това обикновено се извършва от автоматизирани хакерски инструменти, които не само търсят уязвимости, но и автоматично се опитват да експлоатират уязвими системи, услуги и (или) мрежи.
Инцидентите за събиране на разузнавателна информация, създадени с нетехнически средства, водят до:
Пряко или непряко разкриване или модифициране на информация;
Кражба на интелектуална собственост, съхранявана в електронен вид;
Нарушаване на записи, например при регистриране на сметки;
Злоупотреба с информационни системи (например в нарушение на закона или организационната политика).
Инцидентите могат да бъдат причинени например от следните фактори:
Нарушения на защитата на физическата сигурност, водещи до неоторизиран достъп до информация и кражба на устройства за съхранение, съдържащи чувствителни данни, като ключове за криптиране;
Лошо и/или неправилно конфигурирани операционни системи поради неконтролирани промени в системата или неправилно функциониращ софтуер или хардуер, което води до достъп на организационен персонал или неоторизиран персонал до информация без разрешение.
6.3 Неоторизиран достъп
Неоторизираният достъп като тип инцидент включва инциденти, които не са включени в първите два вида. Основно този тип инцидент се състои от неразрешени опити за достъп до система или злоупотреба със система, услуга или мрежа. Някои примери за неоторизиран достъп чрез технически средства включват:
Опити за извличане на файлове с пароли;
Атаки за препълване на буфер с цел получаване на привилегирован (например на ниво системен администратор) достъп до мрежата;
Използване на уязвимостите на протокола за прихващане на връзки или погрешно насочване на легитимни мрежови връзки;
Опити за увеличаване на привилегиите за достъп до ресурси или информация отвъд законно притежаваните от потребител или администратор.
Инцидентите с неоторизиран достъп, създадени с нетехнически средства, които водят до пряко или косвено разкриване или модифициране на информация, счетоводни нарушения или злоупотреба с информационни системи, могат да бъдат причинени от следните фактори:
Унищожаване на средства за физическа защита с последващ неоторизиран достъп до информация;
Неуспешна и/или неправилна конфигурация на операционната система поради неконтролирани промени в системата или неизправност на софтуера или хардуера, водещи до резултати, подобни на описаните в последния параграф на 6.2.