Incident and problem management - concepts and principles. Dealing with information security incidents
When handling multiple incidents simultaneously, prioritization is necessary. The rationale for assigning priority is the level of importance of the error to the business and to the user. Based on dialogue with the user and in accordance with the provisions of Service Level Agreements (SLAs), the Service Desk assigns priorities that determine the order in which incidents are processed. When incidents are escalated to a second, third or more support line, the same priority must be maintained, but can sometimes be adjusted in consultation with the Service Desk.
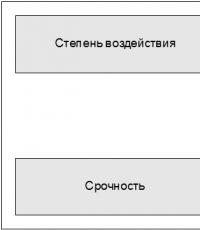
incident impact: the degree of deviation from the normal level of service delivery, expressed in the number of users or business processes affected by the incident;
urgency of the incident: An acceptable incident resolution delay for a user or business process.
Priority is determined based on urgency and impact. For each priority, the number of specialists and the amount of resources that can be directed to resolving the incident are determined. The order in which incidents of the same priority are handled can be determined according to the effort required to resolve the incident. For example, an easily resolved incident may be handled before an incident that requires more effort.
In Incident Management, there are ways to reduce the impact and urgency, such as switching the system to a backup configuration, redirecting the print queue, etc.

Rice. 4.2. Determining impact, urgency and priority
Impact and urgency may also themselves change over time, for example as the number of users affected by an incident increases or at critical points in time.
Impact and urgency can be combined into a matrix as shown in Table 1. 4.1.

Table 4.1. Example of a priority coding system
Escalation
If the incident cannot be resolved by the first line of support within the agreed time, additional expertise or authority must be brought in. This is called escalation, which occurs in accordance with the priorities discussed above and, accordingly, the time to resolve the incident.
There are functional and hierarchical escalation:
Functional escalation (horizontal)– means involving more specialists or providing additional access rights to resolve the incident; at the same time, it is possible that there is an extension beyond the boundaries of one structural IT department.
Hierarchical escalation (vertical)– means a vertical transition (to a higher level) within the organization, since there is insufficient organizational authority (level of authority) or resources to resolve the incident.
The Incident Management Process Manager's job is to proactively reserve functional escalation opportunities within the organization's line units so that incident resolution does not require regular hierarchical escalation. In any case, line units must provide sufficient resources for this process.
First, second and n-line support
The incident routing, or functional escalation, was outlined above. Routing is determined by the required level of knowledge, authority, and urgency. The first line of support (also called Level 1 support) is usually the Service Desk, the second line is IT Infrastructure Management, the third is Software Development and Architecture, and the fourth is vendors. The smaller the organization, the fewer levels of escalation it has. In large organizations, the Incident Management Process Manager may appoint Incident Coordinators in appropriate departments to support his activities. For example, coordinators may play the role of interface between process activities and line organizational units. Each of them coordinates the activities of their own support groups. The escalation procedure is graphically presented in Fig. 4.3.

Rice. 4.3. Incident escalation (source: OGC)
4.2. Target
The goal of the Incident Management Process is to restore the normal Service Level as defined in the Service Level Agreement (SLA) as quickly as possible, with the minimum possible loss to the business activities of the organization and users. In addition, the Incident Management Process must maintain an accurate record of incidents to evaluate and improve the process and provide necessary information to other processes.
4.2.1. Benefits of using the process
For business in general:
Timely resolution of incidents, leading to a reduction in business losses;
Increased user productivity;
Independent, customer-focused incident monitoring;
Availability of objective information about the compliance of the services provided with the agreed upon agreements (SLAs).
For an IT organization:
Improved monitoring, allowing for accurate comparison of IT system performance levels with agreements (SLAs);
Effective management and monitoring of implementation of agreements (SLAs) based on reliable information;
Effective use of personnel;
Prevent incidents and Service Requests from being lost or incorrectly recorded;
Increasing the accuracy of information in the Configuration Management Database (CMDB) by checking it when registering incidents in relation to Configuration Items (CI);
Increased user and customer satisfaction.
Failure to use the Incident Management Process may result in the following negative consequences:
Incidents may be lost or, conversely, unreasonably perceived as extremely serious due to the absence of those responsible for monitoring and escalation, which can lead to a decrease in the overall level of service;
Users may be redirected to the same specialists “in a circle” without successfully resolving the incident;
Professionals may be constantly interrupted by phone calls from users, making it difficult for them to do their jobs effectively;
Situations may arise where several people work on the same incident, wasting time unproductively and making conflicting decisions;
There may be a lack of information about users and services provided to support management decisions;
Due to the above potential issues, the cost to the company and IT organization to support services will be higher than what is actually required.
4.3. Process
In Fig. Figure 4.4 shows the inputs and outputs of a process, as well as the activities that the process involves.

Rice. 4.4. Incident Management Process Statement
4.3.1. Process inputs
Incidents can occur in any part of the infrastructure. They are often reported by users, but they can also be detected by employees of other departments, as well as by automatic management systems configured to record events in applications and technical infrastructure.
4.3.2. Configuration management
The Configuration Management Database (CMDB) plays an important role in Incident Management as it defines the relationship between resources, services, users and Service Levels. For example, Configuration Management shows who is responsible for an infrastructure component, making it possible to distribute incidents more effectively across teams. In addition, this database helps resolve operational issues such as redirecting a print queue or switching a user to another server. When an incident is registered, a link to the corresponding Configuration Item (CI) is added to the registration data, allowing more detailed information about the source of the error to be provided. If necessary, the status of the corresponding component in the CMDB can be updated.
4.3.3. Problem Management
Effective Problem Management requires high-quality recording of incidents, which will greatly facilitate the search for root causes. On the other hand, Problem Management helps the Incident Management Process by providing information about problems, known errors, workarounds and quick fixes.
4.3.4. Change management
Incidents can be resolved by making changes, such as replacing the monitor. Change Management provides the Incident Management Process with information about planned changes and their statuses. In addition, changes can cause incidents if the changes are made incorrectly or contain errors. The Change Management Process receives information about them from the Incident Management Process.
4.3.5. Service Level Management
Service Level Management controls the implementation of agreements (SLAs) with the customer regarding the support provided to him. Personnel involved in Incident Management must be familiar with these agreements in order to use the necessary information when contacting users. In addition, incident records are required for reporting purposes to verify that the agreed Service Level is being met.
4.3.6. Accessibility Management
The Availability Management Process uses incident logs and status monitoring data provided by the Configuration Management Process to determine service availability metrics. Similar to a Configuration Item (CI) in a Configuration Database (CMDB), a service can also be assigned the "out of order" status. This can be used to check the actual service availability and response times of the provider. When carrying out such a check, it is necessary to record the time of actions that occurred during the incident processing process, from the moment of detection to closure.
4.3.7. Capacity management
The Capacity Management process receives information about incidents related to the functioning of the IT systems themselves, for example, incidents that occurred due to insufficient disk space or slow response speed, etc. In turn, information about these incidents can enter the Incident Management Process from the system administrator or from the system itself based on monitoring its condition.
No rice. 4.5. the process steps are shown:

Rice. 4.5. Incident Management Process
Acceptance and Recording– the message is received and an incident record is created.
Classification and Initial Support– the type, status, degree of impact, urgency, priority of the incident, SLA, etc. are assigned. The user may be offered a possible solution, even if it is only temporary.
If the call concerns Service Request, then the corresponding procedure is initiated.
Binding (or Matching)– checks to see if the incident is already a known incident or a known bug, if there is an already open problem for it, and if there is a known solution or workaround for it.
Investigation and diagnosis (Investigation and Diagnosis)– in the absence of a known solution, an investigation of the incident is carried out in order to restore normal operation as quickly as possible.
Resolution and Recovery– if a solution is found, then work can be restored.
Closure– the user is contacted to confirm acceptance of the proposed solution, after which the incident can be closed.
Progress monitoring and tracking– the entire incident processing cycle is monitored, and if the incident cannot be resolved on time, escalation is carried out.
4.4. Activities
4.4.1. Reception and registration
In most cases, incidents are registered by the Service Desk, where incidents are reported. All incidents must be recorded immediately upon notification for the following reasons:
It is difficult to accurately record information about an incident if it is not done immediately;
Monitoring the progress of work to resolve an incident is possible only if the incident is registered;
Logged incidents help in diagnosing new incidents;
Problem Management can use logged incidents when working to find root causes;
It is easier to determine the degree of impact if all messages (calls) are recorded;
Without recording incidents, it is impossible to monitor the implementation of agreements (SLAs);
Immediate incident logging prevents situations where either multiple people are working on the same call or no one is doing anything to resolve the incident.
The location of the incident is determined by where the message about it came from. Incidents can be detected as follows:
Discovered by user: He reports the incident to the Service Desk.
Detected by the system: When an event is detected in the application or technical infrastructure, for example when a critical threshold is exceeded, the event is recorded as an incident in the incident reporting system and, if necessary, escalated to the support team.
Detected by Service Desk: The employee records the incident.
Discovered by someone in another IT department: This specialist logs the incident into the incident reporting system or reports it to the Service Desk.
Double recording of the same incident should be avoided. Therefore, when registering an incident, you should check whether there are similar open incidents:
If there are (and they relate to the same incident), information about the incident is updated or the incident is registered separately and a connection is established (link) to the main incident; if necessary, the impact level and priority are changed, and information about the new user is added.
If not (different from open incident), a new incident is registered.
In both cases, the continuation of the process is the same, although in the first case the subsequent steps are much simpler.
When an incident is registered, the following actions are performed:
Assigning an incident number: In most cases, the system automatically assigns a new (unique) incident number. Often this number is provided to the user so that he can refer to it in future contacts.
Recording Basic Diagnostic Information: time, signs (symptoms), user, employee who accepted the issue for processing, location of the incident and information about the affected service and/or technical means.
Recording additional information about the incident: Information is added, for example, from a script or polling procedure or from a Configuration Database (CMDB) (usually based on Configuration Item relationships defined in the CMDB).
Alarm Announcement: If a high impact incident occurs, such as a critical server failure, an alert is issued to other users and management.
4.4.2. Classification
Incident classification aims to define its category to facilitate monitoring and reporting. It is desirable that classification options be as broad as possible, but this requires a higher level of staff responsibility. Sometimes they try to combine several aspects of the classification into one list, such as type, support group and source. This often causes confusion. It is better to use several short lists. This section addresses issues related to classification.
Central processing system– access subsystem, central server, application.
Net– routers, segments, hub, IP addresses.
Work station– monitor, network card, disk drive, keyboard.
Usage and functionality– service (service), system capabilities, availability, backup (back-up), documentation.
Organization and procedures– order, request, support, notification (communications).
Service Request– a user request to the Service Desk for support, information, documentation or consultation. This can be separated into a separate procedure or handled in the same way as a real incident.
A priority
A priority is then assigned to ensure that the support team gives the incident the attention it needs. Priority is a number determined by urgency (how quickly it needs to be fixed) and impact (how much damage will be done if not fixed quickly).
Priority = Urgency x Impact.
Services (services)
To identify the services affected by the incident, a list of existing Service Level Agreements (SLAs) can be used. This list will also allow you to set the escalation time for each of the services defined in the SLA.
Support Group
If the Service Desk cannot resolve the incident immediately, a support team is assigned to resolve the incident. The basis for incident distribution (routing) is often category information. When defining categories, consideration may need to be given to the structure of support groups. Proper distribution of incidents is essential to the effectiveness of the Incident Management Process. Therefore, one of the key performance indicators (KPIs) of the Incident Management Process may be the number of incorrectly allocated tickets.
Deadline for decision
Taking into account the priority and SLA agreement, the user is informed of the maximum estimated time to resolve the incident. These deadlines are also recorded in the system.
Incident ID number
The subscriber is informed about the incident number for its accurate identification during subsequent calls.
Status
An incident's status indicates its position in the incident handling process. Examples of statuses could be:
Scheduled;
Appointed;
Active;
Postponed;
Allowed;
4.4.3. Binding (mapping)
After classification, a check is made to see if a similar incident has occurred before and whether there is a ready-made solution or workaround. If an incident has the same characteristics as an open issue or known error, it can be linked to it.
4.4.4. Investigation and diagnosis
The Service Desk or support team escalates incidents that do not have a solution or are beyond the capabilities of the person working with them to the next level support team with more experience and knowledge. This team investigates and resolves the incident or escalates it to the next level of support team.
During the incident resolution process, various specialists can update the incident record by changing the current status, information about actions taken, revising the classification and updating the time and code of the employee.
4.4.5. Solution and recovery
After successfully completing the analysis and resolving the incident, the employee records the solution in the system. In some cases, it is necessary to submit a Request for Change (RFC) to the Change Management Process. In the worst case, if no solution is found, the incident remains open.
4.4.6. Closing
Once a solution is implemented to the user's satisfaction, the support team escalates the incident back to the Service Desk. This service contacts the employee who reported the incident to obtain confirmation that the issue has been successfully resolved. If he confirms this, then the incident can be closed; otherwise, the process resumes at the appropriate level. When an incident is closed, it is necessary to update the final category, priority, service(s) affected by the incident, and the Configuration Item (CI) that caused the failure.
4.4.7. Solution progress monitoring and tracking
In most cases, the Service Desk, as the “owner” of all incidents, is responsible for monitoring the progress of the resolution. This service should also inform the user about the status of the incident. User feedback may be appropriate after a change in status, such as escalating an incident to the next support line, changing the estimated resolution time, escalation, etc. During monitoring, functional escalation to other support groups or hierarchical escalation to make executive decisions is possible.
4.5. Process control
The basis for process control are reports for various target groups. The Incident Management Process Manager is responsible for these reports, as well as the mailing list and reporting schedule. Reports may include specialized information for the following functional units:
The Incident Management Process Manager needs the report to:
Identification of missing links in the process;
Identification of violations of Service Level Agreements (SLAs);
Tracking the progress of the process;
Determination of development trends.
Management of Linear IT Departments– report for support group management; it can also be useful in IT Department Management. The report must contain the following information:
Progress in resolving incidents;
Time to resolve incidents in various support groups.
Service Level Management– the report must, first of all, contain information about the quality of the services provided. The Service Level Management Process Manager must receive all information necessary to prepare Service Level Reports to customers. Reports to customers should provide information on whether Service Level agreements are being met within the Incident Management Process.
Managers of other IT Service Management processes– reports for managers of other processes should, first of all, be informative, that is, contain all the information they need. For example, an Incident Management Process based on incident records could provide the following information:
Number of incidents detected and recorded;
Number of resolved incidents, divided by resolution time;
Status and number of unresolved incidents;
Incidents by period of occurrence, customer groups, support groups and resolution time in accordance with the agreement (SLA);
4.5.1. Critical Success Factors
Successful Incident Management requires the following:
An up-to-date Configuration Database (CMDB) to help assess the impact and urgency of incidents. This information can also be obtained from the user, but in this case it may be less complete and quite subjective, which will lead to an increase in the time it takes to resolve incidents.
To evaluate process performance, it is necessary to clearly define control parameters and measurable scores, often called performance indicators. These metrics are reported regularly, such as once a week, to provide a picture of changes from which trends can be identified. Examples of such parameters are:
Total number of incidents;
Average time to resolve incidents;
Average time to resolve incidents by priority;
Average number of incidents resolved within SLAs;
Percentage of incidents resolved by the first line of support (without referral to other groups);
Average support cost per incident;
Number of resolved incidents per workplace or per Service Desk employee;
Incidents resolved without visiting the user (remotely);
Number (or percentage) of incidents with initially incorrect classification;
Number (or percentage) of incidents incorrectly assigned to support groups.
4.5.3. Functions and roles
The implementation of processes takes place on a horizontal plane through the hierarchical structure of the organization. This is only possible with a clear definition of the responsibilities and authorities associated with the implementation of processes. To increase flexibility, a role-based approach (i.e. defining roles) can be used. In small organizations or in order to reduce overall costs, it is possible to combine roles, for example, combining the roles of Change Management and Configuration Management Process Manager.
Incident Management Process Manager
In many organizations, the role of Incident Management Manager is played by the Service Desk Manager. The responsibilities of the Incident Management Process Manager include the following:
Monitoring the efficiency and rationality of the process;
Monitoring the work of support groups;
Development and maintenance of the Incident Management system.
Support Group Staff
The first line of support is responsible for recording, classifying, matching (linking), assigning to support groups, resolving and closing incidents.
The remaining support teams are primarily involved in investigating, diagnosing and resolving incidents within established priorities.
4.6. Costs and problems
4.6.1. Expenses
Costs associated with Incident Management include initial implementation costs (eg costs of process development, training and coaching of personnel), selection and procurement of tools to support the process. Selecting tools can take a significant amount of time. In addition, there are operating costs associated with paying staff and using tools. These costs largely depend on the structure of Incident Management, the range of activities included in the process, areas of responsibility and the number of departments.
4.6.2. Problems
When implementing Incident Management, the following problems may arise:
Users and IT professionals work around Incident Management procedures– if users resolve errors themselves or directly contact specialists without following established procedures, the IT organization will not receive information about the actual Service Level provided, the number of errors, and much more. Reports to management will also not adequately reflect the situation.
Overload with incidents and procrastination “for later”– if there is an unexpected increase in the number of incidents, there may not be enough time for correct registration, since before the end of entering information about the incident from one user, it becomes necessary to serve the next. In this case, the entry of incident descriptions may not be accurate enough and the procedures for distributing incidents to support groups will not be carried out properly. As a result, decisions are of poor quality and the workload increases even more. In cases where the number of open incidents begins to rapidly increase, a procedure for emergency allocation of additional resources within the organization can prevent staff overload.
Escalation– As is known, escalation of incidents is possible within the Incident Management Process. Too many escalations can have a negative impact on the work of specialists, who are therefore taken away from their planned work.
Lack of a Service Catalog and Service Level Agreements (SLAs)– If the services and products supported are not well defined, then it may be difficult for those involved in Incident Management to reasonably refuse assistance to users.
Lack of commitment process approach on the part of management and staff– resolving incidents using a process approach usually requires a change in culture and a higher level of responsibility for their work on the part of staff. This can cause significant resistance within the organization. Effective Incident Management requires employees to understand and truly commit to a process approach rather than simply participate.
Notes:
The “chain” refers to the chain of creation of surplus value. – Approx. ed.
In the ITIL literature, the concept of “function” is associated with a vertical (line) division of an organization that performs the corresponding functional responsibilities and is actually synonymous with it. – Approx. ed.
Service Request.
Request for Change (RFC).
Configuration Item (CI).
Key Performance Indicators - KPIs.
Performance Indicators.
Effectiveness and Efficiency.
Those. software. – Approx. ed.
Ensuring business information security Andrianov V.V.
4.1.4. Examples of incidents
4.1.4. Examples of incidents
General information
This section describes published details of some of the high-profile incidents. At the same time, generalization of incidents provides a whole bunch of circumstances characterizing the variety of information security threats from personnel, both in terms of motives and conditions, and in terms of the means used. Among the most frequently occurring incidents, we note the following:
Leakage of official information;
Theft of clients and business of the organization;
Sabotage of infrastructure;
Internal fraud;
Falsification of reports;
Trading in markets based on insider and proprietary information;
Abuse of authority.
annotation
In retaliation for a too small bonus, 63-year-old Roger Duronio (former system administrator at UBS Paine Webber) installed a “logical bomb” on the company’s servers, which destroyed all data and paralyzed the company’s work for a long time.
Description of the incident
Duronio was dissatisfied with his salary of $125,000 a year, which may have been the reason for the introduction of the logic bomb. However, the last straw for the system administrator was the bonus he received in the amount of $32,000 instead of the expected $50,000. When he discovered that his bonus was much less than he expected, Duronio demanded that his boss renegotiate his employment contract at $175,000 a year or he would leave the company. He was denied a salary increase, and he was also asked to leave the bank building. In retaliation for such treatment, Duronio decided to use his “invention,” introduced in advance, anticipating such a turn of events.
Duronio implemented the “logic bomb” from his home computer several months before he received what he considered to be a too small bonus. The logic bomb was installed on approximately 1,500 computers in a network of branches across the country and set to a specific time - 9.30, just in time for the start of the banking day.
Duronio resigned from UBS Paine Webber on February 22, 2002, and on March 4, 2002, a logic bomb sequentially deleted all files on the main central database server and 2,000 servers in the bank's 400 branches, while disabling the backup system.
During the trial, Duronio's lawyer pointed out that the culprit of the incident could not have been the accused alone: given the insecurity of the UBS Paine Webber IT systems, any other employee could have gotten there under Duronio's login. Problems with IT security at the bank became known back in January 2002: during an audit, it was found that 40 people from the IT service could log into the system and obtain administrator rights using the same password, and understand who exactly did it or any other action was not possible. The lawyer also accused UBS Paine Webber and the company @Stake, hired by the bank to investigate the incident, of destroying evidence of the attack. However, the irrefutable evidence of Duronio's guilt was the pieces of malicious code found on his home computers, and a printed copy of the code in his closet.
Insider Opportunities
As one of the company's system administrators, Duronio was given responsibility for and access to the entire UBS PaineWebber computer network. He also had access to the network from his home computer via a secure internet connection.
Causes
As stated earlier, his motives were money and revenge. Duronio received an annual salary of $125,000 and a bonus of $32,000, while he was expecting $50,000, and thus avenged his disappointment.
In addition, Duronio decided to make money on the attack: anticipating a fall in the bank's shares due to an IT disaster, he made a futures order to sell in order to receive the difference when the rate dropped. The defendant spent $20,000 on this. However, the bank's securities did not fall, and Duronio's investments did not pay off.
Consequences
The “logic bomb” planted by Duronio stopped the work of 2,000 servers in 400 company offices. According to UBS Paine Webber IT manager Elvira Maria Rodriguez, it was a disaster “a 10-plus on a scale of 10.” Chaos reigned in the company, which took 200 engineers from IBM to eliminate for almost a day. In total, about 400 specialists worked to correct the situation, including the IT service of the bank itself. The damage from the incident is estimated at $3.1 million. Eight thousand brokers across the country were forced to stop working. Some of them were able to return to normal operations after a few days, some after a few weeks, depending on how badly their databases were affected and whether the bank branch had backups. In general, banking operations were resumed within a few days, but some servers were never fully restored, largely due to the fact that 20% of the servers did not have backup facilities. Only a year later, the bank’s entire server park was completely restored again.
During Duronio's trial in court, he was accused of the following charges:
Securities Fraud - This charge carries a maximum penalty of 10 years in federal prison and a $1 million fine;
Computer Fraud - This charge carries a maximum penalty of 10 years in prison and a fine of $250,000.
As a result of the trial in late December 2006, Duronio was sentenced to 97 months without parole.
"Vimpelcom" and "Sherlock"
annotation
For the purpose of profit, former employees of the VimpelCom company (Beeline trademark) offered details of telephone conversations of mobile operators through the website.
Description of the incident
Employees of the VimpelCom company (former and current) organized the website www.sherlok.ru on the Internet, which the VimpelCom company learned about in June 2004. The organizers of this site offered a service - searching for people by last name, phone number and other data. In July, the site's organizers offered a new service - detailing telephone conversations of mobile operators. Call detailing is a printout of the numbers of all incoming and outgoing calls, indicating the duration of calls and their cost, used by operators, for example, for billing subscribers. Based on these data, we can draw a conclusion about the subscriber’s current activities, his area of interest and circle of acquaintances. The press release from Directorate “K” of the Ministry of Internal Affairs (hereinafter referred to as the Ministry of Internal Affairs) clarifies that such information cost the customer $500.
Employees of the VimpelCom company, having discovered this site, independently collected evidence of the site’s criminal activities and transferred the case to the Ministry of Internal Affairs. Employees of the Ministry of Internal Affairs opened a criminal case and, together with the VimpelCom company, established the identities of the organizers of this criminal business. And on October 18, 2004, the main suspect 1 was detained red-handed.
In addition, on November 26, 2004, the remaining six suspects were detained, including three employees of the subscriber service of the VimpelCom company itself. During the investigation, it turned out that the site was created by a former student of Moscow State University who did not work for this company.
The paperwork on this incident became possible thanks to the ruling of the Constitutional Court in 2003, which recognized that call details contained the secrecy of telephone conversations, protected by law.
Insider Opportunities
Two of the VimpelCom employees identified among the participants in the incident worked as tellers in the company, and the third was a former employee and was working at the Mitinsky market at the time of the crime.
Working as tellers in the company itself indicates that these employees had direct access to the information offered for sale on the website www.sherlok.ru. In addition, since a former employee of the company already worked at the Mitinsky market, it can be assumed that over time, this market could also become one of the distribution channels for this information or any other information from the VimpelCom company databases.
Consequences
The main consequences for VimpelCom from this incident could be a blow to the reputation of the company itself and the loss of customers. However, this incident was made public directly thanks to the active actions of the company itself.
In addition, making this information public could have a negative impact on VimpelCom’s clients, since the detail of the conversations allows us to draw a conclusion about the subscriber’s current activities, his area of interest and circle of acquaintances.
In March 2005, the Ostankino District Court of Moscow sentenced the suspects, including three employees of the VimpelCom company, to various fines. Thus, the organizer of the group was fined 93,000 rubles. However, the operation of the website www.sherlok.ru was stopped indefinitely only from January 1, 2008.
The largest personal data leak in Japanese history
annotation
In the summer of 2006, the largest leak of personal data in the history of Japan occurred: an employee of the printing and electronics giant Dai Nippon Printing stole a disk with private information of almost nine million citizens.
Description of the incident
The Japanese company Dai Nippon Printing, specializing in the production of printed products, allowed the largest leak in the history of its country. Hirofumi Yokoyama, a former employee of one of the company's contractors, copied personal data of the company's clients onto a mobile hard drive and stole it. A total of 8.64 million people were at risk because the stolen information included names, addresses, phone numbers and credit card numbers. The stolen information included customer information from 43 different companies, such as 1,504,857 American Home Assurance customers, 581,293 Aeon Co customers and 439,222 NTT Finance customers.
After the theft of this information, Hirofumi opened trade in private information in portions of 100,000 records. Thanks to the stable income, the insider even left his permanent job. By the time of his arrest, Hirofumi had managed to sell the data of 150,000 clients of the largest credit firms to a group of fraudsters specializing in online purchases. In addition, some of the data has already been used for credit card fraud.
More than half of the organizations whose customer data was stolen were not even warned about the information leak.
Consequences
As a result of this incident, the losses of citizens who suffered due to credit card fraud, which became possible only as a result of this leak, amounted to several million dollars. In total, customers of 43 different companies were affected, including Toyota Motor Corp., American Home Assurance, Aeon Co and NTT Finance. However, more than half of the organizations were not even warned about the leak.
In 2003, Japan passed the Personal Information Protection Act 2003 (PIPA), but prosecutors were unable to apply it in the actual trial of the case in early 2007. The prosecution was unable to charge the insider with violating PIPA. He is only accused of stealing a hard drive worth $200.
Not appreciated. Zaporozhye hacker against a Ukrainian bank
annotation
A former system administrator of one of the large banks in Ukraine transferred about 5 million hryvnia through the bank where he previously worked from the account of the regional customs to the account of a non-existent bankrupt Dnepropetrovsk company.
Description of the incident
His career as a system administrator began after he graduated from technical school and was hired by one of the large banks in Ukraine in the software and hardware department. After some time, management noticed his talent and decided that he would be more useful to the bank as a department head. However, the arrival of new management at the bank also entailed personnel changes. He was asked to temporarily vacate his position. Soon, the new management began to form their team, but his talent turned out to be unclaimed, and he was offered the non-existent position of deputy chief, but in a different department. As a result of such personnel changes, he began to do something completely different from what he knew best.
The system administrator could not put up with this attitude of management towards himself and resigned of his own free will. However, he was haunted by his own pride and resentment towards management, in addition, he wanted to prove that he was the best in his business and return to the department where his career began.
After resigning, the former system administrator decided to return the former management’s interest in his person by using the imperfections of the “Bank-Client” system used in almost all banks in Ukraine 2 . The system administrator's plan was that he decided to develop his own security program and offer it to the bank, returning to his previous place of work. The implementation of the plan consisted of penetrating the Bank-Client system and making minimal changes to it. The entire calculation was made on the fact that the bank would have discovered a system hack.
To penetrate the specified system, the former system administrator used passwords and codes that he learned while working with this system. All other information necessary for hacking was obtained from various hacker sites, where various cases of computer network hacking, hacking techniques, and all the software necessary for hacking were described in detail.
Having created a loophole in the system, the former system administrator periodically penetrated the bank's computer system and left various signs in it, trying to draw attention to the facts of hacking. Bank specialists were supposed to detect the hack and sound the alarm, but, to his surprise, no one even noticed the penetration into the system.
Then the system administrator decided to change his plan, making adjustments to it that could not go unnoticed. He decided to forge a payment order and use it to transfer a large amount through the bank’s computer system. Using a laptop and a mobile phone with a built-in modem, the system administrator penetrated the bank's computer system about 30 times: looked through documents, client accounts, cash flows - in search of suitable clients. He chose regional customs and a bankrupt Dnepropetrovsk company as such clients.
Having once again gained access to the bank’s system, he created a payment order in which he withdrew 5 million hryvnia from the personal account of the regional customs and transferred through the bank to the account of the bankrupt company. In addition, he purposefully made several mistakes in the “payment”, which in turn should have further helped attract the attention of bank specialists. However, even such facts were not noticed by the bank specialists servicing the Bank-Client system, and they calmly transferred 5 million hryvnia to the account of a defunct company.
In reality, the system administrator expected that the funds would not be transferred, that the fact of hacking would be discovered before the funds were transferred, but in practice everything turned out differently and he became a criminal and his fake transfer escalated into theft.
The fact of hacking and theft of funds on an especially large scale was discovered only a few hours after the transfer, when bank employees called customs to confirm the transfer. But they reported that no one had transferred such an amount. The money was urgently returned to the bank, and a criminal case was opened in the prosecutor's office of the Zaporozhye region.
Consequences
The bank did not suffer any losses, since the money was returned to the owner, and the computer system received minimal damage, as a result of which the bank management refused any claims against the former system administrator.
In 2004, by decree of the President of Ukraine, criminal liability for computer crimes was strengthened: fines from 600 to 1000 tax-free minimums, imprisonment from 3 to 6 years. However, the former system administrator committed a crime before the presidential decree came into force.
At the beginning of 2005, a trial of the system administrator took place. He was accused of committing a crime under Part 2 of Article 361 of the Criminal Code of Ukraine - illegal interference with the operation of computer systems causing harm and under Part 5 of Article 185 - theft committed on an especially large scale. But since the bank’s management refused to make any claims against him, the charge of theft was removed from him, and part 2 of article 361 was changed to part 1 - illegal interference in the operation of computer systems.
Uncontrolled trading at Societe Generale bank
annotation
On January 24, 2008, Societe Generale announced a loss of 4.9 billion euros due to the machinations of its trader Jerome Kerviel. As an internal investigation showed, for several years the trader opened above-limit positions in futures for European stock indices. The total amount of open positions amounted to 50 billion euros.
Description of the incident
From July 2006 to September 2007, the computer internal control system issued a warning about possible violations 75 times (that is how many times Jerome Kerviel carried out unauthorized transactions or his positions exceeded the permissible limit). Employees of the bank's risk monitoring department did not carry out detailed checks on these warnings.
Kerviel first began experimenting with unauthorized trading in 2005. Then he took a short position on Allianz shares, expecting the market to fall. Soon the market really fell (after the terrorist attacks in London), which is how the first 500,000 euros were earned. Kerviel later told investigators about his feelings about his first success: “I already knew how to close my position, and I was proud of the result, but at the same time I was surprised. Success made me continue, it was like a snowball... In July 2007, I proposed to take a short position in anticipation of a market decline, but did not receive support from my manager. My forecast came true, and we made a profit, this time it was completely legal. Subsequently, I continued to carry out such operations on the market, either with the consent of my superiors or in the absence of his explicit objection... By December 31, 2007, my profit reached 1.4 billion euros. At that moment, I did not know how to declare this to my bank, since it was a very large amount that was not declared anywhere. I was happy and proud, but I did not know how to explain to my management the receipt of this money and not incur suspicion of conducting unauthorized transactions. Therefore, I decided to hide my profit and conduct the opposite fictitious operation...”
In fact, in early January of that year, Jerome Kerviel re-entered the game with futures contracts on the three Euro Stoxx 50 indices, DAX and FTSE, which helped him beat the market in late 2007 (though he preferred to go short at the time). According to calculations, on the eve of January 11, his portfolio contained 707.9 thousand futures (each worth 42.4 thousand euros) on Euro Stoxx 50, 93.3 thousand futures (192.8 thousand euros per 1 piece) on DAX and 24.2 thousand futures (82.7 thousand euros per 1 contract) for the FTSE index. In total, Kerviel's speculative position was equal to 50 billion euros, that is, it was more than the value of the bank in which he worked.
Knowing the timing of the checks, he opened a fictitious hedging position at the right moment, which he later closed. As a result, reviewers never saw a single position that could be considered risky. They could not be alarmed by the large amounts of transactions, which are quite common in the index futures market. He was let down by fictitious transactions carried out from the accounts of bank clients. The use of accounts of various bank clients did not lead to problems visible to controllers. However, over time, Kerviel began using the same clients' accounts, which led to "abnormal" activity observed on these accounts and, in turn, attracted the attention of controllers. This was the end of the scam. It turned out that Kerviel's partner in the multibillion-dollar deal was a large German bank, which allegedly confirmed the astronomical transaction by email. However, the electronic confirmation raised suspicions among the inspectors, and a commission was created at Societe Generale to verify them. On January 19, in response to a request, the German bank did not recognize this transaction, after which the trader agreed to confess.
When it was possible to find out the astronomical size of the speculative position, the CEO and chairman of the board of directors of Societe Generale, Daniel Bouton, announced his intention to close the risky position opened by Kerviel. This took two days and resulted in losses of 4.9 billion euros.
Insider Opportunities
Jerome Kerviel worked for five years in the so-called back office of the bank, that is, in a department that does not directly conclude any transactions. It deals only with accounting, execution and registration of transactions and monitors traders. This activity allowed us to understand the features of the control systems in the bank.
In 2005, Kerviel was promoted. He became a real trader. The young man’s immediate responsibilities included basic operations to minimize risks. Working in the futures market for European stock indices, Jerome Kerviel had to monitor how the bank's investment portfolio was changing. And his main task, as one Societe Generale representative explained, was to reduce risks by playing in the opposite direction: “Roughly speaking, seeing that the bank was betting on red, he had to bet on black.” Like all junior traders, Kerviel had a limit that he could not exceed, which was monitored by his former colleagues in the back office. Societe Generale had several layers of protection, for example traders could only open positions from their work computer. All data on opening positions was automatically transmitted in real time to the back office. But, as they say, the best poacher is a former forester. And the bank made an unforgivable mistake by putting the former forester in the position of a hunter. Jerome Kerviel, who had almost five years of experience in monitoring traders, did not find it difficult to bypass this system. He knew other people's passwords, knew when checks were going on at the bank, and was well versed in information technology.
Causes
If Kerviel was involved in fraud, it was not for the purpose of personal enrichment. His lawyers say this, and representatives of the bank also admit this, calling Kerviel’s actions irrational. Kerviel himself says that he acted solely in the interests of the bank and only wanted to prove his talents as a trader.
Consequences
At the end of 2007, its activities brought the bank about 2 billion euros in profit. In any case, this is what Kerviel himself says, claiming that the bank’s management probably knew what he was doing, but preferred to turn a blind eye as long as he was profitable.
Closing the risky position opened by Kerviel led to losses of 4.9 billion euros.
In May 2008, Daniel Bouton left the post of CEO of Societe Generale, and was replaced in this position by Frédéric Oudea. A year later, he was forced to resign from his post as chairman of the bank's board of directors. The reason for his departure was sharp criticism from the press: Bouton was accused of the fact that the top managers of the bank under his control encouraged risky financial transactions carried out by bank employees.
Despite the support of the board of directors, pressure on Mr. Bouton increased. The bank's shareholders and many French politicians demanded his resignation. French President Nicolas Sarkozy also called on Daniel Bouton to resign after it became known that in the year and a half before the scandal, Societe Generale's computer internal control system issued a warning 75 times, i.e. every time Jerome Kerviel carried out unauthorized transactions. possible violations.
Immediately after the losses were discovered, Societe Generale created a special commission to investigate the trader’s actions, which included independent members of the bank’s board of directors and auditors PricewaterhouseCoopers. The commission concluded that the bank's internal control system was not effective enough. This resulted in the bank being unable to prevent such a large-scale fraud. The report states that “bank staff did not conduct systematic checks” of the trader’s activities, and the bank itself did not have “a control system that could prevent fraud.”
The report on the results of the trader's audit states that following the results of the investigation, a decision was made to “significantly strengthen the procedure for internal supervision of the activities of Societe Generale employees.” This will be done through a more strict organization of the work of various divisions of the bank and coordination of their interaction. Measures will also be taken to track and personalize the trading operations of bank employees by “strengthening the IT security system and developing high-tech solutions for personal identification (biometrics).”
From the book Ensuring Business Information Security author Andrianov V.V.4.2.2. Typology of incidents Generalization of world practice allows us to identify the following types of information security incidents involving organization personnel: - disclosure of official information; - falsification of reports; - theft of financial and material assets; - sabotage
From the book Pension: calculation and registration procedure author Minaeva Lyubov Nikolaevna4.3.8. Incident Investigation An incident in which an employee of an organization is involved is an emergency for most organizations. Therefore, the way an investigation is organized strongly depends on the existing corporate culture of the organization. But you can confidently
From the book Day Trading in the Forex Market. Profit Strategies by Lyn Ketty2.5. Examples Let's consider some options for assigning labor pensions in case of transfer of documents to the territorial bodies of the Pension Fund by mail: Example 1 An application for the assignment of an old-age labor pension was sent to the territorial body of the fund
From the book The Practice of Human Resource Management author Armstrong Michael3.5. Examples Example 1 Work experience consists of periods of work from March 15, 1966 to May 23, 1967; from 09/15/1970 to 05/21/1987; from 01.01.1989 to 31.12.1989; from 09/04/1991 to 07/14/1996; from 07/15/1996 to 07/12/1998 and military service from 05/27/1967 to 06/09/1969. Let’s calculate the length of service to assess pension rights
From the author's book4.4. Examples Example 1 Engineer Sergeev A.P., born in 1950, applied for an old-age pension in March 2010. In 2010, he turned 60 years old. The total length of service for assessing pension rights as of January 1, 2002 is 32 years, 5 months, 18 days, including 30 years before 1991.
From the author's book6.3. Examples Example 1 Sales manager V.N. Sokolov worked under an employment contract from January 1, 2010. January 1, 2013, he dies at the age of 25. At the same time, he still has able-bodied parents, an able-bodied wife and a daughter aged 3 years. In this case, the right to receive labor
From the author's book7.4. Examples Example 1 Manager Vasiliev R. S., 60 years old. The total length of service according to the work book for assessing pension rights as of January 1, 2002 is 40 years. Average monthly earnings for 2000–2001, according to personalized accounting data, are 4,000 rubles. We will calculate and compare pension amounts according to
From the author's book8.3. Examples Example 1 A pensioner receives a disability pension of group I. From May 20 to June 5, 2009, he underwent another re-examination at the BMSE and was recognized as disabled group III on June 3, 2009. The disability group in this case decreased. The basic part of the pension is subject to
From the author's book10.4. Examples Example 1 The death of a pensioner occurred on January 28, 2009. The pensioner’s widow applied for a pension in February 2009. The widow’s cohabitation with the pensioner on the day of death was not established. In this pension case, the territorial body of the fund accepted
From the author's book14.7. Examples Example 1 Koshkina V.N., who was dependent on her deceased husband, reached the age of 55 3 months after his death. I applied for a pension after 1 year from the date of death of my spouse. According to pension legislation, the pension will be assigned from the date
From the author's book17.5. Examples Example 1 An individual entrepreneur employs four people under an employment contract: Moroz K.V. (b. 1978), Svetlova T. G. (b. 1968), Leonova T. N. (b. 1956) and Komarov S. N. (b. 1952). Suppose the monthly salary of each of them is 7,000 rubles.
From the author's bookExamples Let's look at some examples of how this strategy works: 1. 15-minute chart of EUR/USD in Fig. 8.8. According to the rules of this strategy, we see that EUR/USD fell and was trading below the 20-day moving average. Prices continued to decline, moving towards 1.2800, which is
From the author's bookExamples Let's study a few examples.1. In Fig. Figure 8.22 shows a 15-minute chart of USD/CAD. The total range of the channel is approximately 30 points. In accordance with our strategy, we place entry orders 10 points above and below the channel, i.e. at 1.2395 and 1.2349. Buy order executed
From the author's bookExamples Let's look at some examples of this strategy in action.1. In Fig. Figure 8.25 shows the daily chart of EUR/USD. On October 27, 2004, the EUR/USD moving averages formed a consistent correct order. We open a position five candles after the start of formation at 1.2820.
As the role of IT in a company increases, so does the need to ensure a good level of service and ensure maximum availability of IT services. The business user should be able to get solutions to their problems if they arise as quickly as possible and work at any time. Implementation of processes incident management and problems are aimed precisely at this. In this article we describe how the work of an IT service can be organized within the framework of incident management and problems. This description is based on ITIL suggestions and the experiences of our clients.
Language of incidents and problems
ITIL Service Support is a globally recognized model. It is based on best practice and is used to guide IT organizations in developing approaches to service management. This model is promising. It also defines additional elements necessary for the successful functioning of an IT organization as a service business. It provides a technical vocabulary for help desk discussions, defines concepts, and highlights the differences between different activities. For example, the activities required to respond to service interruptions and restore them are different from the activities required to find and eliminate the causes of service interruptions.
Incidents
Incident- any event that is not part of the standard operations of the service and causes, or may cause, an interruption of service or a decrease in the quality of the service.
Examples of incidents are:
- User cannot receive email
- Network monitoring tool indicates that the communication channel will soon become full
- The user feels the application slows down
Problems
Problem— there is an unknown cause for one or more incidents. One problem can give rise to several incidents.
Errors
Known bug— there is an incident or problem for which the cause has been identified and a solution has been developed to bypass or eliminate it. Errors may be identified through analysis of user complaints or analysis of systems.
Examples of errors include:
- Incorrect computer network configuration
- The monitoring tool incorrectly determines the channel status when the router is busy
Correlation of concepts incident management and problems are shown in Figure 1. Incidents, problems and known errors are linked in a kind of life cycle: incidents are often indicators of problems ⇒ identifying the cause of the problem identifies the error ⇒ errors are then systematically corrected.
- there is an activity to restore normal service with minimal delays and impact on business operations, which is a reactive, short-term focused restoration service.
It includes:
- Incident detection and recording
- Classification and initial support
- Research and diagnosis
- Solution and recovery
- Closing
- Ownership, monitoring, tracking and communication
Problem management
Problem management — there are activities to minimize the impact on business of problems that are caused by errors in the IT infrastructure, to prevent the recurrence of incidents associated with such errors. Problem management identifies the causes of problems and identifies workarounds or solutions.
Problem management includes:
- Problem control
- Error Control
- Preventing problems
- Analysis of the main problems
Problem control
Purpose of problem control— find the cause of the problem by following these steps:
- Identifying and logging problems
- Classification of problems and prioritization of their solutions
- Research and diagnosis of causes
Error Control
Error control ensures that problems are corrected by:
- Identifying and logging known errors
- Evaluating remedies and prioritizing them
- Registration for temporary workaround in support tools
- Closing known issues by implementing fixes
- Monitor known errors to determine the need for reprioritization
Problem Analysis
Purpose of Problem Analysis is to improve processes incident management and problem management. What is achieved by studying the quality of the results of activities to eliminate major problems and incidents.
Organizational roles and distribution of responsibilities
The most common support system structure is a tiered model in which increasing levels of technical capabilities are applied to resolve an incident or problem. The actual roles and responsibilities used in a tiered support system implementation may vary depending on the personnel, history, and policies of the particular organization. However, the following description of a tiered support system is typical for many organizations.
First level of support
The organization (division) representing the first level of support usually refers to operational services. As a rule, it is called dispatch service, Call Center, Service Desk.
Roles. Process owner
The first level of support ensures that a well-defined, consistently executed, appropriately measured, efficient process is established and maintained. incident management. Receive and manage all customer service issues. The first level of support is the single point of contact for escalating service issues and acts as the end user's advocate to ensure that service issues are resolved in a timely manner.
First line of support
The first level support organization makes the first attempt to resolve the service issue reported by the end user.
Responsibilities
- It is guaranteed that the incident card contains an accurate and sufficiently detailed description of the problem
- Correct choice of incident importance/priority is guaranteed
- The nature of the problem, user contacts, business impact and expected resolution time are determined
Ownership of every incident. As the end user's advocate, the first level of support ensures that every incident is successfully resolved. This ensures timely resolution of issues through:
- Developing and managing an action plan to resolve the issue
- Initiating specific task assignments for staff and business partners
- Escalate the incident if required when the goal is not achieved on time
- Ensure internal communication in accordance with service objectives
- Protecting the interests of involved business partners
The first level of support uses a problem management database to match incidents to known errors and apply previously discovered resolutions to incidents. The goal is to resolve 80 percent of incidents. The remaining incidents are transferred (escalated) to the second level.
Continuous improvement of the incident management process. As the owner of a given process, the first level of support ensures that the process is improved when necessary by:
- Assess the effectiveness of the process and support mechanisms such as reports, types of communication and message formats, escalation procedures
- Development of department-specific reports and procedures
- Support and improve communication and escalation lists
- Participation in the problem analysis process
Accurate recording of incidents. The first level of support ensures that information about the incident is recorded in the system log. For this there must be:
Abilities and skills
Interpersonal skills are paramount. First-level support staff are primarily involved in prioritization and problem management. At this level of support, only minor technical research is carried out. Ability to apply “canned” solutions. First-level personnel must be able to recognize symptoms, use search tools to discover previously developed solutions, and assist end users in implementing such solutions.
Second level of support
This level also usually refers to operational services.
Roles
- Incident investigation. The second level of support investigates, diagnoses and resolves most incidents that are not resolved at the first level. These incidents tend to indicate new problems.
- Owner of the problem management process. The second level of support ensures that a well-defined and effective problem management process is in place.
- Proactive infrastructure management. The second level of support uses tools and processes to ensure that problems are identified and resolved before incidents occur.
Responsibilities
- Resolving incidents referred from the first level. If the first level of support is expected to resolve 80% of incidents, then the second level of support is expected to resolve 75% of the incidents referred to it by the first level, that is, 15% of the number of incidents reported. The remaining incidents are transferred to the third level.
- Determining the causes of problems. The second level of support identifies the causes of problems and suggests workarounds or solutions. They engage and manage other resources as needed to determine causes. Problem solving is escalated to the third level when the cause is an architectural or technical issue that exceeds their skill level.
- Ensure that fixes and issues are resolved. The second level of support ensures that projects are initiated within development organizations to implement plans to resolve known issues. They ensure that the solutions found are documented, communicated to first-level personnel, and implemented in tools.
- Constant monitoring of infrastructure. The second level of support attempts to identify problems before incidents occur by monitoring infrastructure components and taking corrective actions when defects or erroneous trends are detected.
- Proactive analysis of incident trends. Incidents that have already occurred are examined to determine whether they indicate problems that need to be corrected to prevent them from causing further incidents. Those incidents that are closed and not mapped to known problems are examined for potential problems.
- Continuous improvement of the problem management process. As the owner of the problem management process, the second level of support ensures that the process and existing capabilities are adequate and improves them when necessary. They conduct problem analysis sessions to identify lessons learned and ensure that process controls, such as meetings and reports, are adequate.
Abilities and skills
- Technically competent with reasonable communication skills. Second level support personnel must have a range of technical skills across all supported technologies, including networks, servers, and applications. A common deficit in second-tier organizations is knowledge of operating systems and applications. There should not be a significant gap between second and third level organizations. Some second-level employees must be as qualified as third-level employees.
- Knowledge of networks, servers and applications. Tier 2 organizations must be able to resolve incidents and problems across the full range of technologies used within the company.
Third level of support
This level of support typically falls within the application development and network infrastructure team.
Roles
- IT infrastructure planning and design. Typically the third level support team plays a small role in incident management and problem management, as such organizations are primarily concerned with planning and designing IT infrastructure. In this capacity, their goal is to implement a defect-free infrastructure that is not the source of problems and incidents.
- The final frontier in escalation. If the incident or problem is beyond the capabilities of the second level support team, then the third level support team takes responsibility for finding a solution.
Responsibilities
- Resolving incidents referred from the second level. Since most incidents are caused by known bugs, very few incidents (5%) make it through the second level to the third. The third level is responsible for resolving all incidents that come to them.
- Participate in problem management activities. The third level of support is involved in finding the causes, workarounds and elimination of errors.
- Implementation of measures to eliminate errors from the infrastructure. The third level has a significant role in planning, designing and implementing projects to address infrastructure deficiencies. The implementation of these projects must be coordinated with regular infrastructure development work to achieve the right balance.
Abilities and skills
- Experts in their respective fields. Level 3 teams should be the experts who plan and design the IT infrastructure.
Processes
There are three main processes associated with incident management and problem management:
- incident management process
- problem control process
- error control process
These core processes are present in almost all advanced organizations, although they may have other names.
Incident management process
This process is focused on restoring the interrupted service as quickly as possible. Table 1 shows the main parameters of this process, and Figure 1 shows a diagram of its operation.
|
Process parameter |
Description |
|---|---|
|
Purpose |
|
|
Owner |
|
|
|
|
|
|
Typical Numerical Parameters |
|
Figure 1. Process model
The problem control process focuses on prioritizing, allocating and monitoring efforts to determine the causes of problems and how to resolve them temporarily or permanently. This process can be likened to project portfolio management, where each problem is a project that must be managed within a portfolio of similar projects. The main parameters of the problem control project are shown in Table 2.
|
Process parameter |
Description |
|---|---|
|
Purpose |
|
|
Owner | |
|
|
|
|
|
Typical Numerical Parameters |
|
Input to a process can come from multiple sources. Typically, high-severity incidents are automatically escalated to the problem management process. In organizations with a strong second level of support, incidents escalated to the third level of support are also routinely routed to the problem control process. Finally, the daily meeting can redirect certain incidents to problem control processes. The process that implements problem control is shown in Figure 2.

Figure 2. Problem Control Process Model
The focus of the problem control process is to determine the causes. The composition of the participants in the cause analysis and the length of time required to complete such an analysis depends on the problem itself. The following statements can be considered correct:
- If you have enough problems, then assign a permanent team. Otherwise, create a team when a problem arises, in much the same way as a team is formed for a project;
- The team should almost always have interdisciplinary experience and knowledge. And this of course depends on the nature of the problem at hand;
- An estimate of the time to determine the cause (develop a project plan) should be given when the problem occurs. The team's progress should be measured against this assessment.
Once resources have been allocated and prioritized, the actual mechanics of determining the cause can take many forms. Such methods of searching for causes as Kepner and Trego analysis, Ishikawa diagrams, Pareto diagrams, etc. have proven themselves well.
Error monitoring provides documentation of methods for overcoming faults and alerting support personnel about them (methods). This also includes maintaining contact with other technical and development organizations, which also helps identify errors. Moreover, error control influences developers to implement fixes for known errors. Table 3 shows the main parameters of the error control process. Figure 3 shows a model of the error control process.
|
Process parameter |
Description |
|---|---|
|
Purpose |
|
|
Owner |
|
|
|
|
|
|
Typical Numerical Parameters |
|

Figure 3. Error Control Process Model
Interactions
Typically, interactions in this process take one of two forms. These are either messages about the status of an incident or problem, which are provided to various groups and/or individuals based on approved rules and templates, or messages about requests that require the recipient to take certain actions, usually containing, in addition to the actual request/demand, a link to the incident, number user's phone number or other link to it.
Many companies rely on the automated messaging capabilities provided by software. Such messages are sent according to strict regulations to maintain escalation. Status messages from software systems are typically generated from data entered into fields on an incident card. Therefore, such messages are often incomplete and scramble-like due to the fact that the fields used to construct automated messages may be irregularly updated with timely information or automatically populated by monitoring software using error message jargon.
To correct these shortcomings, automatic communication capabilities are supplemented, especially in the case of high-severity incidents, with manual messages.
Escalation
Escalation mechanism Helps resolve an incident in a timely manner by increasing personnel capacity, level of effort, and priority focused on resolving the incident. The best organizations have well-defined escalation paths with timelines and responsibilities clearly defined at each step. They use means incident management to automatically transfer responsibility to increasing levels of support according to time constraints and complexity.
Time frames and responsibilities for escalation vary greatly depending on the organization, industry, and level of complexity of the issues. In leading organizations, discussions are held with end users to determine appropriate time frames and escalation of responsibilities. The result of such negotiations is implemented in the form of service level agreements, automated tools, lists, and templates.
Functional escalation
Functional escalation there is an incident escalation to a higher level of support when knowledge or experience is insufficient or the agreed time interval has expired. Advanced organizations define a matrix of severity levels based on the degree of business impact, the time frame for resolving the incident, and the time intervals in which the incident must be escalated to a more advanced team. Table 4 represents such a matrix.
In most organizations, support groups of the first and second levels are focused on the operation of existing infrastructure, while the third level of support is usually provided by groups that are responsible for planning the development of infrastructure and its design. Therefore, careful planning of how responsibility will be functionally transferred to the third level is critical.
|
Incident level |
Description |
Deadline for decision |
First level |
First escalation |
Second escalation |
Third escalation |
|---|---|---|---|---|---|---|
|
More than 50 users cannot perform business transactions |
1st level of support |
2nd level of support |
3rd level of support |
1st manager Emergency meeting |
||
|
10 to 49 users are unable to perform business transactions |
1st level of support |
2nd level of support |
3rd level of support |
1st manager Emergency meeting |
||
|
1 to 9 users cannot perform business transactions |
1st level of support |
2nd level of support |
3rd level of support |
1st manager |
In advanced organizations, a duty pager is usually defined. The manager of each technology group is responsible for preparing a schedule for handling calls received on such pager and ensuring that calls are serviced at all times. In addition, a hierarchical (managerial) escalation procedure must be defined for each technology group. Typically the third level team line manager is the first leader in escalation.
Hierarchical escalation
To ensure that an incident is given the appropriate priority and the necessary resources are allocated before the time frame for resolution is exceeded, hierarchical escalation involves management in the process. Hierarchical escalation can be performed at any level of support. In Table 4, hierarchical escalation occurs in the third escalation step for issues of all severity levels.
In advanced organizations, escalation to management occurs automatically according to a predefined procedure based on the severity of the problem. Once an escalation has occurred, the appropriate manager is expected to actively manage resolution of issues and become the single point of contact for status communications.
Reporting and process improvement
Statistical reports in leading organizations are used for monitoring, continuous process improvement and analysis of performance indicators against the level of service agreed with customers.
For process control incident management and problem management may, for example, use reports containing the values of the following parameters:
- Number of incident cards currently open, broken down by level of importance, time spent, responsibility groups
- Number of problem cards currently open (the cause of which has not yet been identified)
Such reports allow managers to make decisions about the allocation of resources and the direction of staff efforts. Regular use of type parameters:
- Average card processing time at each level
- The number of cards passed and resolved at each level can help identify weaknesses in the IT infrastructure
Finally, a vital set of reports, such as:
- Percentage of incidents resolved within a given time frame
- Average time to restore service allows IT organizations to interact with their consumers and correlate the achieved level of performance with the target level of service
Conclusion
Development of processes and procedures incident management is carried out by many organizations, but not all of these organizations do the same for problem management. This is often due to a lack of clear understanding of the characteristics of these two activities. is the simplest activity to understand because it simply creates a mechanism to respond to service interruptions. Since “the squeaky wheel will always have the grease,” incident management is evolving quite quickly. However, there are often fewer opportunities to develop problem management.
Problem management is more like managing a portfolio of projects, each with the goal of identifying the cause of a problem. Incidents are often the first indicator of a problem and, once faced with an incident, an organization should have a process and procedures in place to determine the cause.
Continuing the project portfolio analogy, the problem management organization must develop a criterion for identifying the problems that should be investigated to determine causes, much in the same way as it does for the decision criterion for choosing a new project. Issues that are not researched continue to be monitored for future research. Once a cause is found and a solution is developed, the organization tracks progress in implementing the solution.
The root cause of an information security incident event is the potential ability of an attacker to gain unreasonable privileges to access an organization's asset. Assessing the risk of such an opportunity and making the right decision to protect is the main task of the response team.
Each risk must be prioritized and treated in accordance with the organization's risk assessment policy. Risk assessment is seen as an ongoing process, the purpose of which is to achieve an acceptable level of protection, in other words, sufficient measures must be put in place to protect the asset from unreasonable or unauthorized use. Risk assessment contributes to asset classification. In the vast majority of cases, assets that are critical from a risk point of view are also critical to the organization’s business.
Response team specialists analyze threats and help maintain the intruder model adopted by the organization’s information security service up to date.
For the response team to work effectively, the organization must have procedures in place to describe the functioning processes of the units. Particular attention should be paid to filling the document base of the information security service.
Detection and analysis of information security incidents
Information security incidents can have different sources of origin. Ideally, an organization should be prepared for any manifestation of malicious activity. In practice this is not feasible.
The response function must classify and describe every incident that occurs in the organization, as well as classify and describe possible incidents that were assumed based on the risk analysis.
To expand the thesaurus about possible threats and possible incidents associated with them, a good practice is to use constantly updated open sources on the Internet.
Signs of an information security incident
The assumption that an information security incident has occurred in an organization should be based on three main factors:
- Information security incident messages are received simultaneously from several sources (users, IDS, log files)
- IDS signal multiple repeating event
- Analysis of the log files of the automated system provides a basis for system administrators to conclude that an incident event may occur.
In general, signs of an incident fall into two main categories, reports that an incident is currently occurring and reports that an incident may occur in the near future. The following are some signs of an event occurring:
- IDS detects buffer overflow
- antivirus program notification
- WEB interface crash
- Users report extremely slow speeds when trying to access the Internet
- the system administrator detects the presence of files with unreadable names
- Users report many duplicate messages in their inboxes
- the host writes to the audit log about the configuration change
- the application records multiple failed authorization attempts in the log file
- the network administrator detects a sharp increase in network traffic, etc.
Examples of events that can serve as sources of information security include:
- server log files record port scans
- announcement in the media about the emergence of a new type of exploit
- an open statement from computer criminals declaring war on your organization, etc.
Analysis of information security incidents
The incident is not an obvious fait accompli; on the contrary, the attackers are trying to do everything not to leave traces of their activities in the system. Signs of an incident include a minor change in the server configuration file or, at first glance, a standard email user complaint. Making a decision about the occurrence of an incident event largely depends on the competence of the experts of the response team. It is necessary to distinguish between an accidental operator error and a malicious, targeted impact on an information system. The fact that an information security incident is handled “idly” is also an information security incident, since it distracts the experts of the response team from pressing problems. The management of the organization should pay attention to this circumstance and provide the experts of the response team with a certain freedom of action.
The compilation of diagnostic matrices serves to visualize the results of the analysis of events occurring in the information system. The matrix is formed from rows of potential signs of an incident and columns of types of incidents. The intersection gives an assessment of the event on the priority scale of “high”, “medium”, “low”. The diagnostic matrix is intended to document the flow of logical conclusions of experts in the decision-making process and, along with other documents, serves as evidence of the investigation of the incident.
Documenting an information security incident
Documenting the events of an information security incident is necessary to collect and subsequently consolidate investigation evidence. All facts and evidence of malicious influence must be documented. A distinction is made between technological evidence and operational evidence of impact. Technological evidence includes information obtained from technical means of collecting and analyzing data (sniffers, IDS); operational evidence includes data or evidence collected during a staff survey, evidence of calls to the service desk, calls to the call center.
A typical practice is to maintain an incident investigation log, which does not have a standard form and is developed by the response team. The key positions of such magazines can be:
- current status of investigation
- description of the incident
- actions performed by the response team during incident processing
- list of investigation actors with a description of their functions and percentage of employment in the investigation procedure
- list of evidence (with mandatory indication of sources) collected during incident processing
font size
NATIONAL STANDARD OF THE RUSSIAN FEDERATION - INFORMATION TECHNOLOGY - METHODS AND MEANS OF SECURITY - MANAGEMENT... Relevant in 2018
6 Examples of information security incidents and their causes
Information security incidents can be intentional or accidental (for example, the result of some human error or natural phenomena) and caused by both technical and non-technical means. Their consequences may include events such as unauthorized disclosure or modification of information, its destruction or other events that make it inaccessible, as well as damage to or theft of the organization's assets. Information security incidents that are not reported but have been identified as incidents cannot be investigated and protective measures cannot be applied to prevent the recurrence of these incidents.
Below are some examples of information security incidents and their causes, which are provided for clarification purposes only. It is important to note that these examples are not exhaustive.
6.1 Denial of service
Denial of service is a broad category of information security incidents that have one thing in common.
Such information security incidents lead to the inability of systems, services or networks to continue functioning with the same performance, most often with a complete denial of access to authorized users.
There are two main types of information security incidents associated with denial of service caused by technical means: resource destruction and resource depletion.
Some typical examples of such intentional technical information security "denial of service" incidents are:
Probing network broadcast addresses in order to completely fill the network bandwidth with response message traffic;
Transmitting data in an unintended format to a system, service or network in an attempt to disrupt or disrupt its normal operation;
Opening multiple sessions simultaneously to a particular system, service, or network in an attempt to exhaust its resources (i.e., slowing it down, blocking it, or destroying it).
Some technical information security "denial of service" incidents may occur accidentally, for example as a result of a configuration error made by an operator or due to incompatibility of application software, while others may be intentional. Some technical information security incidents "denial of service" are initiated intentionally with the aim of destroying a system, service and reducing network performance, while others are just by-products of other malicious activity.
For example, some of the most common covert scanning and identification methods can lead to the complete destruction of old or misconfigured systems or services when they are scanned. It should be noted that many intentional denial-of-service technical incidents are often initiated anonymously (that is, the source of the attack is unknown) because the attacker typically has no knowledge of the network or system being attacked.
IS incidents "denial of service" created by non-technical means and leading to the loss of information, service and (or) information processing devices can be caused, for example, by the following factors:
Violations of physical security systems leading to theft, intentional damage or destruction of equipment;
Accidental damage to the equipment and (or) its location from fire or water/flood;
Extreme environmental conditions, such as high temperatures (due to failure of the air conditioning system);
Incorrect functioning or overload of the system;
Uncontrolled changes in the system;
Incorrect functioning of software or hardware.
6.2 Collection of information
In general terms, information security incidents “gathering information” imply actions related to identifying potential attack targets and obtaining an understanding of the services running on the identified attack targets. Such information security incidents require reconnaissance to determine:
The presence of a target, obtaining an understanding of the network topology surrounding it and with whom this target is usually connected by exchanging information;
Potential vulnerabilities of the target or its immediate surrounding network environment that can be exploited for attack.
Typical examples of attacks aimed at collecting information by technical means are:
Resetting DNS (Domain Name System) records for the target Internet domain (DNS zone transfer);
Sending test requests to random network addresses in order to find working systems;
Probing the system to identify (for example, by file checksum) the host operating system;
Scanning available network ports for the file transfer protocol system in order to identify the corresponding services (for example, email, FTP, network, etc.) and software versions of these services;
Scanning one or more services with known vulnerabilities across a range of network addresses (horizontal scanning).
In some cases, technical information collection expands into unauthorized access if, for example, an attacker tries to gain unauthorized access while searching for a vulnerability. This is usually carried out by automated hacking tools that not only search for vulnerabilities, but also automatically try to exploit vulnerable systems, services and (or) networks.
Intelligence-gathering incidents created by non-technical means result in:
Direct or indirect disclosure or modification of information;
Theft of intellectual property stored in electronic form;
Violation of records, for example, when registering accounts;
Misuse of information systems (for example, in violation of the law or organizational policy).
Incidents may be caused, for example, by the following factors:
Violations of physical security protection leading to unauthorized access to information and theft of storage devices containing sensitive data, such as encryption keys;
Poorly and/or misconfigured operating systems due to uncontrolled changes to the system or malfunctioning software or hardware resulting in organizational personnel or unauthorized personnel accessing information without authorization.
6.3 Unauthorized access
Unauthorized access as an incident type includes incidents that are not included in the first two types. Mainly this type of incident consists of unauthorized attempts to access a system or misuse of a system, service or network. Some examples of unauthorized access by technical means include:
Attempts to extract files with passwords;
Buffer overflow attacks in order to gain privileged (for example, at the system administrator level) access to the network;
Exploiting protocol vulnerabilities to intercept connections or misdirect legitimate network connections;
Attempts to increase access privileges to resources or information beyond those legitimately held by a user or administrator.
Unauthorized access incidents created by non-technical means that result in direct or indirect disclosure or modification of information, accounting violations, or misuse of information systems may be caused by the following factors:
Destruction of physical protection devices with subsequent unauthorized access to information;
Unsuccessful and/or incorrect configuration of the operating system due to uncontrolled changes in the system or malfunction of software or hardware leading to results similar to those described in the last paragraph of 6.2.