Gestión de incidentes y problemas: conceptos y principios. Cómo afrontar incidentes de seguridad de la información
Cuando se manejan múltiples incidentes simultáneamente, es necesaria la priorización. La razón para asignar prioridad es el nivel de importancia del error para la empresa y el usuario. A partir del diálogo con el usuario y de acuerdo con lo establecido en los Acuerdos de Nivel de Servicio (SLA), el Service Desk asigna prioridades que determinan el orden en el que se procesan las incidencias. Cuando los incidentes se derivan a una segunda, tercera o más líneas de soporte, se debe mantener la misma prioridad, pero a veces se puede ajustar consultando con el Service Desk.
impacto del incidente: el grado de desviación del nivel normal de prestación de servicios, expresado en el número de usuarios o procesos comerciales afectados por el incidente;
urgencia del incidente: Un retraso aceptable en la resolución de incidentes para un usuario o proceso comercial.
La prioridad se determina en función de la urgencia y el impacto. Para cada prioridad se determina el número de especialistas y la cantidad de recursos que se pueden destinar a resolver la incidencia. El orden en que se manejan los incidentes de la misma prioridad se puede determinar según el esfuerzo requerido para resolver el incidente. Por ejemplo, un incidente que se resuelve fácilmente puede gestionarse antes que otro que requiera más esfuerzo.
En la Gestión de Incidentes, existen formas de reducir el impacto y la urgencia, como cambiar el sistema a una configuración de respaldo, redirigir la cola de impresión, etc.

Arroz. 4.2. Determinar el impacto, la urgencia y la prioridad
El impacto y la urgencia también pueden cambiar con el tiempo, por ejemplo, a medida que aumenta el número de usuarios afectados por un incidente o en momentos críticos.
El impacto y la urgencia se pueden combinar en una matriz como se muestra en la Tabla 1. 4.1.

Tabla 4.1. Ejemplo de un sistema de codificación de prioridades
Escalada
Si el incidente no puede ser resuelto por la primera línea de soporte dentro del tiempo acordado, se debe incorporar experiencia o autoridad adicional. A esto se le llama escalada, que se produce de acuerdo con las prioridades comentadas anteriormente y, en consecuencia, el tiempo para resolver el incidente.
Existen escalamientos funcionales y jerárquicos:
Escalada funcional (horizontal)– significa involucrar a más especialistas o proporcionar derechos de acceso adicionales para resolver el incidente; al mismo tiempo, es posible que exista una extensión más allá de los límites de un departamento estructural de TI.
Escalada jerárquica (vertical)– significa una transición vertical (a un nivel superior) dentro de la organización, ya que no hay suficiente autoridad organizacional (nivel de autoridad) o recursos para resolver el incidente.
El trabajo del Gerente de Procesos de Gestión de Incidentes es reservar proactivamente oportunidades de escalamiento funcional dentro de las unidades de línea de la organización para que la resolución de incidentes no requiera un escalamiento jerárquico regular. En cualquier caso, las unidades de línea deberán dotar de recursos suficientes para este proceso.
Soporte de primera, segunda y n líneas
La ruta del incidente, o escalamiento funcional, se describió anteriormente. El enrutamiento está determinado por el nivel requerido de conocimiento, autoridad y urgencia. La primera línea de soporte (también llamada soporte de nivel 1) suele ser la mesa de servicio, la segunda línea es la gestión de la infraestructura de TI, la tercera es el desarrollo y la arquitectura de software y la cuarta son los proveedores. Cuanto más pequeña es la organización, menos niveles de escalada tiene. En organizaciones grandes, el Gerente del Proceso de Gestión de Incidentes puede nombrar Coordinadores de Incidentes en los departamentos apropiados para apoyar sus actividades. Por ejemplo, los coordinadores pueden desempeñar el papel de interfaz entre las actividades del proceso y las unidades organizativas de línea. Cada uno de ellos coordina las actividades de sus propios grupos de apoyo. El procedimiento de escalamiento se presenta gráficamente en la Fig. 4.3.

Arroz. 4.3. Escalada de incidentes (fuente: OGC)
4.2. Objetivo
El objetivo del Proceso de Gestión de Incidentes es restaurar el Nivel de Servicio normal tal como se define en el Acuerdo de Nivel de Servicio (SLA) lo más rápido posible, con la mínima pérdida posible para las actividades comerciales de la organización y los usuarios. Además, el Proceso de Gestión de Incidentes debe mantener un registro preciso de los incidentes para evaluar y mejorar el proceso y proporcionar la información necesaria a otros procesos.
4.2.1. Beneficios de utilizar el proceso
Para negocios en general:
Resolución oportuna de incidentes, que conduzcan a una reducción de las pérdidas comerciales;
Mayor productividad del usuario;
Monitoreo de incidentes independiente y centrado en el cliente;
Disponibilidad de información objetiva sobre el cumplimiento de los servicios prestados con los acuerdos acordados (SLA).
Para una organización de TI:
Monitoreo mejorado, que permite una comparación precisa de los niveles de desempeño del sistema de TI con los acuerdos (SLA);
Gestión y seguimiento efectivos de la implementación de acuerdos (SLA) basados en información confiable;
Uso efectivo del personal;
Evitar que los incidentes y Solicitudes de Servicio se pierdan o se registren incorrectamente;
Incrementar la precisión de la información en la Base de Datos de Gestión de Configuración (CMDB) comprobándola al registrar incidentes en relación con los Elementos de Configuración (CI);
Incremento de la satisfacción de usuarios y clientes.
No utilizar el Proceso de Gestión de Incidentes puede tener como resultado las siguientes consecuencias negativas:
Los incidentes pueden perderse o, por el contrario, percibirse injustificadamente como extremadamente graves debido a la ausencia de los responsables del seguimiento y la escalada, lo que puede conducir a una disminución del nivel general del servicio;
Los usuarios pueden ser redirigidos a los mismos especialistas “en círculo” sin lograr resolver la incidencia;
Los profesionales pueden verse constantemente interrumpidos por llamadas telefónicas de los usuarios, lo que les dificulta realizar su trabajo de forma eficaz;
Pueden surgir situaciones en las que varias personas trabajen en el mismo incidente, perdiendo tiempo de forma improductiva y tomando decisiones contradictorias;
Puede haber una falta de información sobre los usuarios y los servicios prestados para apoyar las decisiones de gestión;
Debido a los posibles problemas mencionados anteriormente, el costo para la empresa y la organización de TI de respaldar los servicios será mayor de lo que realmente se requiere.
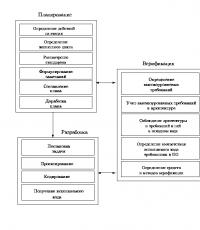
4.3. Proceso
En la Fig. La Figura 4.4 muestra las entradas y salidas de un proceso, así como las actividades que implica el proceso.

Arroz. 4.4. Declaración del proceso de gestión de incidentes
4.3.1. Entradas de proceso
Los incidentes pueden ocurrir en cualquier parte de la infraestructura. A menudo son reportados por los usuarios, pero también pueden ser detectados por empleados de otros departamentos, así como por sistemas de gestión automática configurados para registrar eventos en aplicaciones e infraestructura técnica.
4.3.2. Gestión de configuración
La base de datos de gestión de configuración (CMDB) juega un papel importante en la gestión de incidentes, ya que define la relación entre recursos, servicios, usuarios y niveles de servicio. Por ejemplo, la Gestión de la configuración muestra quién es responsable de un componente de la infraestructura, lo que permite distribuir los incidentes de manera más efectiva entre los equipos. Además, esta base de datos ayuda a resolver problemas operativos como redirigir una cola de impresión o cambiar un usuario a otro servidor. Cuando se registra un incidente, se agrega un enlace al elemento de configuración (CI) correspondiente a los datos de registro, lo que permite proporcionar información más detallada sobre el origen del error. Si es necesario, se puede actualizar el estado del componente correspondiente en la CMDB.
4.3.3. Gestión de problemas
Una gestión eficaz de problemas requiere un registro de incidentes de alta calidad, lo que facilitará enormemente la búsqueda de las causas fundamentales. Por otro lado, la Gestión de Problemas ayuda al Proceso de Gestión de Incidentes proporcionando información sobre problemas, errores conocidos, soluciones alternativas y soluciones rápidas.
4.3.4. Gestión del cambio
Las incidencias se pueden solucionar realizando cambios, como por ejemplo sustituyendo el monitor. La Gestión de Cambios proporciona al Proceso de Gestión de Incidentes información sobre los cambios planificados y sus estados. Además, los cambios pueden provocar incidencias si los cambios se realizan de forma incorrecta o contienen errores. El Proceso de Gestión de Cambios recibe información sobre los mismos del Proceso de Gestión de Incidentes.
4.3.5. Gestión del nivel de servicio
La Gestión del Nivel de Servicio controla la implementación de acuerdos (SLA) con el cliente en relación con el soporte que se le brinda. El personal involucrado en la Gestión de Incidentes debe estar familiarizado con estos acuerdos para poder utilizar la información necesaria al contactar con los usuarios. Además, se requieren registros de incidentes con fines de presentación de informes para verificar que se esté cumpliendo el nivel de servicio acordado.
4.3.6. Gestión de accesibilidad
El Proceso de Gestión de Disponibilidad utiliza registros de incidentes y datos de monitoreo de estado proporcionados por el Proceso de Gestión de Configuración para determinar las métricas de disponibilidad del servicio. De manera similar a un elemento de configuración (CI) en una base de datos de configuración (CMDB), a un servicio también se le puede asignar el estado "fuera de servicio". Esto se puede utilizar para verificar la disponibilidad real del servicio y los tiempos de respuesta del proveedor. Al realizar dicha verificación, es necesario registrar el tiempo de las acciones que ocurrieron durante el proceso de procesamiento del incidente, desde el momento de su detección hasta su cierre.
4.3.7. Gestión de capacidad
El proceso de Gestión de Capacidad recibe información sobre incidentes relacionados con el funcionamiento de los propios sistemas de TI, por ejemplo, incidentes ocurridos por espacio insuficiente en disco o velocidad de respuesta lenta, etc. A su vez, la información sobre estos incidentes puede ingresar al Proceso de Gestión de Incidentes desde el administrador del sistema o desde el propio sistema en función del monitoreo de su condición.
Sin arroz. 4.5. Se muestran los pasos del proceso:

Arroz. 4.5. Proceso de gestión de incidentes
Aceptación y Registro– se recibe el mensaje y se crea un registro de incidencia.
Clasificación y soporte inicial– se asigna el tipo, estado, grado de impacto, urgencia, prioridad del incidente, SLA, etc. Se podrá ofrecer al usuario una posible solución, aunque sea temporal.
Si la llamada se refiere Petición de servicio, entonces se inicia el trámite correspondiente.
Encuadernación (o coincidencia)– comprueba si el incidente ya es un incidente conocido o un error conocido, si ya existe un problema abierto y si existe una solución o solución alternativa conocida.
Investigación y diagnóstico (Investigación y Diagnóstico)– a falta de una solución conocida, se lleva a cabo una investigación del incidente para restablecer el funcionamiento normal lo antes posible.
Resolución y recuperación– si se encuentra una solución, se podrá restablecer el trabajo.
Cierre– Se contacta con el usuario para confirmar la aceptación de la solución propuesta, tras lo cual se puede cerrar la incidencia.
Monitoreo y seguimiento del progreso– se monitorea todo el ciclo de procesamiento de incidentes, y si el incidente no se puede resolver a tiempo, se lleva a cabo una escalada.
4.4. Actividades
4.4.1. Recepción y registro
En la mayoría de los casos, los incidentes son registrados por el Service Desk, donde se reportan los incidentes. Todos los incidentes deben registrarse inmediatamente después de su notificación por las siguientes razones:
Es difícil registrar con precisión información sobre un incidente si no se hace de inmediato;
Monitorear el progreso del trabajo para resolver un incidente solo es posible si el incidente está registrado;
Los incidentes registrados ayudan a diagnosticar nuevos incidentes;
La gestión de problemas puede utilizar incidentes registrados cuando trabaja para encontrar las causas fundamentales;
Es más fácil determinar el grado de impacto si se graban todos los mensajes (llamadas);
Sin registrar incidentes, es imposible monitorear la implementación de los acuerdos (SLA);
El registro inmediato de incidentes evita situaciones en las que varias personas trabajan en la misma llamada o nadie hace nada para resolver el incidente.
La ubicación del incidente está determinada por el origen del mensaje. Los incidentes se pueden detectar de la siguiente manera:
Descubierto por el usuario: Informa del incidente al Service Desk.
Detectado por el sistema: Cuando se detecta un evento en la aplicación o la infraestructura técnica, por ejemplo, cuando se excede un umbral crítico, el evento se registra como un incidente en el sistema de notificación de incidentes y, si es necesario, se escala al equipo de soporte.
Detectado por la mesa de servicio: El empleado registra el incidente.
Descubierto por alguien en otro departamento de TI: Este especialista registra el incidente en el sistema de notificación de incidentes o lo informa al Service Desk.
Debe evitarse la doble grabación del mismo incidente. Por lo tanto, a la hora de registrar una incidencia se debe comprobar si existen incidencias abiertas similares:
Si los hay (y se relacionan con el mismo incidente), se actualiza la información sobre el incidente o se registra el incidente por separado y se establece una conexión (enlace) con el incidente principal; si es necesario, se cambia el nivel de impacto y la prioridad, y se agrega información sobre el nuevo usuario.
Si no (diferente del incidente abierto), se registra una nueva incidencia.
En ambos casos la continuación del proceso es la misma, aunque en el primer caso los pasos posteriores son mucho más sencillos.
Cuando se registra una incidencia se realizan las siguientes acciones:
Asignar un número de incidente: En la mayoría de los casos, el sistema asigna automáticamente un nuevo número de incidente (único). Muchas veces este número se proporciona al usuario para que pueda consultarlo en futuros contactos.
Registro de información de diagnóstico básica: hora, signos (síntomas), usuario, empleado que aceptó el asunto a trámite, localización de la incidencia e información sobre el servicio y/o medio técnico afectado.
Grabar información adicional sobre el incidente.: La información se agrega, por ejemplo, desde un script o procedimiento de sondeo o desde una base de datos de configuración (CMDB) (normalmente basada en las relaciones de elementos de configuración definidas en la CMDB).
Anuncio de alarma: Si ocurre un incidente de alto impacto, como una falla crítica del servidor, se emite una alerta a otros usuarios y a la administración.
4.4.2. Clasificación
La clasificación de incidentes tiene como objetivo definir su categoría para facilitar el seguimiento y la notificación. Es deseable que las opciones de clasificación sean lo más amplias posible, pero esto requiere un mayor nivel de responsabilidad del personal. A veces intentan combinar varios aspectos de la clasificación en una lista, como tipo, grupo de apoyo y fuente. Esto muchas veces causa confusión. Es mejor utilizar varias listas cortas. Esta sección aborda cuestiones relacionadas con la clasificación.
sistema de procesamiento central– subsistema de acceso, servidor central, aplicación.
Neto– enrutadores, segmentos, concentradores, direcciones IP.
Estación de trabajo– monitor, tarjeta de red, unidad de disco, teclado.
Uso y funcionalidad– servicio (servicio), capacidades del sistema, disponibilidad, respaldo (back-up), documentación.
Organización y procedimientos– pedido, solicitud, soporte, notificación (comunicaciones).
Petición de servicio– una solicitud de usuario al Service Desk para soporte, información, documentación o consulta. Esto se puede separar en un procedimiento separado o manejarse de la misma manera que un incidente real.
Una prioridad
Luego se asigna una prioridad para garantizar que el equipo de soporte preste al incidente la atención que necesita. La prioridad es un número determinado por la urgencia (qué tan rápido debe solucionarse) y el impacto (cuánto daño se producirá si no se soluciona rápidamente).
Prioridad = Urgencia x Impacto.
Servicios (servicios)
Para identificar los servicios afectados por el incidente, se puede utilizar una lista de acuerdos de nivel de servicio (SLA) existentes. Esta lista también le permitirá establecer el tiempo de escalamiento para cada uno de los servicios definidos en el SLA.
Grupo de apoyo
Si la mesa de servicio no puede resolver el incidente de inmediato, se asigna un equipo de soporte para resolver el incidente. La base para la distribución de incidentes (enrutamiento) suele ser información de categorías. Al definir las categorías, es posible que sea necesario considerar la estructura de los grupos de apoyo. La distribución adecuada de los incidentes es esencial para la eficacia del Proceso de Gestión de Incidentes. Por lo tanto, uno de los indicadores clave de rendimiento (KPI) del proceso de gestión de incidentes puede ser la cantidad de tickets asignados incorrectamente.
Plazo para la decisión
Teniendo en cuenta la prioridad y acuerdo SLA, se informa al usuario del tiempo máximo estimado para resolver la incidencia. Estos plazos también quedan registrados en el sistema.
Número de identificación del incidente
Se informa al abonado sobre el número de incidencia para su correcta identificación en llamadas posteriores.
Estado
El estado de un incidente indica su posición en el proceso de manejo de incidentes. Ejemplos de estados podrían ser:
Planificado;
Fijado;
Activo;
Aplazado;
Permitido;
4.4.3. Encuadernación (mapeo)
Después de la clasificación, se comprueba si ha ocurrido un incidente similar antes y si existe una solución o solución alternativa ya preparada. Si un incidente tiene las mismas características que un problema abierto o un error conocido, se puede vincular a él.
4.4.4. Investigación y diagnóstico.
El Service Desk o el equipo de soporte escala los incidentes que no tienen solución o están más allá de las capacidades de la persona que trabaja con ellos al equipo de soporte del siguiente nivel con más experiencia y conocimiento. Este equipo investiga y resuelve el incidente o lo escala al siguiente nivel del equipo de soporte.
Durante el proceso de resolución de incidentes, diversos especialistas pueden actualizar el registro de incidentes cambiando el estado actual, información sobre acciones tomadas, revisando la clasificación y actualizando el tiempo y código del empleado.
4.4.5. Solución y recuperación
Tras completar con éxito el análisis y resolver la incidencia, el empleado registra la solución en el sistema. En algunos casos, es necesario enviar una Solicitud de Cambio (RFC) al Proceso de Gestión de Cambios. En el peor de los casos, si no se encuentra una solución, el incidente queda abierto.
4.4.6. Clausura
Una vez que se implementa una solución a satisfacción del usuario, el equipo de soporte remite el incidente a la mesa de servicio. Este servicio contacta al empleado que reportó el incidente para obtener confirmación de que el problema se ha resuelto exitosamente. Si confirma esto, entonces el incidente puede cerrarse; de lo contrario, el proceso se reanuda en el nivel apropiado. Cuando se cierra un incidente, es necesario actualizar la categoría final, la prioridad, los servicios afectados por el incidente y el elemento de configuración (CI) que causó la falla.
4.4.7. Monitoreo y seguimiento del progreso de la solución
En la mayoría de los casos, el Service Desk, como “dueño” de todas las incidencias, es el responsable de monitorear el progreso de la resolución. Este servicio también debe informar al usuario sobre el estado de la incidencia. Los comentarios de los usuarios pueden ser apropiados después de un cambio de estado, como escalar un incidente a la siguiente línea de soporte, cambiar el tiempo estimado de resolución, escalar, etc. Durante el monitoreo, es posible escalar funcionalmente a otros grupos de soporte o escalar jerárquicamente para tomar decisiones ejecutivas. .
4.5. Control de procesos
La base para el control de procesos son los informes para distintos grupos destinatarios. El Gerente de Proceso de Gestión de Incidentes es responsable de estos informes, así como de la lista de correo y el cronograma de informes. Los informes podrán incluir información especializada para las siguientes unidades funcionales:
El Gerente del Proceso de Gestión de Incidentes necesita el informe para:
Identificación de eslabones faltantes en el proceso;
Identificación de violaciones de los Acuerdos de Nivel de Servicio (SLA);
Seguimiento del avance del proceso;
Determinación de tendencias de desarrollo.
Gestión de Departamentos TI Lineales– informe para la gestión del grupo de apoyo; También puede ser útil en la gestión del departamento de TI. El informe debe contener la siguiente información:
Avances en la resolución de incidencias;
Tiempo para resolver incidencias en diversos grupos de soporte.
Gestión del nivel de servicio– el informe debe contener, en primer lugar, información sobre la calidad de los servicios prestados. El Gerente de Proceso de Gestión de Nivel de Servicio debe recibir toda la información necesaria para preparar Informes de Nivel de Servicio para los clientes. Los informes a los clientes deben proporcionar información sobre si se están cumpliendo los acuerdos de Nivel de Servicio dentro del Proceso de Gestión de Incidentes.
Responsables de otros procesos de Gestión de Servicios TI– Los informes para los responsables de otros procesos deben, ante todo, ser informativos, es decir, contener toda la información que necesitan. Por ejemplo, un Proceso de Gestión de Incidentes basado en registros de incidentes podría proporcionar la siguiente información:
Número de incidentes detectados y registrados;
Número de incidentes resueltos, dividido por el tiempo de resolución;
Estado y número de incidentes no resueltos;
Incidencias por periodo de ocurrencia, grupos de clientes, grupos de soporte y tiempo de resolución de acuerdo al acuerdo (SLA);
4.5.1. Factores críticos del éxito
La gestión exitosa de incidentes requiere lo siguiente:
Una base de datos de configuración (CMDB) actualizada para ayudar a evaluar el impacto y la urgencia de los incidentes. Esta información también se puede obtener del usuario, pero en este caso puede ser menos completa y bastante subjetiva, lo que provocará un aumento del tiempo de resolución de incidencias.
Para evaluar el desempeño del proceso, es necesario definir claramente los parámetros de control y puntajes mensurables, a menudo llamados indicadores de desempeño. Estas métricas se informan periódicamente, por ejemplo una vez por semana, para proporcionar una imagen de los cambios a partir de la cual se pueden identificar tendencias. Ejemplos de tales parámetros son:
Número total de incidentes;
Tiempo medio de resolución de incidencias;
Tiempo medio de resolución de incidencias por prioridad;
Número promedio de incidentes resueltos dentro de los SLA;
Porcentaje de incidentes resueltos por la primera línea de soporte (sin derivación a otros grupos);
Costo promedio de soporte por incidente;
Número de incidentes resueltos por lugar de trabajo o por empleado de Service Desk;
Incidencias resueltas sin visitar al usuario (de forma remota);
Número (o porcentaje) de incidentes con clasificación inicialmente incorrecta;
Número (o porcentaje) de incidentes asignados incorrectamente a grupos de apoyo.
4.5.3. Funciones y roles
La implementación de procesos se realiza en un plano horizontal a través de la estructura jerárquica de la organización. Esto sólo es posible con una definición clara de las responsabilidades y autoridades asociadas a la implementación de los procesos. Para aumentar la flexibilidad, se puede utilizar un enfoque basado en roles (es decir, definir roles). En organizaciones pequeñas o para reducir costos generales, es posible combinar roles, por ejemplo, combinando los roles de Gestión de Cambios y Gerente de Procesos de Gestión de Configuración.
Responsable de Procesos de Gestión de Incidentes
En muchas organizaciones, la función de administrador de gestión de incidentes la desempeña el administrador de la mesa de servicio. Las responsabilidades del Gerente de Proceso de Gestión de Incidentes incluyen lo siguiente:
Seguimiento de la eficiencia y racionalidad del proceso;
Seguimiento del trabajo de los grupos de apoyo;
Desarrollo y mantenimiento del sistema de Gestión de Incidentes.
Personal del grupo de apoyo
La primera línea de soporte se encarga de registrar, clasificar, emparejar (vincular), asignar a grupos de apoyo, resolver y cerrar incidencias.
El resto de equipos de soporte se dedican principalmente a investigar, diagnosticar y resolver incidentes dentro de las prioridades establecidas.
4.6. Costos y problemas
4.6.1. Gastos
Los costos asociados con la Gestión de Incidentes incluyen costos de implementación inicial (por ejemplo, costos de desarrollo de procesos, capacitación y entrenamiento del personal), selección y adquisición de herramientas para respaldar el proceso. La selección de herramientas puede llevar una cantidad significativa de tiempo. Además, existen costos operativos asociados con el pago del personal y el uso de herramientas. Estos costos dependen en gran medida de la estructura de la Gestión de Incidentes, la gama de actividades incluidas en el proceso, las áreas de responsabilidad y el número de departamentos.
4.6.2. Problemas
Al implementar la Gestión de Incidentes, pueden surgir los siguientes problemas:
Usuarios y profesionales de TI trabajan en torno a los procedimientos de gestión de incidentes.– si los usuarios resuelven los errores ellos mismos o contactan directamente a los especialistas sin seguir los procedimientos establecidos, la organización de TI no recibirá información sobre el nivel de servicio real proporcionado, la cantidad de errores y mucho más. Los informes a la dirección tampoco reflejarán adecuadamente la situación.
Sobrecarga de incidentes y procrastinación “para más tarde”– si hay un aumento inesperado en el número de incidentes, es posible que no haya tiempo suficiente para un registro correcto, ya que antes de que termine de ingresar información sobre el incidente de un usuario, es necesario atender al siguiente. En este caso, la entrada de descripciones de incidentes puede no ser lo suficientemente precisa y los procedimientos para distribuir incidentes a los grupos de apoyo no se llevarán a cabo correctamente. Como resultado, las decisiones son de mala calidad y la carga de trabajo aumenta aún más. En los casos en que el número de incidentes abiertos comienza a aumentar rápidamente, un procedimiento para la asignación de emergencia de recursos adicionales dentro de la organización puede evitar la sobrecarga de personal.
Escalada– Como es sabido, la escalada de incidentes es posible dentro del Proceso de Gestión de Incidentes. Demasiadas escaladas pueden tener un impacto negativo en el trabajo de los especialistas, que por lo tanto se ven apartados de su trabajo planificado.
Falta de un catálogo de servicios y acuerdos de nivel de servicio (SLA)– Si los servicios y productos admitidos no están bien definidos, puede resultar difícil para quienes participan en la gestión de incidentes rechazar razonablemente la asistencia a los usuarios.
Falta de compromiso Enfoque de proceso por parte de la dirección y el personal.– la resolución de incidentes utilizando un enfoque de procesos generalmente requiere un cambio de cultura y un mayor nivel de responsabilidad por su trabajo por parte del personal. Esto puede causar una resistencia significativa dentro de la organización. La gestión eficaz de incidentes requiere que los empleados comprendan y se comprometan verdaderamente con un enfoque de proceso en lugar de simplemente participar.
Notas:
La “cadena” se refiere a la cadena de creación de plusvalía. – Aprox. ed.
En la literatura ITIL, el concepto de "función" está asociado con una división vertical (línea) de una organización que desempeña las responsabilidades funcionales correspondientes y, de hecho, es sinónimo de ella. – Aprox. ed.
Petición de servicio.
Solicitud de cambio (RFC).
Elemento de configuración (CI).
Indicadores clave de rendimiento: KPI.
Indicadores de desempeño.
Eficacia y eficiencia.
Aquellos. software. – Aprox. ed.
Garantizar la seguridad de la información empresarial Andrianov V.V.
4.1.4. Ejemplos de incidentes
4.1.4. Ejemplos de incidentes
información general
Esta sección describe los detalles publicados de algunos de los incidentes de alto perfil. Al mismo tiempo, la generalización de los incidentes proporciona una gran cantidad de circunstancias que caracterizan la variedad de amenazas a la seguridad de la información por parte del personal, tanto en términos de motivos y condiciones como en términos de los medios utilizados. Entre los incidentes más frecuentes destacamos los siguientes:
Fuga de información oficial;
Robo de clientes y negocios de la organización;
Sabotaje de infraestructura;
Fraude interno;
Falsificación de informes;
Negociar en mercados basados en información privilegiada y patentada;
Abuso de autoridad.
anotación
En represalia por una bonificación demasiado pequeña, Roger Duronio, de 63 años (ex administrador de sistemas de la UBS Paine Webber), instaló una "bomba lógica" en los servidores de la empresa, que destruyó todos los datos y paralizó el trabajo de la empresa durante mucho tiempo.
Descripción del incidente
Duronio estaba insatisfecho con su salario de 125.000 dólares al año, lo que pudo haber sido el motivo de la introducción de la bomba lógica. Sin embargo, la gota que colmó el vaso para el administrador del sistema fue la bonificación que recibió de 32.000 dólares en lugar de los 50.000 dólares esperados. Cuando descubrió que su bonificación era mucho menor de lo que esperaba, Duronio exigió a su jefe que renegociara su contrato de trabajo por 175.000 dólares al año o dejaría la empresa. Le negaron un aumento de sueldo y también le pidieron que abandonara el edificio del banco. En represalia por tal trato, Duronio decidió utilizar su “invento”, introducido de antemano, anticipándose a tal giro de los acontecimientos.
Duronio implementó la “bomba lógica” desde la computadora de su casa varios meses antes de recibir lo que consideraba una bonificación demasiado pequeña. La bomba lógica se instaló en aproximadamente 1.500 computadoras en una red de sucursales en todo el país y se programó a una hora específica: las 9:30, justo a tiempo para el inicio del día bancario.
Duronio renunció a UBS Paine Webber el 22 de febrero de 2002 y el 4 de marzo de 2002, una bomba lógica eliminó secuencialmente todos los archivos en el servidor de base de datos central principal y 2.000 servidores en las 400 sucursales del banco, al tiempo que deshabilitaba el sistema de respaldo.
Durante el juicio, el abogado de Duronio señaló que el culpable del incidente no podía ser solo el acusado: dada la inseguridad de los sistemas informáticos de la UBS Paine Webber, cualquier otro empleado podría haber llegado allí con el login de Duronio. Los problemas con la seguridad informática en el banco se conocieron en enero de 2002: durante una auditoría se descubrió que 40 personas del servicio informático podían iniciar sesión en el sistema y obtener derechos de administrador utilizando la misma contraseña, y comprender quién lo hizo exactamente o quién otra acción no fue posible. El abogado también acusó a la UBS Paine Webber y a la empresa @Stake, contratada por el banco para investigar el incidente, de destruir pruebas del ataque. Sin embargo, la evidencia irrefutable de la culpabilidad de Duronio fueron los fragmentos de código malicioso encontrados en las computadoras de su casa y una copia impresa del código en su armario.
Oportunidades internas
Como uno de los administradores de sistemas de la empresa, a Duronio se le asignó la responsabilidad y el acceso a toda la red informática de UBS PaineWebber. También tenía acceso a la red desde la computadora de su casa a través de una conexión segura a Internet.
Causas
Como se dijo anteriormente, sus motivos eran el dinero y la venganza. Duronio recibió un salario anual de 125.000 dólares y un bono de 32.000 dólares, mientras esperaba 50.000 dólares, y así se vengó de su decepción.
Además, Duronio decidió ganar dinero con el ataque: previendo una caída de las acciones del banco debido a un desastre informático, hizo una orden de venta de futuros para recibir la diferencia cuando el tipo bajara. El acusado gastó 20.000 dólares en esto. Sin embargo, los títulos del banco no cayeron y las inversiones de Duronio no dieron sus frutos.
Consecuencias
La “bomba lógica” colocada por Duronio paró el funcionamiento de 2.000 servidores en 400 oficinas de la empresa. Según Elvira María Rodríguez, gerente de TI de la UBS Paine Webber, fue un desastre “más de 10 en una escala de 10”. El caos reinaba en la empresa, que tuvo que eliminar a 200 ingenieros de IBM durante casi un día. En total, unos 400 especialistas trabajaron para corregir la situación, incluido el servicio informático del propio banco. Los daños causados por el incidente se estiman en 3,1 millones de dólares. Ocho mil corredores en todo el país se vieron obligados a dejar de trabajar. Algunos de ellos pudieron volver a sus operaciones normales después de unos días, otros después de algunas semanas, dependiendo de cuán gravemente se vieron afectadas sus bases de datos y si la sucursal bancaria tenía copias de seguridad. En general, las operaciones bancarias se reanudaron a los pocos días, pero algunos servidores nunca se restauraron por completo, en gran parte debido a que el 20% de los servidores no contaban con instalaciones de respaldo. Sólo un año después, todo el parque de servidores del banco fue completamente restaurado.
Durante el juicio de Duronio ante los tribunales, fue acusado de los siguientes cargos:
Fraude de valores: este cargo conlleva una pena máxima de 10 años en una prisión federal y una multa de 1 millón de dólares;
Fraude informático: este cargo conlleva una pena máxima de 10 años de prisión y una multa de 250.000 dólares.
Como resultado del juicio de finales de diciembre de 2006, Duronio fue condenado a 97 meses sin libertad condicional.
"Vimpelcom" y "Sherlock"
anotación
Con fines de lucro, ex empleados de la empresa VimpelCom (marca comercial Beeline) ofrecieron detalles de conversaciones telefónicas de operadores de telefonía móvil a través del sitio web.
Descripción del incidente
Los empleados de la empresa VimpelCom (antiguos y actuales) organizaron el sitio web www.sherlok.ru en Internet, del que la empresa VimpelCom tuvo conocimiento en junio de 2004. Los organizadores de este sitio ofrecieron un servicio: buscar personas por apellido, número de teléfono y otros datos. En julio, los organizadores del sitio ofrecieron un nuevo servicio: detallar las conversaciones telefónicas de los operadores de telefonía móvil. El detalle de llamadas es una copia impresa de los números de todas las llamadas entrantes y salientes, que indica la duración de las llamadas y su costo, que utilizan los operadores, por ejemplo, para facturar a los suscriptores. A partir de estos datos podemos sacar una conclusión sobre las actividades actuales del suscriptor, su área de interés y su círculo de conocidos. En el comunicado de prensa de la Dirección "K" del Ministerio del Interior (en adelante Ministerio del Interior) se aclara que dicha información le cuesta al cliente 500 dólares.
Los empleados de la empresa VimpelCom, al descubrir este sitio, recopilaron de forma independiente pruebas de las actividades delictivas del sitio y transfirieron el caso al Ministerio del Interior. Los empleados del Ministerio del Interior abrieron una causa penal y, junto con la empresa VimpelCom, establecieron la identidad de los organizadores de este negocio criminal. Y el 18 de octubre de 2004, el principal sospechoso 1 fue detenido con las manos en la masa.
Además, el 26 de noviembre de 2004 fueron detenidos los seis sospechosos restantes, entre ellos tres empleados del servicio de abonados de la propia empresa VimpelCom. Durante la investigación resultó que el sitio fue creado por un ex alumno de la Universidad Estatal de Moscú que no trabajaba para esta empresa.
Los trámites sobre este incidente fueron posibles gracias a la sentencia del Tribunal Constitucional de 2003, que reconoció que los datos de las llamadas contenían el secreto de las conversaciones telefónicas, protegido por la ley.
Oportunidades internas
Dos de los empleados de VimpelCom identificados entre los participantes en el incidente trabajaban como cajeros en la empresa, y el tercero era un ex empleado y trabajaba en el mercado Mitinsky en el momento del crimen.
Trabajar como cajeros en la propia empresa indica que estos empleados tenían acceso directo a la información puesta a la venta en el sitio web www.sherlok.ru. Además, dado que un ex empleado de la empresa ya trabajaba en el mercado Mitinsky, se puede suponer que con el tiempo este mercado también podría convertirse en uno de los canales de distribución de esta información o cualquier otra información de las bases de datos de la empresa VimpelCom.
Consecuencias
Las principales consecuencias de este incidente para VimpelCom podrían ser un duro golpe a la reputación de la propia empresa y la pérdida de clientes. Sin embargo, este incidente se hizo público directamente gracias a las acciones activas de la propia empresa.
Además, hacer pública esta información podría tener un impacto negativo en los clientes de VimpelCom, ya que el detalle de las conversaciones permite sacar una conclusión sobre las actividades actuales del suscriptor, su área de interés y círculo de conocidos.
En marzo de 2005, el Tribunal de Distrito de Ostankino de Moscú condenó a los sospechosos, entre ellos tres empleados de la empresa VimpelCom, a diversas multas. Así, el organizador del grupo fue multado con 93.000 rublos. Sin embargo, el funcionamiento del sitio web www.sherlok.ru no se suspendió indefinidamente hasta el 1 de enero de 2008.
La mayor filtración de datos personales en la historia de Japón
anotación
En el verano de 2006 se produjo la mayor filtración de datos personales en la historia de Japón: un empleado del gigante de la impresión y la electrónica Dai Nippon Printing robó un disco con información privada de casi nueve millones de ciudadanos.
Descripción del incidente
La empresa japonesa Dai Nippon Printing, especializada en la producción de productos impresos, permitió la mayor filtración en la historia de su país. Hirofumi Yokoyama, un ex empleado de uno de los contratistas de la empresa, copió datos personales de los clientes de la empresa en un disco duro móvil y los robó. Un total de 8,64 millones de personas estaban en riesgo porque la información robada incluía nombres, direcciones, números de teléfono y números de tarjetas de crédito. La información robada incluía información de clientes de 43 empresas diferentes, como 1.504.857 clientes de American Home Assurance, 581.293 clientes de Aeon Co y 439.222 clientes de NTT Finance.
Después del robo de esta información, Hirofumi abrió el comercio de información privada en porciones de 100.000 registros. Gracias a unos ingresos estables, el informante incluso dejó su trabajo permanente. En el momento de su arresto, Hirofumi había logrado vender los datos de 150.000 clientes de las mayores firmas de crédito a un grupo de estafadores especializados en compras en línea. Además, algunos de los datos ya se han utilizado para fraudes con tarjetas de crédito.
Más de la mitad de las organizaciones cuyos datos de clientes fueron robados ni siquiera fueron advertidas sobre la filtración de información.
Consecuencias
Como resultado de este incidente, las pérdidas de los ciudadanos que sufrieron debido al fraude con tarjetas de crédito, que sólo fue posible gracias a esta filtración, ascendieron a varios millones de dólares. En total, los clientes de 43 empresas diferentes se vieron afectados, incluidas Toyota Motor Corp., American Home Assurance, Aeon Co y NTT Finance. Sin embargo, más de la mitad de las organizaciones ni siquiera fueron advertidas sobre la filtración.
En 2003, Japón aprobó la Ley de Protección de Información Personal de 2003 (PIPA), pero los fiscales no pudieron aplicarla en el juicio real del caso a principios de 2007. La fiscalía no pudo acusar al informante de violar la PIPA. Sólo se le acusa de robar un disco duro valorado en 200 dólares.
No apreciado. Hacker de Zaporozhye contra un banco ucraniano
anotación
El ex administrador de sistemas de uno de los grandes bancos de Ucrania transfirió alrededor de 5 millones de grivnas a través del banco donde trabajaba anteriormente desde la cuenta de la aduana regional a la cuenta de una inexistente empresa en quiebra de Dnepropetrovsk.
Descripción del incidente
Su carrera como administrador de sistemas comenzó después de graduarse de la escuela técnica y fue contratado por uno de los grandes bancos de Ucrania en el departamento de software y hardware. Después de un tiempo, la dirección se dio cuenta de su talento y decidió que sería más útil para el banco como jefe de departamento. Sin embargo, la llegada de una nueva dirección al banco también supuso cambios de personal. Se le pidió que dejara temporalmente su puesto. Pronto, la nueva dirección comenzó a formar su equipo, pero su talento resultó no ser reclamado y le ofrecieron el inexistente puesto de subjefe, pero en otro departamento. Como resultado de tales cambios de personal, comenzó a hacer algo completamente diferente de lo que mejor conocía.
El administrador del sistema no pudo soportar esta actitud de gestión hacia sí mismo y renunció por su propia voluntad. Sin embargo, lo perseguía su propio orgullo y resentimiento hacia la gerencia, además, quería demostrar que era el mejor en su negocio y regresar al departamento donde comenzó su carrera.
Después de dimitir, el ex administrador del sistema decidió devolver el interés de la antigua dirección a su persona utilizando las imperfecciones del sistema "Banco-Cliente" utilizado en casi todos los bancos de Ucrania 2 . El plan del administrador del sistema era que decidió desarrollar su propio programa de seguridad y ofrecerlo al banco, regresando a su anterior lugar de trabajo. La implementación del plan consistió en penetrar el sistema Banco-Cliente y realizar cambios mínimos en él. Todo el cálculo se basó en el hecho de que el banco habría descubierto un hackeo del sistema.
Para penetrar en el sistema especificado, el ex administrador del sistema utilizó contraseñas y códigos que aprendió mientras trabajaba con este sistema. Toda la demás información necesaria para la piratería se obtuvo de varios sitios de piratas informáticos, donde se describieron en detalle varios casos de piratería de redes informáticas, técnicas de piratería y todo el software necesario para la piratería.
Habiendo creado una laguna en el sistema, el ex administrador del sistema penetraba periódicamente en el sistema informático del banco y dejaba varios carteles en él, tratando de llamar la atención sobre los hechos de la piratería. Los especialistas del banco debían detectar el hackeo y hacer sonar la alarma, pero, para su sorpresa, nadie se dio cuenta de la penetración en el sistema.
Entonces el administrador del sistema decidió cambiar su plan, haciéndole ajustes que no podían pasar desapercibidos. Decidió falsificar una orden de pago y utilizarla para transferir una gran cantidad a través del sistema informático del banco. Utilizando un ordenador portátil y un teléfono móvil con módem incorporado, el administrador del sistema penetró en el sistema informático del banco unas 30 veces: revisó documentos, cuentas de clientes, flujos de efectivo, en busca de clientes adecuados. Como tales clientes eligió las aduanas regionales y una empresa en quiebra de Dnepropetrovsk.
Una vez más tuvo acceso al sistema del banco, creó una orden de pago en la que retiró 5 millones de jrivnia de la cuenta personal de la aduana regional y los transfirió a través del banco a la cuenta de la empresa en quiebra. Además, cometió deliberadamente varios errores en el “pago”, lo que a su vez debería haber ayudado a atraer la atención de los especialistas bancarios. Sin embargo, ni siquiera estos hechos fueron notados por los especialistas bancarios que atienden el sistema Banco-Cliente y transfirieron tranquilamente 5 millones de jrivnia a la cuenta de una empresa desaparecida.
En realidad, el administrador del sistema esperaba que los fondos no fueran transferidos, que el hecho de la piratería se descubriera antes de que se transfirieran los fondos, pero en la práctica todo resultó diferente y se convirtió en un delincuente y su transferencia falsa se convirtió en robo.
El hecho de la piratería y el robo de fondos a una escala especialmente grande se descubrió sólo unas horas después de la transferencia, cuando los empleados del banco llamaron a la aduana para confirmar la transferencia. Pero informaron que nadie había transferido tal cantidad. El dinero fue devuelto urgentemente al banco y se abrió una causa penal en la fiscalía de la región de Zaporozhye.
Consecuencias
El banco no sufrió pérdidas, ya que el dinero fue devuelto al propietario y el sistema informático sufrió daños mínimos, por lo que la dirección del banco rechazó cualquier reclamación contra el ex administrador del sistema.
En 2004, por decreto del Presidente de Ucrania, se reforzó la responsabilidad penal por delitos informáticos: multas de 600 a 1.000 mínimos libres de impuestos y penas de prisión de 3 a 6 años. Sin embargo, el exadministrador del sistema cometió un delito antes de que entrara en vigor el decreto presidencial.
A principios de 2005 se llevó a cabo un juicio contra el administrador del sistema. Fue acusado de cometer un delito previsto en la parte 2 del artículo 361 del Código Penal de Ucrania (intervención ilegal en el funcionamiento de sistemas informáticos que causan daños) y en virtud de la parte 5 del artículo 185 (robo cometido a gran escala). Pero como la dirección del banco se negó a presentar reclamaciones contra él, se le retiró el cargo de robo y la parte 2 del artículo 361 se cambió a la parte 1: interferencia ilegal en el funcionamiento de los sistemas informáticos.
Comercio incontrolado en el banco Societe Generale
anotación
El 24 de enero de 2008, Société Générale anunció una pérdida de 4.900 millones de euros debido a las maquinaciones de su comerciante Jerome Kerviel. Como demostró una investigación interna, durante varios años el comerciante abrió posiciones por encima del límite en futuros sobre índices bursátiles europeos. El importe total de las posiciones abiertas ascendió a 50 mil millones de euros.
Descripción del incidente
Desde julio de 2006 hasta septiembre de 2007, el sistema informático de control interno advirtió sobre posibles violaciones 75 veces (es decir, cuántas veces Jerome Kerviel realizó transacciones no autorizadas o sus posiciones excedieron el límite permitido). Los empleados del departamento de seguimiento de riesgos del banco no realizaron controles detallados de estas advertencias.
Kerviel comenzó a experimentar con operaciones no autorizadas en 2005. Luego tomó una posición corta en acciones de Allianz, esperando que el mercado cayera. Pronto el mercado cayó realmente (después de los ataques terroristas en Londres), así se ganaron los primeros 500.000 euros. Más tarde, Kerviel contó a los investigadores sus sentimientos sobre su primer éxito: “Ya sabía cómo cerrar mi posición y estaba orgulloso del resultado, pero al mismo tiempo estaba sorprendido. El éxito me hizo continuar, fue como una bola de nieve... En julio de 2007, propuse tomar una posición corta en previsión de una caída del mercado, pero no recibí el apoyo de mi gerente. Mi pronóstico se cumplió y obtuvimos ganancias, esta vez fue completamente legal. Posteriormente, seguí realizando tales operaciones en el mercado, ya sea con el consentimiento de mis superiores o en ausencia de su objeción explícita... El 31 de diciembre de 2007, mi beneficio alcanzó los 1,4 mil millones de euros. En ese momento no sabía cómo declarar esto a mi banco, ya que era una cantidad muy grande que no estaba declarada en ningún lado. Estaba feliz y orgulloso, pero no sabía cómo explicarle a mi dirección la recepción de este dinero y no incurrir en sospechas de realizar transacciones no autorizadas. Por lo tanto, decidí ocultar mis ganancias y realizar la operación ficticia opuesta…”
De hecho, a principios de enero de ese año, Jerome Kerviel volvió a entrar en juego con contratos de futuros sobre los tres índices Euro Stoxx 50, DAX y FTSE, que le ayudaron a ganarle al mercado a finales de 2007 (aunque prefirió quedarse corto en el mercado). tiempo). Según los cálculos, en vísperas del 11 de enero, su cartera contenía 707,9 mil futuros (cada uno con un valor de 42,4 mil euros) sobre el Euro Stoxx 50, 93,3 mil futuros (192,8 mil euros por pieza) sobre el DAX y 24,2 mil futuros (82,7 mil euros). por 1 contrato) para el índice FTSE. En total, la posición especulativa de Kerviel equivalía a 50 mil millones de euros, es decir, superaba el valor del banco en el que trabajaba.
Conociendo el momento de los controles, abrió una posición de cobertura ficticia en el momento adecuado, que luego cerró. Como resultado, los revisores nunca vieron una sola posición que pudiera considerarse arriesgada. No deberían alarmarse por las grandes cantidades de transacciones, que son bastante comunes en el mercado de futuros sobre índices. Lo decepcionaron las transacciones ficticias realizadas desde las cuentas de los clientes del banco. El uso de cuentas de varios clientes bancarios no generó problemas visibles para los controladores. Sin embargo, con el tiempo, Kerviel comenzó a utilizar las cuentas de los mismos clientes, lo que provocó que se observara una actividad "anormal" en estas cuentas y, a su vez, atrajo la atención de los controladores. Este fue el final de la estafa. Resultó que el socio de Kerviel en el acuerdo multimillonario era un gran banco alemán, que supuestamente confirmó la astronómica transacción por correo electrónico. Sin embargo, la confirmación electrónica levantó sospechas entre los inspectores y se creó una comisión en Societe Generale para verificarlas. El 19 de enero, en respuesta a una solicitud, el banco alemán no reconoció esta transacción, tras lo cual el comerciante accedió a confesar.
Cuando fue posible conocer el tamaño astronómico de la posición especulativa, el director general y presidente del consejo de administración de Société Générale, Daniel Bouton, anunció su intención de cerrar la posición de riesgo abierta por Kerviel. Esto duró dos días y provocó pérdidas de 4.900 millones de euros.
Oportunidades internas
Jerome Kerviel trabajó durante cinco años en el llamado back office del banco, es decir, en un departamento que no realiza transacciones directamente. Se ocupa únicamente de la contabilidad, ejecución y registro de transacciones y monitorea a los comerciantes. Esta actividad nos permitió comprender las características de los sistemas de control del banco.
En 2005, Kerviel fue ascendido. Se convirtió en un verdadero comerciante. Las responsabilidades inmediatas del joven incluían operaciones básicas para minimizar riesgos. Jerome Kerviel, que trabajaba en el mercado de futuros sobre índices bursátiles europeos, tenía que controlar cómo cambiaba la cartera de inversiones del banco. Y su tarea principal, como explicó un representante de Societe Generale, era reducir los riesgos jugando en la dirección opuesta: "En términos generales, como el banco apostaba al rojo, tuvo que apostar al negro". Como todos los traders junior, Kerviel tenía un límite que no podía superar y que era supervisado por sus antiguos colegas en el back office. Societe Generale tenía varias capas de protección; por ejemplo, los operadores sólo podían abrir posiciones desde la computadora de su trabajo. Todos los datos sobre las posiciones abiertas se transmitieron automáticamente en tiempo real al back office. Pero, como suele decirse, el mejor cazador furtivo es un ex guardabosques. Y el banco cometió un error imperdonable al poner al ex guardabosques en la posición de cazador. A Jerome Kerviel, que tenía casi cinco años de experiencia en el seguimiento de comerciantes, no le resultó difícil eludir este sistema. Conocía las contraseñas de otras personas, sabía cuándo se realizaban los cheques en el banco y conocía bien la tecnología de la información.
Causas
Si Kerviel estuvo involucrado en fraude, no fue con el propósito de enriquecimiento personal. Así lo afirman sus abogados, y los representantes del banco también lo admiten, calificando de irracionales las acciones de Kerviel. El propio Kerviel dice que actuó únicamente en interés del banco y sólo quería demostrar su talento como comerciante.
Consecuencias
A finales de 2007, sus actividades aportaron al banco unos beneficios de unos 2.000 millones de euros. En cualquier caso, esto es lo que dice el propio Kerviel, afirmando que la dirección del banco probablemente sabía lo que estaba haciendo, pero prefirió hacer la vista gorda mientras fuera rentable.
El cierre de la posición de riesgo abierta por Kerviel supuso unas pérdidas de 4.900 millones de euros.
En mayo de 2008, Daniel Bouton dejó el cargo de director general de Société Générale y fue sustituido en este cargo por Frédéric Oudea. Un año después, se vio obligado a dimitir de su cargo de presidente del consejo de administración del banco. El motivo de su salida fueron duras críticas de la prensa: Bouton fue acusado de que los altos directivos del banco bajo su control fomentaban transacciones financieras riesgosas realizadas por los empleados del banco.
A pesar del apoyo de la junta directiva, la presión sobre Bouton aumentó. Los accionistas del banco y muchos políticos franceses exigieron su dimisión. El presidente francés, Nicolas Sarkozy, también pidió la dimisión de Daniel Bouton después de que se conociera que, en el año y medio anterior al escándalo, el sistema informático de control interno de Société Générale emitió una advertencia 75 veces, es decir, cada vez que Jerome Kerviel realizaba transacciones no autorizadas, posibles violaciones. .
Inmediatamente después de que se descubrieron las pérdidas, Societe Generale creó una comisión especial para investigar las acciones del comerciante, que incluía miembros independientes de la junta directiva del banco y auditores PricewaterhouseCoopers. La comisión concluyó que el sistema de control interno del banco no era lo suficientemente eficaz. Esto hizo que el banco no pudiera evitar un fraude a tan gran escala. El informe afirma que "el personal del banco no realizó controles sistemáticos" de las actividades del comerciante y que el propio banco no tenía "un sistema de control que pudiera prevenir el fraude".
El informe sobre los resultados de la auditoría del comerciante indica que, tras los resultados de la investigación, se tomó la decisión de "reforzar significativamente el procedimiento de supervisión interna de las actividades de los empleados de Societe Generale". Esto se hará mediante una organización más estricta del trabajo de las distintas divisiones del banco y la coordinación de su interacción. También se tomarán medidas para rastrear y personalizar las operaciones comerciales de los empleados bancarios "reforzando el sistema de seguridad informática y desarrollando soluciones de alta tecnología para la identificación personal (biometría)".
Del libro Garantizar la seguridad de la información empresarial. autor Andrianov V.V.4.2.2. Tipología de incidentes La generalización de la práctica mundial nos permite identificar los siguientes tipos de incidentes de seguridad de la información que involucran al personal de la organización: - divulgación de información oficial; - falsificación de informes; - robo de activos financieros y materiales; - sabotaje
Del libro Pensión: procedimiento de cálculo y registro. autor Minaeva Lyubov Nikolaevna4.3.8. Investigación de incidentes Un incidente en el que está involucrado un empleado de una organización es una emergencia para la mayoría de las organizaciones. Por lo tanto, la forma en que se organiza una investigación depende en gran medida de la cultura corporativa existente en la organización. Pero puedes con confianza
Del libro Day Trading en el mercado Forex. Estrategias de ganancias por Lyn Ketty2.5. Ejemplos Consideremos algunas opciones para la asignación de pensiones laborales en caso de transferencia de documentos a los órganos territoriales del Fondo de Pensiones por correo: Ejemplo 1 Se envió una solicitud para la cesión de una pensión laboral de vejez al organismo territorial del fondo
Del libro La práctica de la gestión de recursos humanos. autor miguel armstrong3.5. Ejemplos Ejemplo 1 La experiencia laboral consta de períodos de trabajo desde el 15 de marzo de 1966 al 23 de mayo de 1967; del 15/09/1970 al 21/05/1987; del 01.01.1989 al 31.12.1989; del 04/09/1991 al 14/07/1996; del 15/07/1996 al 12/07/1998 y el servicio militar del 27/05/1967 al 09/06/1969 Calculemos la duración del servicio para evaluar los derechos de pensión.
Del libro del autor.4.4. Ejemplos Ejemplo 1 El ingeniero Sergeev A.P., nacido en 1950, solicitó una pensión de vejez en marzo de 2010. En 2010 cumplió 60 años. La duración total del servicio para evaluar los derechos de pensión al 1 de enero de 2002 es de 32 años, 5 meses y 18 días, incluidos 30 años antes de 1991.
Del libro del autor.6.3. Ejemplos Ejemplo 1 El gerente de ventas V.N. Sokolov trabajó bajo un contrato de trabajo desde el 1 de enero de 2010. El 1 de enero de 2013, muere a la edad de 25 años. Al mismo tiempo, todavía tiene padres sanos, una esposa sana y una hija de 3 años. En este caso, el derecho a recibir mano de obra.
Del libro del autor.7.4. Ejemplos Ejemplo 1 Gerente Vasiliev R.S., 60 años. La duración total del servicio según el libro de trabajo para la valoración de los derechos de pensión a partir del 1 de enero de 2002 es de 40 años. Los ingresos mensuales medios en 2000-2001, según datos contables personalizados, son de 4.000 rublos. Calcularemos y compararemos los montos de las pensiones según
Del libro del autor.8.3. Ejemplos Ejemplo 1 Un pensionado recibe una pensión de invalidez del grupo I. Del 20 de mayo al 5 de junio de 2009 se sometió a un nuevo examen en la BMSE y el 3 de junio de 2009 fue reconocido como discapacitado del grupo III. El grupo de discapacidad en este caso disminuyó. La parte básica de la pensión está sujeta a
Del libro del autor.10.4. Ejemplos Ejemplo 1 El fallecimiento de un pensionado se produjo el 28 de enero de 2009. La viuda del pensionado solicitó una pensión en febrero de 2009. No se estableció la convivencia de la viuda con el pensionado el día de su fallecimiento. En este caso de pensión, el organismo territorial de el fondo aceptado
Del libro del autor.14.7. Ejemplos Ejemplo 1 Koshkina V.N., que dependía de su difunto marido, cumplió 55 años 3 meses después de su muerte. Solicité una pensión después de 1 año de la fecha del fallecimiento de mi cónyuge. Según la legislación de pensiones, la pensión se asignará a partir de la fecha
Del libro del autor.17.5. Ejemplos Ejemplo 1 Un empresario individual emplea a cuatro personas bajo un contrato de trabajo: Moroz K.V. (n. 1978), Svetlova T. G. (n. 1968), Leonova T. N. (n. 1956) y Komarov S. N. (n. 1952). Supongamos que el salario mensual de cada uno de ellos es de 7.000 rublos.
Del libro del autor.Ejemplos Veamos algunos ejemplos de cómo funciona esta estrategia: 1. Gráfico de 15 minutos del EUR/USD en la Fig. 8.8. Según las reglas de esta estrategia, vemos que el EUR/USD cayó y cotiza por debajo de la media móvil de 20 días. Los precios continuaron cayendo, acercándose a 1,2800, que es
Del libro del autor.Ejemplos Estudiemos algunos ejemplos.1. En la Fig. La figura 8.22 muestra un gráfico de 15 minutos del USD/CAD. El alcance total del canal es de aproximadamente 30 puntos. De acuerdo con nuestra estrategia, colocamos órdenes de entrada 10 puntos por encima y por debajo del canal, es decir, en 1,2395 y 1,2349. Orden de compra ejecutada
Del libro del autor.Ejemplos Veamos algunos ejemplos de esta estrategia en acción.1. En la Fig. La Figura 8.25 muestra el gráfico diario del EUR/USD. El 27 de octubre de 2004, las medias móviles EUR/USD formaron un orden correcto y constante. Abrimos una posición cinco velas después del inicio de la formación en 1,2820.
A medida que aumenta el papel de TI en una empresa, también aumenta la necesidad de garantizar un buen nivel de servicio y garantizar la máxima disponibilidad de los servicios de TI. El usuario empresarial debería poder obtener soluciones a sus problemas si surgen lo más rápido posible y funcionan en cualquier momento. Implementación de procesos administracion de incidentes Y los problemas apuntan precisamente a esto. En este artículo describimos cómo se puede organizar el trabajo de un servicio de TI en el marco de administracion de incidentes y problemas. Esta descripción está basada en sugerencias de ITIL y las experiencias de nuestros clientes.
Lenguaje de incidentes y problemas.
ITIL Service Support es un modelo reconocido globalmente. Se basa en las mejores prácticas y se utiliza para guiar a las organizaciones de TI en el desarrollo de enfoques para la gestión de servicios. Este modelo es prometedor. También define elementos adicionales necesarios para el funcionamiento exitoso de una organización de TI como negocio de servicios. Proporciona un vocabulario técnico para las discusiones de la mesa de ayuda, define conceptos y resalta las diferencias entre diferentes actividades. Por ejemplo, las actividades requeridas para responder a las interrupciones del servicio y restaurarlas son diferentes de las actividades requeridas para encontrar y eliminar las causas de las interrupciones del servicio.
Incidentes
Incidente- cualquier evento que no forme parte de las operaciones estándar del servicio y cause, o pueda causar, una interrupción del servicio o una disminución en la calidad del servicio.
Ejemplos de incidentes son:
- El usuario no puede recibir correo electrónico
- La herramienta de monitoreo de red indica que el canal de comunicación pronto estará lleno
- El usuario siente que la aplicación se ralentiza.
Problemas
Problema— hay una causa desconocida para uno o más incidentes. Un problema puede dar lugar a varios incidentes.
Errores
Error conocido— hay un incidente o problema cuya causa se ha identificado y se ha desarrollado una solución para evitarlo o eliminarlo. Los errores pueden identificarse mediante el análisis de las quejas de los usuarios o el análisis de los sistemas.
Ejemplos de errores incluyen:
- Configuración incorrecta de la red informática
- La herramienta de monitoreo determina incorrectamente el estado del canal cuando el enrutador está ocupado
Correlación de conceptos administracion de incidentes y los problemas se muestran en la Figura 1. Los incidentes, los problemas y los errores conocidos están vinculados en una especie de ciclo de vida: los incidentes son a menudo indicadores de problemas ⇒ la identificación de la causa del problema identifica el error ⇒ los errores luego se corrigen sistemáticamente.
- existe una actividad para restablecer el servicio normal con mínimos retrasos e impacto en las operaciones comerciales, que es un servicio de restauración reactivo y enfocado a corto plazo.
Incluye:
- Detección y grabación de incidentes
- Clasificación y soporte inicial.
- Investigación y diagnóstico
- Solución y recuperación
- Clausura
- Propiedad, seguimiento, seguimiento y comunicación.
Gestión de problemas
Gestión de problemas — existen actividades para minimizar el impacto en el negocio de los problemas causados por errores en la infraestructura de TI, para evitar la recurrencia de incidentes asociados con dichos errores. La gestión de problemas identifica las causas de los problemas e identifica soluciones o soluciones.
La gestión de problemas incluye:
- control de problemas
- Control de errores
- Previniendo problemas
- Análisis de los principales problemas.
control de problemas
Propósito del control de problemas— encuentre la causa del problema siguiendo estos pasos:
- Identificar y registrar problemas
- Clasificación de problemas y priorización de sus soluciones.
- Investigación y diagnóstico de causas.
Control de errores
El control de errores garantiza que los problemas se corrijan mediante:
- Identificar y registrar errores conocidos
- Evaluar remedios y priorizarlos
- Registro para solución temporal en herramientas de soporte
- Cerrar problemas conocidos mediante la implementación de correcciones
- Supervisar los errores conocidos para determinar la necesidad de cambiar las prioridades.
Análisis del problema
Propósito del análisis del problema es mejorar los procesos administracion de incidentes y gestión de problemas. Lo que se consigue estudiando la calidad de los resultados de las actividades para eliminar problemas e incidencias importantes.
Roles organizacionales y distribución de responsabilidades.
La estructura de sistema de soporte más común es un modelo escalonado en el que se aplican niveles cada vez mayores de capacidades técnicas para resolver un incidente o problema. Las funciones y responsabilidades reales utilizadas en la implementación de un sistema de soporte por niveles pueden variar según el personal, la historia y las políticas de la organización en particular. Sin embargo, la siguiente descripción de un sistema de soporte escalonado es típica de muchas organizaciones.
Primer nivel de soporte
La organización (división) que representa el primer nivel de soporte generalmente se refiere a los servicios operativos. Como regla general, se llama servicio de despacho, centro de llamadas, mesa de servicio.
Roles. Dueño del proceso
El primer nivel de soporte garantiza que se establezca y mantenga un proceso eficiente, bien definido, ejecutado de manera consistente y medido apropiadamente. administracion de incidentes. Recibir y gestionar todos los asuntos de atención al cliente. El primer nivel de soporte es el único punto de contacto para escalar problemas de servicio y actúa como defensor del usuario final para garantizar que los problemas de servicio se resuelvan de manera oportuna.
Primera línea de apoyo
La organización de soporte de primer nivel hace el primer intento de resolver el problema de servicio informado por el usuario final.
Responsabilidades
- Se garantiza que la ficha de incidencia contiene una descripción precisa y suficientemente detallada del problema
- Se garantiza la elección correcta de la importancia/prioridad del incidente.
- Se determinan la naturaleza del problema, los contactos de los usuarios, el impacto comercial y el tiempo esperado de resolución.
Propiedad de cada incidente. Como defensor del usuario final, el primer nivel de soporte garantiza que cada incidente se resuelva exitosamente. Esto garantiza la resolución oportuna de problemas a través de:
- Desarrollar y gestionar un plan de acción para resolver el problema.
- Iniciar asignaciones de tareas específicas para el personal y los socios comerciales.
- Escalar el incidente si es necesario cuando el objetivo no se logra a tiempo
- Asegurar la comunicación interna de acuerdo con los objetivos del servicio.
- Proteger los intereses de los socios comerciales involucrados
El primer nivel de soporte utiliza una base de datos de gestión de problemas para hacer coincidir los incidentes con los errores conocidos y aplicar soluciones descubiertas previamente a los incidentes. El objetivo es resolver el 80 por ciento de las incidencias. Los incidentes restantes se transfieren (escalan) al segundo nivel.
Mejora continua del proceso de gestión de incidencias. Como propietario de un proceso determinado, el primer nivel de soporte garantiza que el proceso se mejore cuando sea necesario mediante:
- Evaluar la efectividad del proceso y los mecanismos de apoyo como informes, tipos de comunicación y formatos de mensajes, procedimientos de escalamiento.
- Desarrollo de informes y procedimientos específicos del departamento.
- Apoyar y mejorar las listas de comunicación y escalamiento.
- Participación en el proceso de análisis del problema.
Registro preciso de incidencias. El primer nivel de soporte garantiza que la información sobre el incidente se registre en el registro del sistema. Para ello debe haber:
Habilidades y destrezas
Las habilidades interpersonales son primordiales. El personal de soporte de primer nivel participa principalmente en la priorización y gestión de problemas. En este nivel de soporte, sólo se llevan a cabo investigaciones técnicas menores. Capacidad para aplicar soluciones “enlatadas”. El personal de primer nivel debe poder reconocer los síntomas, utilizar herramientas de búsqueda para descubrir soluciones desarrolladas previamente y ayudar a los usuarios finales a implementar dichas soluciones.
Segundo nivel de soporte
Este nivel también suele referirse a los servicios operativos.
Roles
- Investigación del incidente. El segundo nivel de soporte investiga, diagnostica y resuelve la mayoría de los incidentes que no se resuelven en el primer nivel. Estos incidentes tienden a indicar nuevos problemas.
- Dueño del proceso de gestión de problemas. El segundo nivel de soporte garantiza que exista un proceso de gestión de problemas eficaz y bien definido.
- Gestión proactiva de la infraestructura. El segundo nivel de soporte utiliza herramientas y procesos para garantizar que los problemas se identifiquen y resuelvan antes de que ocurran incidentes.
Responsabilidades
- Resolución de incidencias remitidas desde el primer nivel. Si se espera que el primer nivel de soporte resuelva el 80% de los incidentes, entonces se espera que el segundo nivel de soporte resuelva el 75% de los incidentes que le remite el primer nivel, es decir, el 15% del número de incidentes reportados. El resto de incidencias se trasladan al tercer nivel.
- Determinar las causas de los problemas. El segundo nivel de soporte identifica las causas de los problemas y sugiere soluciones o soluciones. Participan y gestionan otros recursos según sea necesario para determinar las causas. La resolución de problemas se eleva al tercer nivel cuando la causa es un problema arquitectónico o técnico que excede su nivel de habilidad.
- Asegúrese de que se resuelvan las correcciones y los problemas. El segundo nivel de apoyo garantiza que se inicien proyectos dentro de las organizaciones de desarrollo para implementar planes para resolver problemas conocidos. Se aseguran de que las soluciones encontradas sean documentadas, comunicadas al personal de primer nivel e implementadas en herramientas.
- Monitoreo constante de la infraestructura. El segundo nivel de soporte intenta identificar problemas antes de que ocurran incidentes monitoreando los componentes de la infraestructura y tomando medidas correctivas cuando se detectan defectos o tendencias erróneas.
- Análisis proactivo de tendencias de incidentes. Los incidentes que ya han ocurrido se examinan para determinar si indican problemas que deben corregirse para evitar que causen más incidentes. Los incidentes que están cerrados y no asignados a problemas conocidos se examinan en busca de problemas potenciales.
- Mejora continua del proceso de gestión de problemas. Como propietario del proceso de gestión de problemas, el segundo nivel de soporte garantiza que el proceso y las capacidades existentes sean adecuados y los mejora cuando sea necesario. Llevan a cabo sesiones de análisis de problemas para identificar lecciones aprendidas y garantizar que los controles de procesos, como reuniones e informes, sean adecuados.
Habilidades y destrezas
- Técnicamente competente con habilidades de comunicación razonables. El personal de soporte de segundo nivel debe tener una variedad de habilidades técnicas en todas las tecnologías admitidas, incluidas redes, servidores y aplicaciones. Un déficit común en las organizaciones de segundo nivel es el conocimiento de los sistemas operativos y las aplicaciones. No debería haber una brecha significativa entre las organizaciones de segundo y tercer nivel. Algunos empleados de segundo nivel deben estar tan calificados como los empleados de tercer nivel.
- Conocimiento de redes, servidores y aplicaciones. Las organizaciones de nivel 2 deben poder resolver incidentes y problemas en toda la gama de tecnologías utilizadas dentro de la empresa.
Tercer nivel de soporte
Este nivel de soporte generalmente cae dentro del equipo de desarrollo de aplicaciones e infraestructura de red.
Roles
- Planificación y diseño de infraestructura TI. Normalmente, el equipo de soporte de tercer nivel desempeña un papel pequeño en administracion de incidentes y gestión de problemas, ya que estas organizaciones se ocupan principalmente de la planificación y el diseño de la infraestructura de TI. En esta capacidad, su objetivo es implementar una infraestructura libre de defectos que no sea fuente de problemas e incidentes.
- La última frontera de la escalada. Si el incidente o problema supera las capacidades del equipo de soporte de segundo nivel, entonces el equipo de soporte de tercer nivel asume la responsabilidad de encontrar una solución.
Responsabilidades
- Resolver incidencias remitidas desde el segundo nivel. Dado que la mayoría de los incidentes son causados por errores conocidos, muy pocos incidentes (5%) pasan del segundo nivel al tercero. El tercer nivel se encarga de resolver todas las incidencias que le lleguen.
- Participar en actividades de gestión de problemas. El tercer nivel de soporte está involucrado en encontrar las causas, soluciones y eliminación de errores.
- Implementación de medidas para eliminar errores de la infraestructura. El tercer nivel tiene un papel importante en la planificación, diseño e implementación de proyectos para abordar las deficiencias de infraestructura. La implementación de estos proyectos debe coordinarse con el trabajo regular de desarrollo de infraestructura para lograr el equilibrio adecuado.
Habilidades y destrezas
- Expertos en sus respectivos campos. Los equipos de nivel 3 deben ser los expertos que planifican y diseñan la infraestructura de TI.
Procesos
Hay tres procesos principales asociados con administracion de incidentes y gestión de problemas:
- proceso de gestión de incidentes
- proceso de control de problemas
- proceso de control de errores
Estos procesos centrales están presentes en casi todas las organizaciones avanzadas, aunque pueden tener otros nombres.
Proceso de gestión de incidentes
Este proceso está enfocado a restablecer el servicio interrumpido lo más rápido posible. En la Tabla 1 se muestran los principales parámetros de este proceso, y en la Figura 1 se muestra un diagrama de su funcionamiento.
|
Parámetro de proceso |
Descripción |
|---|---|
|
Objetivo |
|
|
Dueño |
|
|
|
|
|
|
Parámetros numéricos típicos |
|
Figura 1. Modelo de proceso
El proceso de control de problemas se centra en priorizar, asignar y monitorear los esfuerzos para determinar las causas de los problemas y cómo resolverlos de manera temporal o permanente. Este proceso puede compararse con la gestión de carteras de proyectos, donde cada problema es un proyecto que debe gestionarse dentro de una cartera de proyectos similares. Los principales parámetros del proyecto de control de problemas se muestran en la Tabla 2.
|
Parámetro de proceso |
Descripción |
|---|---|
|
Objetivo |
|
|
Dueño | |
|
|
|
|
|
Parámetros numéricos típicos |
|
Los aportes a un proceso pueden provenir de múltiples fuentes. Normalmente, los incidentes de alta gravedad se derivan automáticamente al proceso de gestión de problemas. En organizaciones con un segundo nivel de soporte sólido, los incidentes escalados al tercer nivel de soporte también se envían de manera rutinaria al proceso de control de problemas. Finalmente, la reunión diaria puede redirigir determinadas incidencias a los procesos de control de problemas. El proceso que implementa el control de problemas se muestra en la Figura 2.

Figura 2. Modelo de proceso de control de problemas
El objetivo del proceso de control de problemas es determinar las causas. La composición de los participantes en el análisis de la causa y el tiempo necesario para completar dicho análisis dependen del problema en sí. Las siguientes afirmaciones pueden considerarse correctas:
- Si tiene suficientes problemas, asigne un equipo permanente. De lo contrario, cree un equipo cuando surja un problema, de la misma manera que se forma un equipo para un proyecto;
- El equipo casi siempre debe tener experiencia y conocimientos interdisciplinarios. Y esto, por supuesto, depende de la naturaleza del problema en cuestión;
- Se debe dar una estimación del tiempo para determinar la causa (desarrollar un plan de proyecto) cuando ocurre el problema. El progreso del equipo debe medirse en función de esta evaluación.
Una vez que se han asignado y priorizado los recursos, la mecánica real para determinar la causa puede adoptar muchas formas. Han demostrado su eficacia métodos de búsqueda de causas como el análisis de Kepner y Trego, los diagramas de Ishikawa, los diagramas de Pareto, etc.
El monitoreo de errores proporciona documentación de métodos para superar fallas y alertar al personal de soporte sobre ellas (métodos). Esto también incluye mantener contacto con otras organizaciones técnicas y de desarrollo, lo que también ayuda a identificar errores. Además, el control de errores influye en los desarrolladores para que implementen correcciones de errores conocidos. La Tabla 3 muestra los principales parámetros del proceso de control de errores. La Figura 3 muestra un modelo del proceso de control de errores.
|
Parámetro de proceso |
Descripción |
|---|---|
|
Objetivo |
|
|
Dueño |
|
|
|
|
|
|
Parámetros numéricos típicos |
|

Figura 3. Modelo de proceso de control de errores
Interacciones
Normalmente, las interacciones en este proceso adoptan una de dos formas. Estos son mensajes sobre el estado de un incidente o problema, que se proporcionan a varios grupos y/o individuos según reglas y plantillas aprobadas, o mensajes sobre solicitudes que requieren que el destinatario tome ciertas acciones, que generalmente contienen, además de la solicitud/demanda real, un enlace al incidente, número de teléfono del usuario u otro enlace al mismo.
Muchas empresas confían en las capacidades de mensajería automatizada que proporciona el software. Dichos mensajes se envían de acuerdo con regulaciones estrictas para mantener la escalada. Los mensajes de estado de los sistemas de software generalmente se generan a partir de datos ingresados en los campos de una tarjeta de incidente. Por lo tanto, dichos mensajes suelen estar incompletos y desordenados debido al hecho de que los campos utilizados para crear mensajes automatizados pueden actualizarse de manera irregular con información oportuna o completarse automáticamente mediante software de monitoreo utilizando la jerga de mensajes de error.
Para corregir estas deficiencias, las capacidades de comunicación automática se complementan, especialmente en el caso de incidentes de alta gravedad, con mensajes manuales.
Escalada
Mecanismo de escalada Ayuda a resolver un incidente de manera oportuna aumentando la capacidad del personal, el nivel de esfuerzo y la prioridad enfocada en resolver el incidente. Las mejores organizaciones tienen rutas de escalada bien definidas con cronogramas y responsabilidades claramente definidos en cada paso. Usan medios administracion de incidentes transferir automáticamente la responsabilidad a niveles crecientes de soporte de acuerdo con las limitaciones de tiempo y la complejidad.
Los plazos y las responsabilidades para la escalada varían mucho según la organización, la industria y el nivel de complejidad de los problemas. En las organizaciones líderes, se mantienen conversaciones con los usuarios finales para determinar los plazos adecuados y la escalada de responsabilidades. El resultado de dichas negociaciones se implementa en forma de acuerdos de nivel de servicio, herramientas automatizadas, listas y plantillas.
Escalada funcional
Escalada funcional Hay una escalada del incidente a un nivel superior de soporte cuando el conocimiento o la experiencia son insuficientes o el intervalo de tiempo acordado ha expirado. Las organizaciones avanzadas definen una matriz de niveles de gravedad en función del grado de impacto empresarial, el plazo para resolver el incidente y los intervalos de tiempo en los que el incidente debe escalarse a un equipo más avanzado. La Tabla 4 representa dicha matriz.
En la mayoría de las organizaciones, los grupos de apoyo del primer y segundo nivel se centran en la operación de la infraestructura existente, mientras que el tercer nivel de apoyo suele ser proporcionado por grupos que son responsables de planificar el desarrollo de la infraestructura y su diseño. Por lo tanto, es fundamental una planificación cuidadosa de cómo se transferirá funcionalmente la responsabilidad al tercer nivel.
|
Nivel de incidente |
Descripción |
Plazo para la decisión |
Primer nivel |
Primera escalada |
Segunda escalada |
Tercera escalada |
|---|---|---|---|---|---|---|
|
Más de 50 usuarios no pueden realizar transacciones comerciales |
1er nivel de soporte |
2do nivel de soporte |
3er nivel de soporte |
1er gerente Reunión de emergencia |
||
|
De 10 a 49 usuarios no pueden realizar transacciones comerciales |
1er nivel de soporte |
2do nivel de soporte |
3er nivel de soporte |
1er gerente Reunión de emergencia |
||
|
De 1 a 9 usuarios no pueden realizar transacciones comerciales |
1er nivel de soporte |
2do nivel de soporte |
3er nivel de soporte |
1er gerente |
En organizaciones avanzadas, generalmente se define un buscapersonas de servicio. El gerente de cada grupo de tecnología es responsable de preparar un cronograma de manejo de llamadas para dichas llamadas a buscapersonas y garantizar que las llamadas sean atendidas en todo momento. Además, se debe definir un procedimiento de escalamiento jerárquico (gerencial) para cada grupo tecnológico. Normalmente, el gerente de línea del equipo de tercer nivel es el primer líder en la escalada.
Escalada jerárquica
Para garantizar que a un incidente se le dé la prioridad adecuada y se asignen los recursos necesarios antes de que se exceda el plazo de resolución, la escalada jerárquica involucra a la administración en el proceso. La escalada jerárquica se puede realizar en cualquier nivel de soporte. En la Tabla 4, el escalamiento jerárquico ocurre en el tercer paso de escalamiento para problemas de todos los niveles de gravedad.
En organizaciones avanzadas, el escalamiento a la gerencia ocurre automáticamente según un procedimiento predefinido basado en la gravedad del problema. Una vez que se ha producido una escalada, se espera que el gerente apropiado gestione activamente la resolución de problemas y se convierta en el único punto de contacto para las comunicaciones de estado.
Informes y mejora de procesos.
Los informes estadísticos en organizaciones líderes se utilizan para el seguimiento, la mejora continua de los procesos y el análisis de los indicadores de desempeño frente al nivel de servicio acordado con los clientes.
Para control de procesos administracion de incidentes y la gestión de problemas puede, por ejemplo, utilizar informes que contengan los valores de los siguientes parámetros:
- Número de tarjetas de incidentes abiertas actualmente, desglosadas por nivel de importancia, tiempo invertido y grupos de responsabilidad
- Número de tarjetas con problemas actualmente abiertas (cuya causa aún no se ha identificado)
Dichos informes permiten a los gerentes tomar decisiones sobre la asignación de recursos y la dirección de los esfuerzos del personal. Uso regular de parámetros de tipo:
- Tiempo promedio de procesamiento de tarjetas en cada nivel
- La cantidad de tarjetas aprobadas y resueltas en cada nivel puede ayudar a identificar debilidades en la infraestructura de TI.
Finalmente, un conjunto vital de informes, como:
- Porcentaje de incidentes resueltos en un plazo determinado
- El tiempo promedio para restaurar el servicio permite a las organizaciones de TI interactuar con sus consumidores y correlacionar el nivel de rendimiento alcanzado con el nivel de servicio objetivo.
Conclusión
Desarrollo de procesos y procedimientos administracion de incidentes Lo llevan a cabo muchas organizaciones, pero no todas hacen lo mismo para la gestión de problemas. A menudo esto se debe a una falta de comprensión clara de las características de estas dos actividades. Es la actividad más sencilla de entender porque simplemente crea un mecanismo para responder a las interrupciones del servicio. Dado que “la rueda que chirría siempre tendrá la grasa”, la gestión de incidentes está evolucionando con bastante rapidez. Sin embargo, a menudo hay menos oportunidades para desarrollar la gestión de problemas.
La gestión de problemas se parece más a la gestión de una cartera de proyectos, cada uno con el objetivo de identificar la causa de un problema. Los incidentes son a menudo el primer indicador de un problema y, una vez que se enfrenta a un incidente, una organización debe contar con un proceso y procedimientos para determinar la causa.
Siguiendo con la analogía de la cartera de proyectos, la organización de gestión de problemas debe desarrollar un criterio para identificar los problemas que deben investigarse para determinar las causas, de la misma manera que lo hace con el criterio de decisión para elegir un nuevo proyecto. Los temas que no se investigan continúan siendo monitoreados para futuras investigaciones. Una vez que se encuentra una causa y se desarrolla una solución, la organización realiza un seguimiento del progreso en la implementación de la solución.
La causa principal de un incidente de seguridad de la información es la capacidad potencial de un atacante de obtener privilegios irrazonables para acceder a los activos de una organización. Evaluar el riesgo de tal oportunidad y tomar la decisión correcta de proteger es la tarea principal del equipo de respuesta.
Cada riesgo debe priorizarse y tratarse de acuerdo con la política de evaluación de riesgos de la organización. La evaluación de riesgos se considera un proceso continuo cuyo objetivo es lograr un nivel aceptable de protección; en otras palabras, se deben implementar medidas suficientes para proteger el activo contra un uso irrazonable o no autorizado. La evaluación de riesgos contribuye a la clasificación de activos. En la gran mayoría de los casos, los activos que son críticos desde el punto de vista del riesgo también lo son para el negocio de la organización.
Los especialistas del equipo de respuesta analizan las amenazas y ayudan a mantener actualizado el modelo de intrusión adoptado por el servicio de seguridad de la información de la organización.
Para que el equipo de respuesta funcione eficazmente, la organización debe contar con procedimientos para describir los procesos de funcionamiento de las unidades. Se debe prestar especial atención a completar la base de documentos del servicio de seguridad de la información.
Detección y análisis de incidentes de seguridad de la información
Los incidentes de seguridad de la información pueden tener diferentes orígenes. Idealmente, una organización debería estar preparada para cualquier manifestación de actividad maliciosa. En la práctica esto no es factible.
La función de respuesta debe clasificar y describir cada incidente que ocurre en la organización, así como clasificar y describir los posibles incidentes que se asumieron con base en el análisis de riesgos.
Para ampliar el tesauro sobre posibles amenazas y posibles incidentes asociados a ellas, una buena práctica es utilizar fuentes abiertas en Internet constantemente actualizadas.
Señales de un incidente de seguridad de la información
La suposición de que ha ocurrido un incidente de seguridad de la información en una organización debe basarse en tres factores principales:
- Los mensajes de incidentes de seguridad de la información se reciben simultáneamente desde varias fuentes (usuarios, IDS, archivos de registro)
- Evento repetido múltiple de señal IDS
- El análisis de los archivos de registro del sistema automatizado proporciona una base para que los administradores del sistema concluyan que puede ocurrir un incidente.
En general, las señales de un incidente se dividen en dos categorías principales: informes de que un incidente está ocurriendo actualmente e informes de que puede ocurrir un incidente en el futuro cercano. Las siguientes son algunas señales de que está ocurriendo un evento:
- IDS detecta desbordamiento del buffer
- notificación del programa antivirus
- Fallo de la interfaz WEB
- Los usuarios informan velocidades extremadamente lentas al intentar acceder a Internet
- el administrador del sistema detecta la presencia de archivos con nombres ilegibles
- Los usuarios reportan muchos mensajes duplicados en sus bandejas de entrada
- el host escribe en el registro de auditoría sobre el cambio de configuración
- la aplicación registra múltiples intentos fallidos de autorización en el archivo de registro
- el administrador de la red detecta un fuerte aumento en el tráfico de la red, etc.
Ejemplos de eventos que pueden servir como fuentes de seguridad de la información incluyen:
- archivos de registro del servidor registran escaneos de puertos
- anuncio en los medios sobre la aparición de un nuevo tipo de exploit
- una declaración abierta de delincuentes informáticos declarando la guerra a su organización, etc.
Análisis de incidentes de seguridad de la información.
El incidente no es un hecho evidente; al contrario, los atacantes están tratando de hacer todo lo posible para no dejar rastros de sus actividades en el sistema. Los signos de un incidente incluyen un cambio menor en el archivo de configuración del servidor o, a primera vista, una queja estándar de un usuario de correo electrónico. Tomar una decisión sobre la ocurrencia de un incidente depende en gran medida de la competencia de los expertos del equipo de respuesta. Es necesario distinguir entre un error accidental del operador y un impacto malicioso y dirigido a un sistema de información. El hecho de que un incidente de seguridad de la información se maneje “de brazos cruzados” también es un incidente de seguridad de la información, ya que distrae a los expertos del equipo de respuesta de los problemas urgentes. La dirección de la organización debe prestar atención a esta circunstancia y proporcionar a los expertos del equipo de respuesta cierta libertad de acción.
La elaboración de matrices de diagnóstico sirve para visualizar los resultados del análisis de los eventos ocurridos en el sistema de información. La matriz se forma a partir de filas de posibles signos de un incidente y columnas de tipos de incidentes. La intersección da una evaluación del evento en la escala de prioridad de “alta”, “media”, “baja”. La matriz de diagnóstico tiene como objetivo documentar el flujo de conclusiones lógicas de los expertos en el proceso de toma de decisiones y, junto con otros documentos, sirve como evidencia de la investigación del incidente.
Documentar un incidente de seguridad de la información
Es necesario documentar los eventos de un incidente de seguridad de la información para recopilar y posteriormente consolidar la evidencia de la investigación. Todos los hechos y pruebas de influencia maliciosa deben documentarse. Se hace una distinción entre evidencia tecnológica y evidencia operativa de impacto. La evidencia tecnológica incluye información obtenida de medios técnicos de recopilación y análisis de datos (sniffers, IDS); la evidencia operativa incluye datos o evidencia recopilada durante una encuesta al personal, evidencia de llamadas al servicio de atención al cliente, llamadas al centro de llamadas.
Una práctica típica es mantener un registro de investigación de incidentes, que no tiene un formulario estándar y es desarrollado por el equipo de respuesta. Las posiciones clave de dichas revistas pueden ser:
- estado actual de la investigación
- descripción del incidente
- Acciones realizadas por el equipo de respuesta durante el procesamiento del incidente.
- lista de actores de la investigación con una descripción de sus funciones y porcentaje de empleo en el procedimiento de investigación
- Lista de pruebas (con indicación obligatoria de las fuentes) recopiladas durante el procesamiento del incidente.
tamaño de fuente
NORMA NACIONAL DE LA FEDERACIÓN DE RUSIA - TECNOLOGÍA DE LA INFORMACIÓN - MÉTODOS Y MEDIOS DE SEGURIDAD - GESTIÓN... Relevante en 2018
6 Ejemplos de incidentes de seguridad de la información y sus causas
Los incidentes de seguridad de la información pueden ser intencionales o accidentales (por ejemplo, el resultado de algún error humano o fenómeno natural) y causados por medios tanto técnicos como no técnicos. Sus consecuencias pueden incluir eventos tales como divulgación o modificación no autorizada de información, su destrucción u otros eventos que la hagan inaccesible, así como daño o robo de los activos de la organización. Los incidentes de seguridad de la información que no se informan pero que han sido identificados como incidentes no se pueden investigar y no se pueden aplicar medidas de protección para evitar que se repitan.
A continuación se muestran algunos ejemplos de incidentes de seguridad de la información y sus causas, que se proporcionan únicamente con fines de aclaración. Es importante señalar que estos ejemplos no son exhaustivos.
6.1 Denegación de servicio
La denegación de servicio es una categoría amplia de incidentes de seguridad de la información que tienen una cosa en común.
Estos incidentes de seguridad de la información provocan la imposibilidad de que los sistemas, servicios o redes sigan funcionando con el mismo rendimiento, en la mayoría de los casos con una denegación total de acceso a los usuarios autorizados.
Hay dos tipos principales de incidentes de seguridad de la información asociados con la denegación de servicio causada por medios técnicos: destrucción de recursos y agotamiento de recursos.
Algunos ejemplos típicos de incidentes intencionales de "denegación de servicio" de seguridad de la información técnica son:
Sondear direcciones de transmisión de red para llenar completamente el ancho de banda de la red con tráfico de mensajes de respuesta;
Transmitir datos en un formato no deseado a un sistema, servicio o red en un intento de interrumpir o perturbar su funcionamiento normal;
Abrir múltiples sesiones simultáneamente a un sistema, servicio o red en particular en un intento de agotar sus recursos (es decir, ralentizarlo, bloquearlo o destruirlo).
Algunos incidentes de "denegación de servicio" de seguridad de la información técnica pueden ocurrir accidentalmente, por ejemplo, como resultado de un error de configuración realizado por un operador o debido a la incompatibilidad del software de la aplicación, mientras que otros pueden ser intencionales. Algunos incidentes de seguridad de la información técnica, "denegación de servicio", se inician intencionalmente con el objetivo de destruir un sistema, un servicio y reducir el rendimiento de la red, mientras que otros son simplemente subproductos de otras actividades maliciosas.
Por ejemplo, algunos de los métodos de identificación y escaneo encubierto más comunes pueden provocar la destrucción completa de sistemas o servicios antiguos o mal configurados cuando se escanean. Cabe señalar que muchos incidentes técnicos de denegación de servicio intencional suelen iniciarse de forma anónima (es decir, se desconoce el origen del ataque) porque el atacante normalmente no tiene conocimiento de la red o el sistema que está siendo atacado.
Los incidentes de "denegación de servicio" de SI creados por medios no técnicos y que conducen a la pérdida de información, servicio y (o) dispositivos de procesamiento de información pueden deberse, por ejemplo, a los siguientes factores:
Violaciones de los sistemas de seguridad física que conduzcan a robo, daño intencional o destrucción de equipos;
Daño accidental al equipo y (o) su ubicación por incendio o agua/inundación;
Condiciones ambientales extremas, como altas temperaturas (por falla del sistema de aire acondicionado);
Funcionamiento incorrecto o sobrecarga del sistema;
Cambios incontrolados en el sistema;
Mal funcionamiento del software o hardware.
6.2 Recopilación de información
En términos generales, los incidentes de seguridad de la información "recopilación de información" implican acciones relacionadas con la identificación de posibles objetivos de ataque y la obtención de una comprensión de los servicios que se ejecutan en los objetivos de ataque identificados. Estos incidentes de seguridad de la información requieren un reconocimiento para determinar:
La presencia de un objetivo, obteniendo una comprensión de la topología de la red que lo rodea y con quién este objetivo suele estar conectado mediante el intercambio de información;
Vulnerabilidades potenciales del objetivo o de su entorno de red circundante inmediato que pueden aprovecharse para realizar ataques.
Ejemplos típicos de ataques destinados a recopilar información por medios técnicos son:
Restablecer los registros DNS (Sistema de nombres de dominio) para el dominio de Internet de destino (transferencia de zona DNS);
Enviar solicitudes de prueba a direcciones de red aleatorias para encontrar sistemas que funcionen;
Sondear el sistema para identificar (por ejemplo, mediante suma de comprobación de archivos) el sistema operativo host;
Escanear los puertos de red disponibles para el sistema de protocolo de transferencia de archivos con el fin de identificar los servicios correspondientes (por ejemplo, correo electrónico, FTP, red, etc.) y las versiones de software de estos servicios;
Escanear uno o más servicios con vulnerabilidades conocidas en un rango de direcciones de red (escaneo horizontal).
En algunos casos, la recopilación de información técnica se expande hacia el acceso no autorizado si, por ejemplo, un atacante intenta obtener acceso no autorizado mientras busca una vulnerabilidad. Esto generalmente se lleva a cabo mediante herramientas de piratería automatizadas que no solo buscan vulnerabilidades, sino que también intentan explotar automáticamente sistemas, servicios y (o) redes vulnerables.
Los incidentes de recopilación de inteligencia creados por medios no técnicos dan como resultado:
Divulgación o modificación directa o indirecta de información;
Robo de propiedad intelectual almacenada en formato electrónico;
Violación de registros, por ejemplo, al registrar cuentas;
Uso indebido de los sistemas de información (por ejemplo, en violación de la ley o la política de la organización).
Los incidentes pueden deberse, por ejemplo, a los siguientes factores:
Violaciones de la protección de la seguridad física que conducen al acceso no autorizado a la información y al robo de dispositivos de almacenamiento que contienen datos confidenciales, como claves de cifrado;
Sistemas operativos deficientes o mal configurados debido a cambios incontrolados en el sistema o mal funcionamiento del software o hardware, lo que resulta en que personal de la organización o personal no autorizado acceda a la información sin autorización.
6.3 Acceso no autorizado
El acceso no autorizado como tipo de incidencia incluye aquellas que no están incluidas en los dos primeros tipos. Principalmente este tipo de incidentes consiste en intentos no autorizados de acceso a un sistema o uso indebido de un sistema, servicio o red. Algunos ejemplos de acceso no autorizado por medios técnicos incluyen:
Intenta extraer archivos con contraseñas;
Ataques de desbordamiento de búfer para obtener acceso privilegiado (por ejemplo, a nivel de administrador del sistema) a la red;
Explotar las vulnerabilidades del protocolo para interceptar conexiones o desviar conexiones de red legítimas;
Intenta aumentar los privilegios de acceso a recursos o información más allá de los que legítimamente posee un usuario o administrador.
Los incidentes de acceso no autorizado creados por medios no técnicos que resulten en divulgación o modificación directa o indirecta de información, violaciones contables o uso indebido de los sistemas de información pueden ser causados por los siguientes factores:
Destrucción de dispositivos de protección física con posterior acceso no autorizado a la información;
Configuración fallida y/o incorrecta del sistema operativo debido a cambios incontrolados en el sistema o mal funcionamiento del software o hardware que lleven a resultados similares a los descritos en el último párrafo del 6.2.